前言
前端的 JS 代码混淆一直以来是 web 安全里一个让人头大的问题,为了解决代码混淆给网络安全带来的挑战,以及当前缺乏针对性评估标准的问题,本文的作者提出了一个名为 JsDeObsBench 的基准测试框架。该框架包含从简单变量重命名到复杂结构变换等多种混淆技术,旨在系统评估 GPT-4o、DeepSeek-Coder 等前沿 LLM 在 JS 反混淆任务上的表现。
背景
JS 混淆被广泛用于隐藏恶意代码,严重阻碍漏洞检测、恶意软件分析等安全分析过程,现有的反混淆工具难以应对复杂的混合变换,而 LLM 天然具有语义理解的功能,在代码理解上表现出色,因此将 LLM 引入代码反混淆是一个很自然而然的想法,然而如今缺乏专门针对 JS 反混淆能力的系统性评估基准,这也是作者做这个工作的主要动机。
本文的主要贡献是提出了 JsDeObsBench 这个基准测试框架,作者同时构建了首个可执行的 JS 反混淆大规模数据集,包含 36,260 个良性混淆样本和 4,515 个恶意混淆样本。作者设计了一个自动化评估管道,从语法正确性、语义正确性、代码简化度、可读性这四个维度对反混淆的结果进行评分。文章主要评估了 GPT-4o、DeepSeek-Coder、Llama-3 等 6 款模型。GPT-4o 综合表现最佳,Codestral 在开源模型中领先,LLM 在代码简化和提升可读性方面,显著优于传统反混淆工具,得到的代码更加清晰易读,缺点是执行可靠性差,生成的代码常有语法错误或无法运行(平均失败率 37.40%),而传统基线工具这方面更稳定。
概述
构建 JsDeObsBench 面临三大挑战:
- 数据无真值: 现有的混淆代码常来自恶意软件或网页,没有源代码,缺乏 Ground Truth,导致完全无法验证反混淆后的正确性。
- 模型有短板: LLM 主要受自然语言训练,缺乏处理混淆代码的知识,且直接使用公开数据容易导致数据泄露,导致模型可以通过”背题”得到一个高分。
- 指标不全面: 现有评估仅关注变量名恢复,缺乏对代码逻辑正确性、执行结果和可读性的综合衡量。
综合对上面挑战的考量,作者对三大挑战提出三个对应的解决办法:
- solution 1:从头构建大规模、可执行验证的混淆数据集,既保证了有源代码作为对照,又防止了数据泄露。
- solution 2:基于 EvalPlus 榜单选用代码能力强的 LLM,并利用上下文学习 (In-context Learning) 技术,通过提供示例来引导模型进行反混淆。
- solution 3:作者设计了一个四维的评估体系:
- 语法正确性(代码是否合规)
- 执行正确性(语义是否改变,能否跑通)
- 复杂度降低(Halstead 指标,代码是否变简单)
- 可读性(与原代码的相似度)
JsDeObsBench 的 Workflow 分为三步:
- 数据集构建:对代码进行混淆构建数据集
- LLM 反混淆:利用提示词引导 LLM 进行反混淆
- 反混淆评估器:评估反混淆效果

数据集构建
作者需要的是人类编写的、功能多样且可验证执行的代码,经过反复的对比,作者选择了 CodeNet 数据集,该数据集也已经被广泛用于代码的评估任务,包含着大量编程竞赛题目解答,相比于 StackOverflow 片段或 Github 仓库,竞赛代码自带测试用例(输入/输出),可以通过这些测试用来验证反混淆后的代码是否破坏了原有逻辑。
虽然 CodeNet 提供了许多高质量的 JS 程序,但还是有一些小缺点,比如部分提供的示例不能通过在线判断、某些代码可能超过了 LLM 的上下文、部分功能过于重复,因此作者设计了三个过滤器来对数据集进行清洗,将初始的 58,395 个程序筛选至 1,298 个高质量样本:
- 执行过滤器 (Execution Filter): 剔除那些跑不通测试用例的代码
- 长度过滤器 (Length Filter): 剔除过长或过短的代码,确保适合放入 LLM 的上下文窗口中
- 重复功能过滤器 (Repetitive Functionality Filter): 每个编程问题只保留一个解法,避免重复评估

接下来需要对这些精选的样本进行代码混淆,作者选择使用业界流行的 JavaScript-Obfuscator 工具,模拟真实世界的混淆场景,包括七种混淆技术:
- 代码压缩 (Code Compact): 去除空格、换行。
- 名称混淆 (Name Obfuscation): 变量名改为
_0xabc或a, b等无意义字符。 - 字符串混淆 (String Obfuscation): 隐藏字符串字面量,运行时还原。
- 死代码注入 (Dead Code Injection): 插入无用的垃圾代码增加体积。
- 控制流平坦化 (Control Flow Flattening): 把代码逻辑打散成
switch结构,破坏阅读顺序。 - 调试保护 (Debug Protection): 加入反调试代码,检测到调试器则崩溃。
- 自防御 (Self-defending): 包含校验和或自修改代码,防止代码被格式化或重命名
生成混淆代码时作者没有只使用单一技术,而是随机组合多种技术(例如:同时使用重命名+死代码+平坦化),最终生成了 36,260 个良性混淆样本。
除了上面这些良性样本,作者还特意选择了来自 Hynek Petrak 和 GeeksOnSecurity 的 40k+ 真实恶意脚本,这些恶意软件没有标准的“输入输出”测试用例,因此作者使用 Box-js 沙箱记录恶意行为(如修改注册表、网络请求),只要反混淆前后的行为轨迹一致,即视为语义正确。最终筛选并生成了 4,515 个恶意混淆样本。
LLM 反混淆
为了让模型发挥最佳性能,作者设计了两种提示词(Prompt):
- 零样本提示(Zero-shot Prompt): 直接给模型“任务描述”和“混淆代码”,要求输出干净的反混淆代码,不给任何示例。
- 单样本提示(One-shot Prompt): 在零样本的基础上,增加一个演示示例(输入混淆代码 -> 输出反混淆代码)。
- 为什么选单样本? 研究发现给一个示例能显著提升模型适应特定领域的能力。
- 为什么不用更高级的思维链(CoT)? 作者认为思维链(Chain-of-Thought)虽然强,但在反混淆任务上提升有限,且计算成本太高(太慢、太贵)。单样本(One-shot)是效果与效率之间的最佳平衡点。
作者根据透明度、复现性和代码能力,从 EvalPlus 榜单上挑选了 6 款模型:
- 偏好开源模型: 为了保证实验透明、可控且适合大规模任务(如处理数百万次请求),优先选择开源模型(如 CodeLlama, DeepSeek-Coder 等)。
- 偏好代码专用模型(Code-LLMs): 相比通用模型,专门在代码数据集上训练过的模型(如 CodeLlama)对程序分析理解更深,更适合反混淆。
- 引入 GPT-4o 作为参考: 虽然它是闭源的,但作为当前最强的通用模型,被引入作为性能天花板的参考对象。

反混淆评估器
为了全面衡量 LLM 生成的代码质量,作者设计了一套包含四步的评估流程:
- 语法评估器 (Syntax Evaluator)
- 目的: 检查 LLM 生成的代码是否符合语法规则,能不能被计算机读懂。
- 方法: 使用标准的 JS 解析器 esprima 尝试解析代码。
- 标准: 只有解析器不报错,才算通过。这是最基础的门槛。
- 执行评估器 (Execution Evaluator)
- 目的: 检查代码的逻辑语义是否正确,是否保持了原有功能。
- 方法:
- 良性代码: 在隔离的 Docker 环境中运行代码,看它能否通过所有的测试用例(输入/输出比对)。
- 恶意代码: 比较反混淆前后的行为轨迹(如网络请求、文件操作)是否一致。
- 标准: 必须通过所有测试用例或行为一致才算成功。
- 简化评估器 (Simplification Evaluator)
- 目的: 检查反混淆后的代码是否真的变简单了(混淆通常会把代码搞得很复杂)。
- 方法: 使用 Halstead Length (HLoC) 指标来计算代码复杂度(基于操作符和操作数的数量)。
- 公式: 计算复杂度降低的比例。分数越高,说明代码被简化得越多,去除了越多的垃圾代码。

- 相似度评估器 (Similarity Evaluator)
- 目的: 衡量代码的可读性,看它是否接近人类编写的原始代码。
- 方法: 使用 CodeBLEU 指标,对比反混淆后代码与原始源代码。
- 原理: CodeBLEU 不只看字面相似,还会比较抽象语法树 (AST) 和数据流图 (DFG),综合判断结构和逻辑像不像。
代码结果的评估是按顺序的,通过语法评估器的再测试执行评估器,只有这两关都过才算成功反混淆,最后无论是否执行成功,只要语法正确,都会计算简化分和相似度分,用来分析代码质量。
实验评估
JsDeObsBench 基于 Python 开发,也使用了 PyTorch、Transformers、DeepSpeed、Docker 等开源工具,作者的测试环境非常豪华,使用了一台配备 AMD EPYC 32核 CPU、1TB 内存和 8 张 NVIDIA A100 (80GB) 显卡的服务器。
实验旨在回答以下四个问题:
- RQ1 (总体表现): LLM 在 JS 反混淆方面的总体表现如何?
- RQ2 (准确性): LLM 和 Baselines 得到的反混淆代码语法和语义是否正确?
- RQ3 (可读性): LLM反混淆后的程序可读性如何(即复杂度降低程度以及与原始代码的相似度)?
- RQ4 (实战能力): LLM 能对恶意 JS 代码进行反混淆吗?
为了公平对比,作者挑选了JS-deobfuscator 和 Synchrony 这两个传统的反混淆工具作为 Baseline,这两个工具在 GitHub 上星数较高(JS-deobfuscator 和 Synchrony 都是1.1k star),功能全面,能支持通用型反混淆,且支持命令行操作,适合大规模自动化测试,其他的一些待选工具比如 JSNice 和 De4js,主要靠网页手动操作,难以批量测试,而 DeMinify 太冷门,不具有代表性。
作者从 Hugging Face 下载开源模型,而闭源模型 GPT-4o 就直接选择调用 OpenAI API。为了提高效率并节省显存,本地模型运行在 FP16(半精度) 模式下,且Batch Size 被设置为 1:
- 原因: 混淆后的代码通常非常长(参考 Table 3),如果同时处理多个样本(Batch Size > 1),显存很容易爆。
- 策略: 设置 Batch Size 为 1,即一次只处理一个样本,最大程度利用显存来容纳超长的输入序列。

为了保证实验结果的一致性和完整性,作者对输出做了严格限制:
- 最大生成长度 (Max Gen Length) = 2,048 tokens:
- 这个长度足以容纳数据集中最长的原始代码。确保模型在反混淆时,不会因为 token 耗尽而把代码写一半断掉(Output Truncation)。
- 确定性解码 (Deterministic Decoding):
- 设置:
top_p = 1,top_n = 1。 - 温度 (Temperature) = 0.1: 极低的温度值意味着模型几乎没有“创造性”或随机性。
- 原因: 代码反混淆是一项严谨的任务,需要的是标准答案(语法正确的代码),而不是模型的自由发挥。这种设置能让模型每次输出的结果尽可能稳定。
- 设置:
RQ-1:LLM 的整体有效性
从实验数据上看,GPT-4o 在执行正确性 (0.9342)、代码简化度 (0.3825) 和 相似度/可读性 (0.6702) 上都拿到了最高分,是综合性能最好的模型;DeepSeek-Coder 在生成的代码是否符合语法规则(0.9906) 上效果最好, 甚至略微击败了 GPT-4o (0.9599)。

但将和 LLM 和 baseline 做对比,LLM 并不是全方位碾压,而是各有优劣:
- LLM 的优势(赢在质量):
- 代码更简单易读: LLM 生成的代码在简化度上比基线工具高出 16.11% (最高分对比) 或 12.13% (平均分对比)。
- 语义恢复能力强: 顶尖 LLM(如 GPT-4o 和 Codestral)在成功反混淆的数量上实际上超过了基线工具,证明它们更能理解代码的深层含义。
- LLM 的劣势(输在稳定性和速度):
- 容易写出 Bug: 基线工具几乎能保证 100% 语法正确,83% 执行正确;而 LLM 平均只有 97.23% 语法正确,60.93% 执行正确。这意味着 LLM 经常一本正经地胡说八道,写出的代码跑不通。
- 速度太慢: LLM 的推理速度比传统工具慢 20 倍。
将代码模型和通用模型做对比,作者发现了一个很自然而然的规律:在同一个模型家族中,专门针对代码训练的版本表现远好于通用版本。
- CodeLlama 的语法正确性比 Llama-3.1 高 5.13%。
- Codestral 的执行正确性比 Mixtral 高 54.21%。
所以做反混淆任务,最好选用经过代码训练的专家模型 (Expert Model),而不是通用的聊天模型。
RQ2:语法和执行正确性

作者通过语法检查(Syntax Check)和执行检查(Execution Check),将 LLM 与传统基线工具进行了深度对比:
- 语法正确性 (Syntax Correctness)
- 传统基线工具完胜: Synchrony 和 JS-deobfuscator 的通过率是 100%。它们生成的代码永远符合语法规则。
- LLM 略有瑕疵: LLM 平均有 2.76% 的语法错误率。
- 执行正确性 (Execution Correctness)
- 整体差距: LLM 的平均执行失败率高达 37.40%,而传统工具表现稳健(除个别情况外)。
- 模型对比:
- 专业版 > 通用版: 经过代码训练的模型(CodeLlama, Codestral, DeepSeek-Coder)比通用模型(Llama-3.1, Mixtral)强得多,平均优势达 32.66%。
- 最强选手: GPT-4o 依然领先,但在语义恢复上仍有挑战。
- 基线工具的死穴: 虽然传统工具通常很稳,但遇到 “Self-defending”(自防御) 混淆时几乎全军覆没(1298个样本里只过了2个)。
- 难度分析 (Difficulty Factors)
- 最容易的题:Code Compact(代码压缩)。LLM 处理得最好,平均得分 0.7918。
- 最难的题:String Obfuscation(字符串混淆)。LLM 处理得最差,平均得分 0.4663。
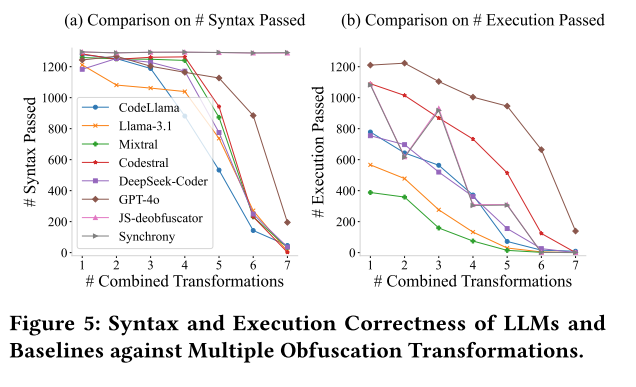
现实中的混淆往往是多种技术叠加的,随着混淆层数增加,所有工具(LLM 和 baseline )的表现都直线下降,阈值是6层,当混淆技术叠加超过 6种 时,所有方法的成功率几乎都归零,只不过其中 GPT-4o 表现还是最好的,在6层混淆下,它还能保持 20.39% 的语义正确率,而其他模型此时只有 2% 左右。
RQ3:代码简化和相似
代码简化度 (Code Simplification)是衡量反混淆工具能否去除“死代码”和“复杂逻辑”,把代码变简单的能力
- LLM 完胜传统工具:
- LLM 在降低代码复杂度方面表现显著优于基线工具。
- 数据对比: 在处理最难的“字符串混淆”时,CodeLlama 的简化分中位数高达 0.7643,而传统工具 Synchrony 只有 0.6860,JS-deobfuscator 几乎为零(0.01)。这意味着传统工具往往只是机械地还原,而 LLM 能真正理解并精简代码。
- 越混淆,越简化(有趣的趋势):
- 随着混淆层数增加(例如从1层增加到5层),LLM 的简化得分反而上升了(例如 CodeLlama 提升了 0.5096)。
- 原因: 多层混淆会让原始代码变得极度臃肿(分母变大),而 LLM 倾向于生成简洁的代码(分子变小),因此计算出来的“减肥比例”非常惊人。
- 注意: 当混淆超过 6 层时,虽然简化分很高,但因为代码往往已经有语法错误(跑不通了),所以这个高分参考价值降低。
代码相似度/可读性 (Similarity / Readability)是衡量反混淆后的代码长得像不像原本的人类源码(基于 CodeBLEU 指标)。
- GPT-4o 遥遥领先:
- GPT-4o 生成的代码最像原始代码,中位分数为 0.6616。
- 相比之下,传统工具 Synchrony (0.5944) 和 JS-deobfuscator (0.4851) 生成的代码可读性较差。
- 难点与易点:
- 最容易: Code Compact(代码压缩)。LLM 很容易还原这种只是去掉了空格的代码。
- 最难: Name Obfuscation(变量名混淆)。因为变量名一旦被改成
a,b或_0x123,LLM 也很难猜出程序员原本起的名字(导致 GPT-4o 分数降至 0.5317)。
- 层数越深,还原越难:
- 与简化度不同,相似度随着混淆层数的增加而下降。
- 但在高难度下(5层混淆),GPT-4o 依然最稳,比其他方法平均高出 21.62%。
RQ4:消除JS恶意软件的混淆
相比于处理普通代码,LLM 在处理恶意代码时表现大幅下降:
- 语法正确率下降: 平均下降了 22.43%(从 97.24% 跌至 74.81%)。
- 执行正确率暴跌: 平均下降了 47.71%(从 62.60% 跌至 14.89%)。
- 结论: 恶意代码的反混淆对 LLM 来说是非常困难的挑战,大部分生成出来的代码都跑不通。
在良性代码上表现无敌的 GPT-4o 在这里翻车了,而开源模型上位:
- GPT-4o 的滑铁卢: 它的语法正确率很低,主要原因是触发了安全过滤器 (Safety Filtering)。GPT-4o 识别出这是恶意代码,直接拒绝回答(Refusal),导致输出为空或报错。
- 开源模型胜出:
- 语法最佳:Codestral (92.80%)。
- 执行最佳:DeepSeek-Coder (25.01%)。
- 原因: 开源模型通常没有那么严格的强制安全过滤,因此更愿意尝试去处理恶意代码。
虽然 LLM 生成的恶意代码很难跑通(执行分低),但它们非常易读。
- LLM 的简化得分比传统基线工具高出 28.85%。
- 实战价值: 即使代码跑不通,LLM 把复杂的恶意逻辑改写成了简单清晰的版本,这对安全分析人员理解病毒原理非常有帮助。
一个有趣的现象是,反混淆后的代码与“原始”恶意代码相似度很低(下降 26.72%):
- 收集来的“原始”恶意样本本身往往就已经被黑客混淆过一次了。LLM把它还原成了干净的代码,导致两者长得完全不一样。这在指标上看似是坏事(相似度低),但实际上说明反混淆效果很好(去除了伪装)。
案例研究
LLM 为什么会反混淆失败?
作者分析了那些未能通过语法或执行检查的失败案例,总结出四大根源:
- 复读机模式 (Self-repeating)
- 模型有时会像复读机一样,把提示词(Prompt)里的指令再抄一遍,或者重复输入的内容。这导致输出中混杂了自然语言,破坏了代码语法。
- 上下文窗口限制 (Limited LLM Context Window Size)
- 某些混淆技术(如“控制流平坦化”)会生成极长的代码(例如巨大的 Hash Map)。这导致输出超出了 LLM 的最大长度限制,代码写到一半被截断,自然就报语法错误了。
- 拒绝回答 (Refuse to Response)
- 主要是 GPT-4o 的问题。当要求反混淆恶意代码,或某些混淆特征看起来像恶意攻击时,会触发 OpenAI 的安全过滤器,模型直接拒绝生成代码。
- 语义篡改 (Semantic Manipulation)
- 这是最隐蔽的错误。代码能跑,语法也对,但逻辑变了。
- 在一个例子里,原代码是按
line[2], line[0], line[1]拼接,模型误将混淆代码中十六进制的\x02和\x01当成了数字1和2,擅自改成了line[1], line[0], line[2],导致程序功能改变。
LLM 为什么擅长简化与提升可读性? (Code Simplification and Readability)
为了解释为什么 LLM 在简化度和相似度上得分那么高,作者分析了具体的成功案例(以 Codestral 模型为例),发现 LLM 具备传统工具(如 Synchrony)所没有的四项核心能力:
- 精准的理解力 (Precise Comprehension)
- 即使代码被改得面目全非(到处是乱码符号),LLM 依然能透过现象看本质,理解这段代码是用来“计算数字之和”的。
- 变量名恢复 (Accurate Name Recovery)
- 这是 LLM 最大的优势。传统工具通常保留垃圾变量名(如
_0x5e1f19),而 LLM 能根据上下文逻辑,将其重命名为有意义的单词(如input,num)。
- 这是 LLM 最大的优势。传统工具通常保留垃圾变量名(如
- 类型推断 (Correct Type Inference)
- LLM 能猜出变量应该是什么类型。例如,它识别出
num应该是整数,于是会在生成的代码中自动加上Math.floor来保持整数类型。
- LLM 能猜出变量应该是什么类型。例如,它识别出
- 显著提升可读性 (Significant Enhancement in Readability)
- 对比显示,传统工具生成的代码依然满屏乱码,极难阅读;而 LLM 生成的代码结构清晰、命名规范,几乎就像是人类程序员写出来的。
总结
作者总结了 LLM 在反混淆任务上的“双刃剑”特性,并提出了改进思路:
- LLM 的潜力 (Potential)
- 虽然 LLM 在准确性(语法和执行)上不如传统工具,但在可读性(代码简化、变量名/类型推断)上展现了巨大优势。这说明 LLM 非常适合用于辅助理解晦涩的代码,甚至可以帮助改进程序分析中的其他难题(如类型推断)。
- 如何改进 (Enhancing LLMs)
- 目前的痛点是性能(跑不通)。
- 问题根源: 之前提到的“复读机”模式、上下文窗口限制、语义篡改等。
- 改进方案: 虽然模型支持的上下文越来越长(如 Claude 支持 200k tokens),但光靠这个不够。未来必须进行更高级的预训练和微调 (Fine-tuning),特别是针对代码数据集和复杂混淆逻辑进行专门训练,才能让模型在面对高难度混淆时不再“乱写”。
- 目前的痛点是性能(跑不通)。
作者坦诚地指出了本研究存在的不足,这些也是未来研究可以突破的方向:
- 数据集来源 (Dataset)
- 目前的良性代码主要来自“编程竞赛题”(为了保证有测试用例)。但这可能无法完全代表真实世界中日新月异的 JS 程序。未来应考虑纳入更多新开发的脚本。
- 恶意软件数据 (Malware Data)
- 目前的恶意代码库混合了“已混淆”和“未混淆”的样本,因为很难在网络上找到大规模且纯净(未混淆)的恶意软件源码。这导致计算相似度时分数偏低(因为是在跟一个本身就混淆过的代码比)。
- 混淆工具单一 (Obfuscation Tools)
- 本研究主要基于主流的 JavaScript-Obfuscator。实际上还有很多新的混淆技术(如机会主义变换)和新的反混淆工具出现。未来可以用 JsDeObsBench 去测试更多样的工具。
- 模型覆盖度 (Advanced LLMs)
- 受限于计算资源(毕竟是学术团队),无法测试市面上所有的模型和所有参数规模的版本。随着 LLM 领域发展极快,未来会有更多新模型值得测试。
总的来说,这个工作最大的贡献是提出了 JsDeObsBench,第一个系统性评估 LLM 反混淆能力的框架,作者通过实验发现 GPT-4o 等模型极大地提升了代码的可读性和简化度,但也暴露了语法准确性和执行可靠性方面的短板。LLM 有潜力彻底改变网络安全中的反混淆流程(实现自动化),但在模型训练和优化上还有很长的路要走。JsDeObsBench 将作为未来衡量这些进步的重要标尺。
From Obfuscated to Obvious: A Comprehensive JavaScript Deobfuscation Tool for Security Analysis
NDSS 2026