前言
考完研之后比较闲,正好再聊聊这个话题,23年的时候我写了一篇关于预编译与sql注入的文章,在博客上浏览量还蛮高的,不过现在回头看感觉写的还是太简单了,这次我们再写的深入一点再谈谈这个问题。在上次的文章里,我提到,因为预编译的时候会给参数自动带上引号,所以导致有些位置的执行会报错,因此有些位置不能进行预编译。
你有没有好奇一个问题,为什么使用预编译的时候会导致参数带上引号,而且为什么大伙似乎都约定俗成,认为有些位置没法预编译就没法预编译吧,也放任不管了,即使预编译这个技术不是为了防护sql注入而提出的,为什么安全界里不专门提出一个针对sql防御的安全预编译技术呢,如果把预编译当作守护代码安全的一圈城墙,没法被预编译的位置的出现相当于这个城墙修了一半就不修了,那么你现在觉得这种防御还有价值吗?我认为是没有的,对于一个防护技术而言,只有安全和不安全之分,从这个角度看,我认为预编译在防御sql注入上完全是一个不合格的技术,那就让我们深入底层,研究研究为什么为出现这种情况。
预编译的缺陷
翻开这个不支持中文的mysql官网,这里提到了mysql对于预编译的核心设计思想:

MySQL 5.7 提供了对服务器端预处理语句的支持。此支持利用了高效的客户端/服务器二进制协议。使用带有占位符的预处理语句作为参数值具有以下好处:
- 每次执行语句时解析语句的开销更少。通常,数据库应用程序会处理大量几乎相同的语句,只会更改子句中的文字或变量值,例如查询和删除的 WHERE、更新的 SET 和插入的 VALUES。
- 防止 SQL 注入攻击。参数值可以包含未转义的 SQL 引号和分隔符。
可以看到和我之前说的差不多,首先,最主要的作用是为了减少数据库处理这些几乎相同语句的负担,其次才是防止sql注入,因为使用了预编译时参数值里可以包含未转义的SQL引号和分隔符。所以正是出于为了可以让参数值里可以包含未转义的符号,才让mysql默认给所有参数都打上了引号吗?

带着这样的疑问我接着往下看。
mysql里把预编译的查询分为两个阶段——prepare和execute,prepare的用法如下:
PREPARE stmt_name FROM preparable_stmtPREPARE 语句准备 SQL 语句并为其分配一个名称 stmt_name,以便稍后引用该语句。使用 EXECUTE 执行准备好的语句,并使用 DEALLOCATE PREPARE 释放该语句,语句名称不区分大小写。preparable_stmt 是包含 SQL 语句文本的字符串文字或用户变量。文本必须表示单个语句,而不是多个语句。
在语句中,? 字符可用作参数标记,以指示稍后执行查询时数据值要绑定到查询的位置。? 字符不应括在引号中,即使您打算将它们绑定到字符串值。参数标记只能用于应出现数据值的位置,而不能用于 SQL 关键字、标识符等。
这里就很有趣了,因为mysql明确指出,参数标记只能用于应出现数据值的位置而不能用于关键字,预编译主要用于绑定数据值,而 SQL 结构部分(结构化查询部分,如表名、列名、关键字等)不能使用占位符绑定。
预编译的执行流程是
- SQL 解析阶段:数据库服务器解析 SQL 语句,检查语法,创建执行计划,并为占位符留出位置。
- 绑定参数:执行时,数据库将用户提供的数据填充到预留的位置,执行查询。
比如对于语句
$stmt = $db->prepare("SELECT * FROM users WHERE username = :username");
$stmt->bindParam(':username', $username);
$stmt->execute();在解析阶段,数据库已经知道 username = ? 的 SQL 结构,不管 :username 的值是什么,都不会影响 SQL 结构本身,而查询优化器可以复用这个查询的执行计划,提高性能并防止 SQL 注入。
如果允许预编译绑定列名或表名,那么SQL结构部分会影响查询计划,比如下面的代码
$stmt = $db->prepare("SELECT * FROM users ORDER BY :column");
$stmt->bindParam(':column', $column);
$stmt->execute();首先,这样的写法会导致查询优化失败,数据库的查询优化器在预编译阶段无法确定 ORDER BY :column 具体会如何执行,不同列索引可能导致不同的查询计划,其次这样会导致无法复用执行计划,如果 :column 可能是 id、username、email,不同列的索引和排序方式不同,数据库必须为每个不同的列生成新的执行计划,失去了预编译的优势,因此预编译绑定的值始终是数据值,不会影响 SQL 结构。
但这是预编译的问题又不是我的问题,你们设计预编译的时候难道就真的不能考虑到这些被不能被预编译的位置吗?

比如拿典中典的order by为例,如果不使用预编译的写法是:
<?php
$column = $_POST['column']; // 需要排序的列名
try {
$db = new PDO("mysql:host=localhost;dbname=test", "root", "root");
$db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
// 手动拼接 SQL
$sql = "SELECT * FROM test ORDER BY $column";
// 直接执行 SQL 语句(不使用预编译)
$result = $db->query($sql)->fetchAll(PDO::FETCH_ASSOC);
var_dump($result);
} catch (PDOException $e) {
echo "数据库错误: " . $e->getMessage();
}
$db = null;这里现在显然是存在注入的,比如我们post一个
column=password ;INSERT INTO test (id, username, password) VALUES (4, '5', '6');现在数据库的结果是,确实被注入了一条数据
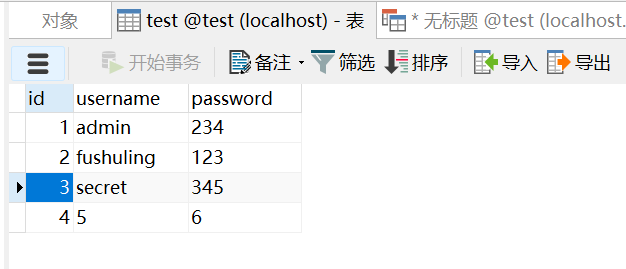
我们把这行数据删了,用预编译的写法写一个测试代码
<?php
$id = $_POST['id'];
$db = new PDO("mysql:host=localhost;dbname=test", "root", "root");
$db->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$stmt = $db->prepare("SELECT password FROM test where id= :id");
$stmt->bindParam(':id', $id);
$stmt->execute();
$result = $stmt->fetchAll(PDO::FETCH_ASSOC);
var_dump($result);
$db = null;首先,这样的写法确实是能防御sql注入,比如下面是一个典型的联合注入

但如果我们输入poc,注入会失败,日志里的执行结果为:
2025-03-28T12:57:23.353790Z 80 Prepare SELECT password FROM test where id= ?
2025-03-28T12:57:23.353833Z 80 Execute SELECT password FROM test where id= '2 union select password from test where id =1'
2025-03-28T12:57:23.354292Z 80 Close stmt
2025-03-28T12:57:23.354317Z 80 Quit 如果我们改一下代码,把参数绑定到列名上:
<?php
$id = $_POST['id'];
$db = new PDO("mysql:host=localhost;dbname=test", "root", "root");
$db->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$stmt = $db->prepare("SELECT password FROM test order by :id");
$stmt->bindParam(':id', $id);
$stmt->execute();
$result = $stmt->fetchAll(PDO::FETCH_ASSOC);
var_dump($result);
$db = null;这时我们再post一个id,日志里执行结果为:
2025-03-28T12:59:24.079954Z 85 Prepare SELECT password FROM test order by ?
2025-03-28T12:59:24.080039Z 85 Execute SELECT password FROM test order by 'id'
2025-03-28T12:59:24.080601Z 85 Close stmt
2025-03-28T12:59:24.080633Z 85 Quit 首先,因为加了引号所以order by这次排序其实执行结果错了,这里暂且按下不表,这时如果我们想post一个poc,比如id;INSERT INTO test (id, username, password) VALUES (4, '5', '6');,数据库日志中的执行结果为:
2025-03-28T13:01:45.464865Z 86 Prepare SELECT password FROM test order by ?
2025-03-28T13:01:45.464918Z 86 Execute SELECT password FROM test order by 'id;INSERT INTO test (id, username, password) VALUES (4, \'5\', \'6\');'
2025-03-28T13:01:45.465150Z 86 Close stmt
2025-03-28T13:01:45.465183Z 86 Quit 你先别管执行结果对不对,反正确实防止了sql注入。

这里我突然有了一个非常有趣的想法,如果我修改预编译的逻辑,让excute这里不带上引号,这次执行究竟会注入成功还是注入失败呢,到这里我翻mysql官网就没翻到啥结果了,反正mysql一再重申参数标记只能用于应出现数据值的位置,不能用于 SQL 关键字、标识符等,但也没说为啥不能,反正我们之前虽然执行结果错误了,都还是能执行语句,于是我就去翻了一下php的官方文档,又是经典的没中文:https://www.php.net/manual/zh/mysqli.quickstart.prepared-statements.php
这里提到:

准备好的语句执行包括两个阶段:准备和执行。在准备阶段,语句模板被发送到数据库服务器。服务器执行语法检查并初始化服务器内部资源以供稍后使用,同时 MySQL 服务器支持使用匿名位置占位符?。而准备之后是执行,在执行期间,客户端绑定参数值并将其发送到服务器。服务器使用先前创建的内部资源执行具有绑定值的语句。
对于重复执行的情况,每次执行时,都会评估绑定变量的当前值并将其发送到服务器。不会再次解析该语句。语句模板不会再次传输到服务器。
这里也提到了,绑定变量与查询分开发送到服务器,因此不会干扰查询。在解析语句模板后,服务器在执行时直接使用这些值。绑定参数不需要转义,因为它们永远不会直接替换到查询字符串中。必须向服务器提供绑定变量类型的提示,以创建适当的转换。

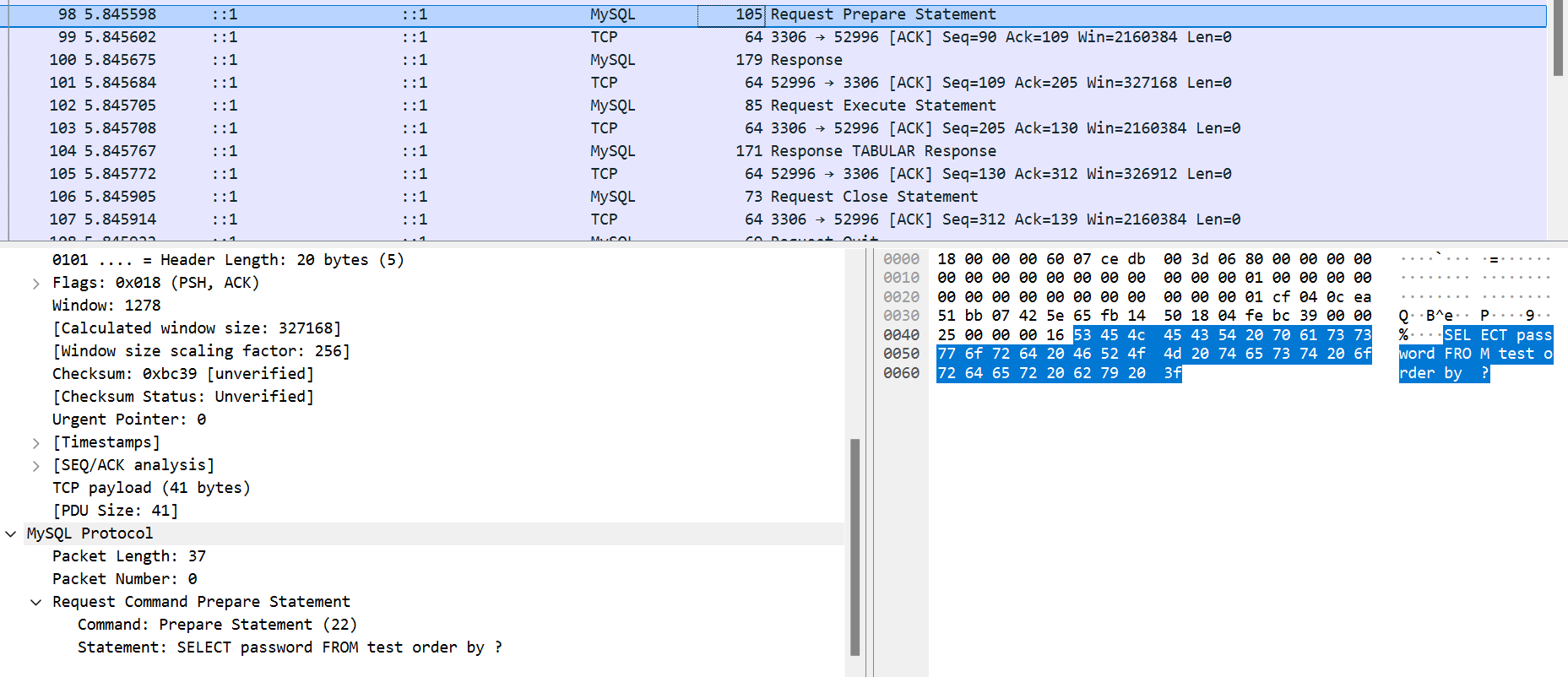
接着我直接去本地抓了一下web服务和数据库服务通讯的二进制协议的流量
第一个过程是prepare,可以看到大概就是把带?的sql语句发给了数据库
第二个过程是执行,就是把我们想要查询的实际参数id发过去让数据绑定并执行
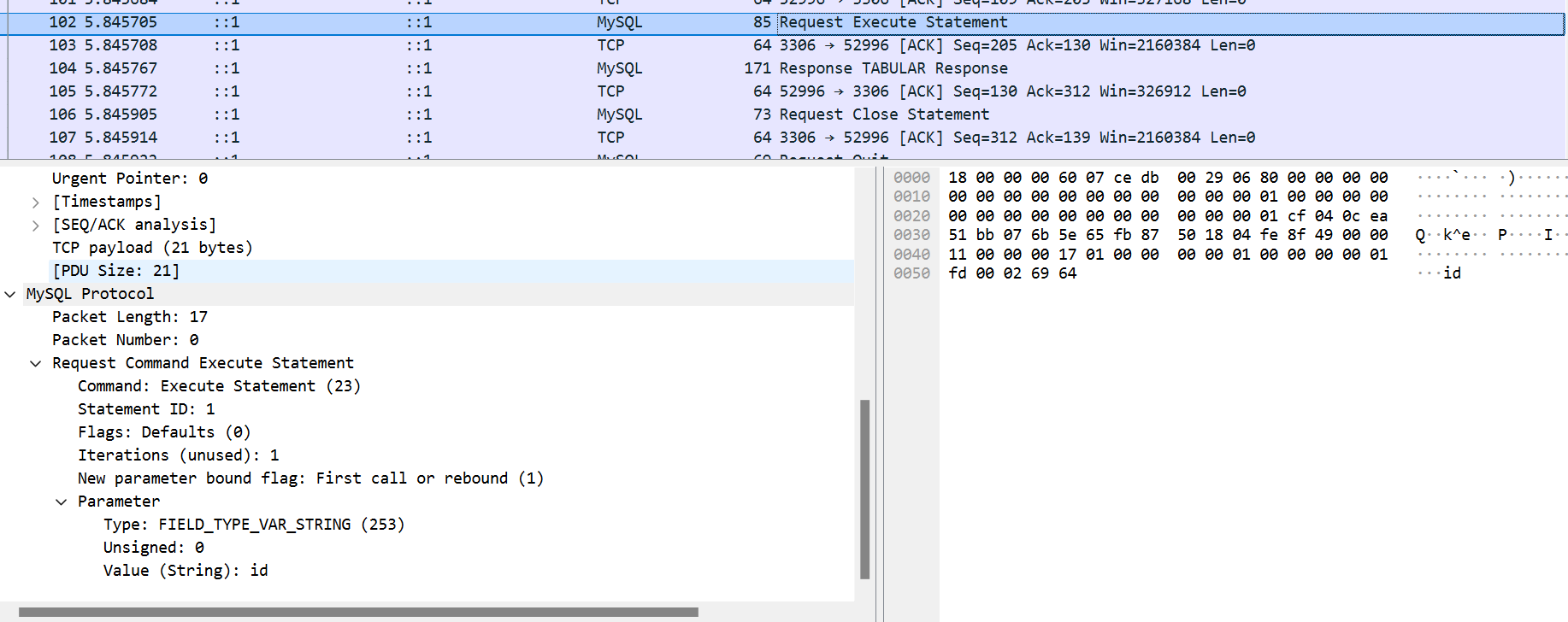
这里表明了这个id是一个string,可以看到整个过程没有什么引号不引号的,之所以无论是php还是java,当我们看预编译的日志,表现出来执行结果有引号,其实是mysql的锅,mysql默认就认为他们是一个字符串,而不是编程语言的问题,因此研究就此告终,除非我把mysql底层执行查询的逻辑修改了,否则应该不可能修改掉预编译默认为数据值周围应该带上引号的问题,这也是为什么不能提出一个能对任何位置进行预编译的安全预编译功能的原因,本质上大伙都只是调用了mysql的接口,mysql不改你想怎么改都没用。
对预编译进行sql注入
那么现在进入第二个问题———预编译真的是一种cure-all吗?现在我们知道了预编译的第一个缺陷,由于预编译底层设计的问题,确实只能在数据值的位置进行预编译,而不能在 SQL 结构部分进行参数绑定,要么执行结果会出错,要么查询结果不对,现在进入第二个问题,如果我就是想在被预编译了的位置进行注入,那么究竟有没有办法呢?
预编译之所以被大家视作可以对抗sql注入,是因为预编译消除了sql执行的歧义,但他并没有解决一个很重要的问题——用户的输入还是被数据库执行了,无论你使用预编译也好,还是不使用预编译也好,总有一步,是需要执行用户的输入的,那么从这个角度思考,预编译还有没有不完备的地方呢?
我们来思考一下一次sql查询的流程究竟是什么🤔
比如我们想执行SELECT password FROM test order by password,我们的流程是客户端会发送一个id=password,然后服务器拼接password并执行sql语句吗?

其实并不是这样的,web服务是一个服务,数据库服务也是一个服务,既然是不同的服务,就会有不同服务之间的通信,而他们的通信方式就被称作二进制协议,因此实际流程是:
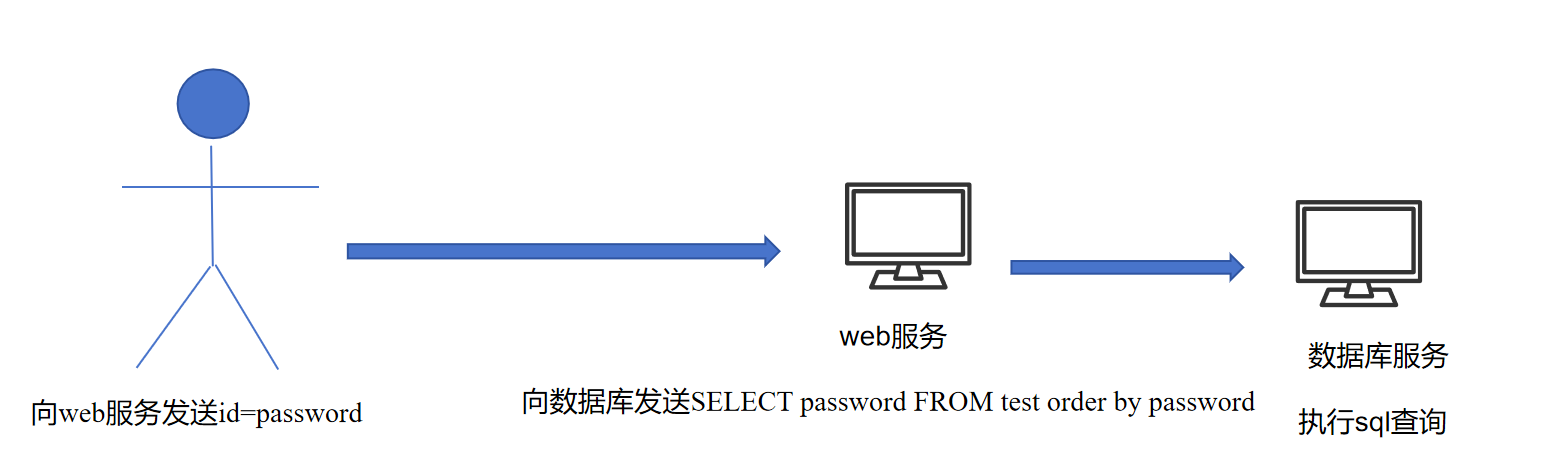
实际上的过程是,用户向web服务发送了id=password,web服务接收到password之后,拼接进自己的sql查询语句,得到结果SELECT password FROM test order by password,再把这个语句发送给数据,让数据库执行这次sql查询。
那么预编译消除了哪个过程可能的sql注入呢?其实是客户端到web服务这一层的,因为他消除了语句的歧义,让web服务发送给数据库服务的sql语句就是真实想查询的sql语句,但预编译消除了web服务到数据库服务这个过程的sql注入了吗?如果我的注入并不能通过消除歧义解决,那么预编译还有作用吗?现在我们将目光转向web服务和数据库服务的通讯方式——二进制协议,来探讨一下从web服务到数据库服务这个过程的sql注入。
假设二进制协议的格式如下:

- 第一个字段是表示Type,表示这次查询的类型,比如表示这个过程是prepare还是execute。
- 第二个字段表示Length,也就是长度,假设他4B大,那么就可以表示一个大概4GB大小的查询语句。
- 第三个字段表示Value,也就是具体的值,具体发送的sql查询语句。
那么web服务究竟是怎么构造这样一个请求的呢,可能是这么构造的:
func (src *Bind) Encode(dst []byte) []byte {
dst = append(dst, 'B')
sp := len(dst)
// ...
pgio.SetInt32(dst[sp:], int32(len(dst[sp:])))
return dst
}首先添加一个标签,再用len函数获取具体的sql语句长度并保存到一个int32的变量里,毕竟我们的Length字段最大也只能放4B,这确实是一个很自然而然的想法,毕竟正常的查询语句又不可能超过4GB——但我又不是一个正常用户,我可是攻击者,攻击者的视角当然不是这样的😈
我们知道,4B最大保存的数字其实是FFFFFFFF,如果再大一点会发生什么呢,比如再加1,那么他就会变成100000000,如果再进行一次截断,那么最后保存进这个int32变量的值其实就是00000000,最高位的1被舍弃了,因此现在有一个非常有趣的思路,只要我发送一个非常非常大的sql语句,那么就会超过FFFFFFFF的最大长度,而通过精妙的构造和截断,实际上我们现在就能控制发送的这次请求的Length字段。
那么数据库究竟是怎么解析我们的二进制协议的呢,其实就是根据Length的长度,去解析Length范围内的sql语句并进行执行,除此之外的二进制数据由于并不是按照二进制协议的格式来的,就成为了数据库无法识别的脏数据。
现在再进行一次思考🤔,如果我们能构造一次精妙的截断,让截断后的二进制数据恰好就是按照二进制协议的格式来的,那么数据库是不是就会识别我们这个二进制协议,并执行相应的sql语句了呢?
事实正是如此,而这正是CVE-2024-27304的原理,Paul Gerste在DEF CON 32上分享的议题便是关于协议层sql注入的原理:DEF CON 32 – SQL Injection Isn’t Dead Smuggling Queries at the Protocol Level – Paul Gerste,通过一次精妙的溢出,我们便可以执行任意的sql语句,预编译只是消除了sql执行的歧义,并没有消除sql注入本身。
翻开这次漏洞的公告,我们可以发现,pgx的解决办法是防止用户的输入超过4GB

这里又引申出一个有意思的结论,至少在go里,这种问题其实是无法解决的,官方只是防止了用户输入超过4GB,因为只要超过4GB就还是能存在注入🤔所以说不定还会有一些奇淫技巧能绕过这个限制,比如一些什么压缩功能之类,至少这个漏洞给了我们一个有趣的结论,预编译并不是不可能战胜的,他并没有消除从web服务到数据库服务这一层中可能的注入,他只是消除了sql执行的歧义罢了,或许在这一层的通讯中,还会有什么神奇的技巧让我们绕过预编译的魔爪。
除此之外CVE-2024-6382也是由于同样的原理产生了SQL注入,并且在KalmarCTF 2025被出成了一道题目,可以看到他们的官方wp:KalmarCTF 2025 – NoSQLi
25年的时候拿这个出了道题:https://fushuling.com/index.php/2025/07/14/mocsctf2025-ez-writeez-injection/
后记
这篇博客简单聊了聊预编译本身的缺陷,导致从编程语言的角度无法解决存在某些位置不能被预编译的问题,除此之外也谈了谈从web服务到数据库服务通讯中可能存在的sql注入,在这一层里的sql注入是预编译无法覆盖的,不知道有没有哪一天mysql会良心发现,专门针对sql注入研发一种技术彻底解决sql注入的问题,不过那一天出现的话不知道多少web狗得失业了😭
这文章写的有点像外国人写的那种了,狗哥高质量文章
特别棒的文章,学习了