前言
受yulate强烈推荐,去B站看了一下目前国内学术界静态分析最前沿的静态分析课,由南京大学李樾老师和谭添老师主讲,讲的确实挺好的:南京大学《软件分析》课程01,这篇文章主要就写一下我个人的笔记,系统的、全面的入门静态分析。
静态分析的基本概念
静态分析
静态分析(Static Analysis) 是指在实际运行程序之前,通过分析静态程序本身来推测程序的行为,并判断程序是否满足某些特定的性质
我们需要关心的东西
- 程序是否会产生私有信息泄漏(Private Information Leak),或者说是否存在访问控制漏洞(Access Control Venerability);
- 程序P是否有空指针的解引用(Null Pointer Dereference)操作,更一般的,是否会发生不可修复的运行时错误(Runtime Error);
- 程序P中的类型转换(Type Cast)是否都是安全的;
- 程序P中是否存在可能无法满足的断言(Assersion Error);
- 程序P中是否存在死代码(Dead Code, 即控制流在任何情况下都无法到达的代码);
静态分析结果的评定标准
这里有几个非常重要的概念
- Sound:即全面的或者完备的,简单来说,满足Sound即允许错报不允许漏报
- Truth:真实的,顾名思义,就是一个程序真正存在的漏洞,是最理想的分析结果
- Complete:完整的,简单来说,满足Complete即允许漏报但不允许错报
这里我们可以用一张图来清晰的看出这三者的关系
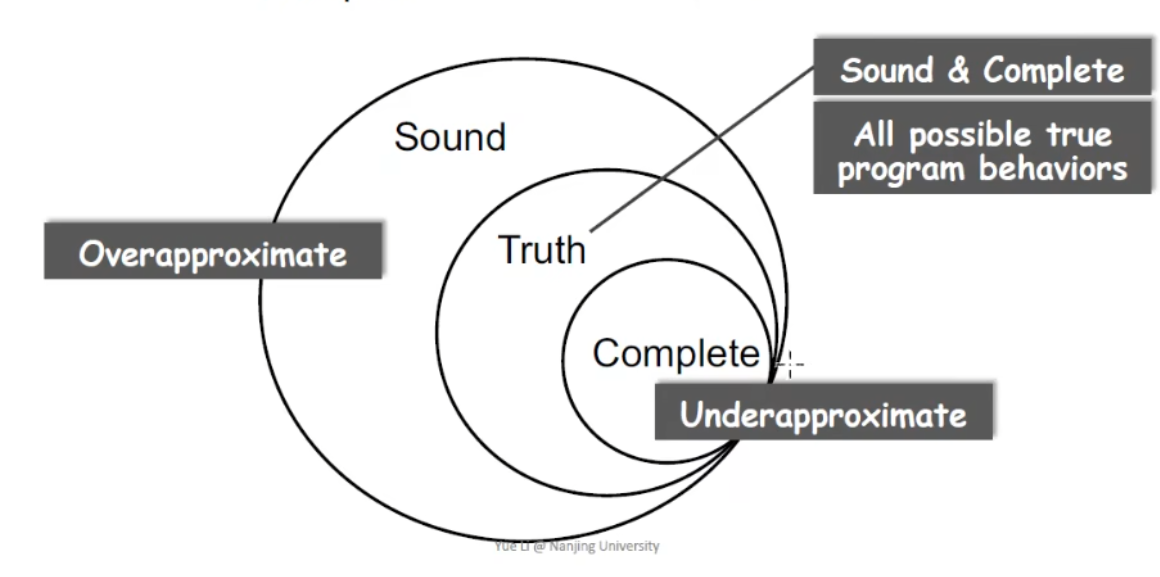
可以看见,Truth是Sound的子集,Complete又是Truth的子集,Sound属于一种Overapproximate,即过拟合,而Complete属于一种Underapproximate,即弱拟合。
在真实的程序分析中,显然我们首先需要做到Sound,在Sound的基础上不断向Truth靠拢,道理很简单,因为即使Sound里出现了错报,我们也还可以通过安全人员人工分析排除掉哪些错报的漏洞,而漏报带来的负面效果就不是那么好处理的了
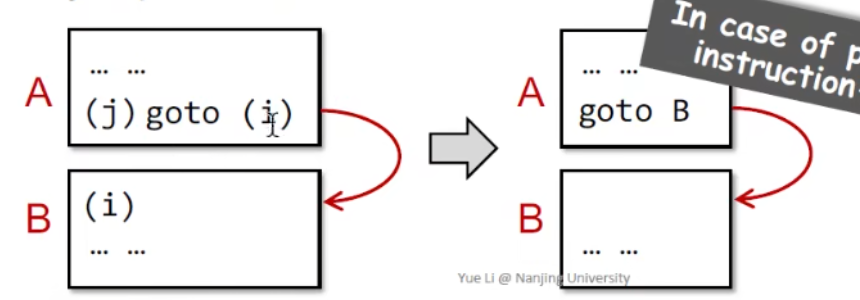
BasicBlock(基本块)
BasicBlock,中文叫基本块,具体定义是一个基本块中只有一个入口和一个出口,入口就是其中的第—个语句,出口就是其中的最后一个语句。对一个基本块来说,执行时只从其入口进入,从其出口退出。
在具体程序中,我们划分BasicBlock的方式就是找到不同的leader,即不同BasicBlock的入口点,通过不同的入口点划分不同的BasicBlock,划分leader有三条原则
程序的第一条语句
即整个程序最初的入口,显然他一定是leader
转移语句的目标语句
比如一个goto语句跳转到了第三句代码,那么这个第三句代码就是leader,这里我们可以用反证法来证明他一定是leader。
假如第三句代码不是leader,那么也就是他之前的代码是BasicBlock的入口,比如是第二句,那么就出现了矛盾。对于一个BasicBlock,他的入口应该只有一句,而由于goto语句的跳转,第三句代码成为了从goto语句到这个BasicBlock的入口,而第二句同样是入口,与BasicBlock只能有一个入口和一个出口的原则矛盾,因此第三句代码一定是leader
紧跟在条件转移语句后面的语句
比如第三句代码是一个goto语句,那么第四句代码必然是leader,这里也可以用一个反证法来简单的证明第四句代码一定是BasicBlock一定是leader。
假设第四句代码所在的BasicBlock中第四句代码不是Leader,而第五句代码是该BasicBlock的出口,由于第四句代码不是Leader,那么第三句代码与第四句代码在同一个BasicBlock中,这里就出现了矛盾。由于第三句代码是一个goto语句,因此他是该BasicBlock的出口,而第五句代码也是BasicBlock的出口,同一个BasicBlock中出现了两个不同的出口,产生了矛盾,因此第四句代码一定是Leader
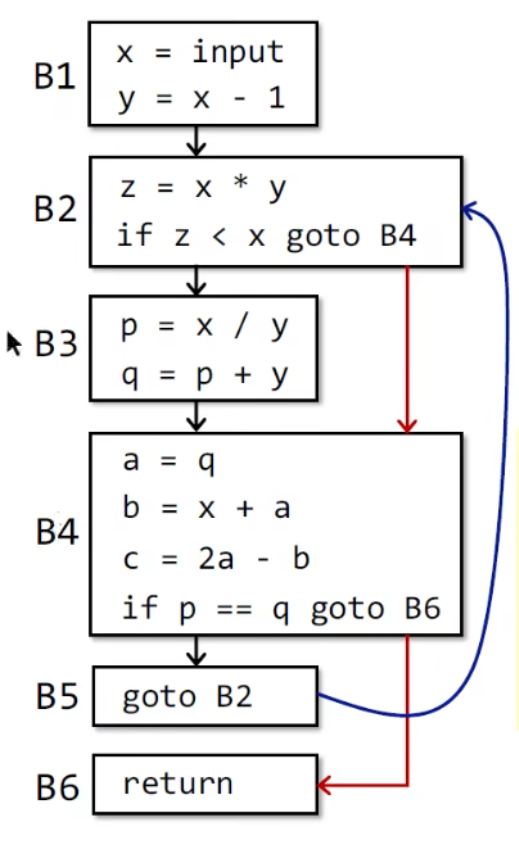
BasicBlock可以很清晰的看见程序中控制流的流动,因为程序控制流在BasicBlock中只能从一个入口流入,一个出口流出。这里我们举一个例子来看看实际代码中应当如何划分BasicBlock:
(1)x=input
(2)y = x
(3)z = x * y
(4)if z < x goto (7)
(5)p = x / y
(6)q = p + y
(7)a = q
(8)b = x + a
(9)c = 2a - b
(10)if p == q goto (12)
(11)goto(3)
(12)return按照第一条原则,程序的第一条语句必须是leader,我们可以得到leader:(1)
按照第二条原则,转移语句的目标语句必须是leader,我们可以得到leader:(3) (7) (12)
按照第三条原则,紧跟在条件转移语句后面的语句必然是leader,我们可以得到leader:(5) (11) (12)
对三个集合进行合并,整个程序的leader便是:(1) (3) (5) (7) (11) (12)
通过不同的leader划分不同的BasicBlock,我们可以划分出该程序的BasicBlock分别为{(1) (2)},{(3) (4)},{(5) (6)},{(7) (8) (9) (10)},{(11)},{(12)}
Control Flow Graph (CFG)(控制流图)
有了BasicBlock作为工具,我们就可以很清晰的画出程序的Control Flow Graph,即控制流图,下面以CFG作为简称。
什么是CFG呢?控制流图(Control Flow Graph, CFG)也叫控制流程图,是一个过程或程序的抽象表现,是用在编译器中的一个抽象数据结构,由编译器在内部维护,代表了一个程序执行过程中会遍历到的所有路径。它用图的形式表示一个过程内所有基本块执行的可能流向, 也能反映一个过程的实时执行过程。
CFG 能反映出一个过程的许多信息,包括但不限于:
- 是哪一个过程;
- 一个过程的入口(第一个基本块) 和出口( 最后一个基本块);
- 一个基本块的所有可能的下一个基本块( 所有的出口);
- 一个基本块的所有可能的上一个基本块( 所有的入口);
- 一个基本块所对应的语句表。
CFG的节点是BasicBlock,只有两种情况下从块A到块B存在边
从A的末尾到B的开头有一个有条件或无条件的跳转
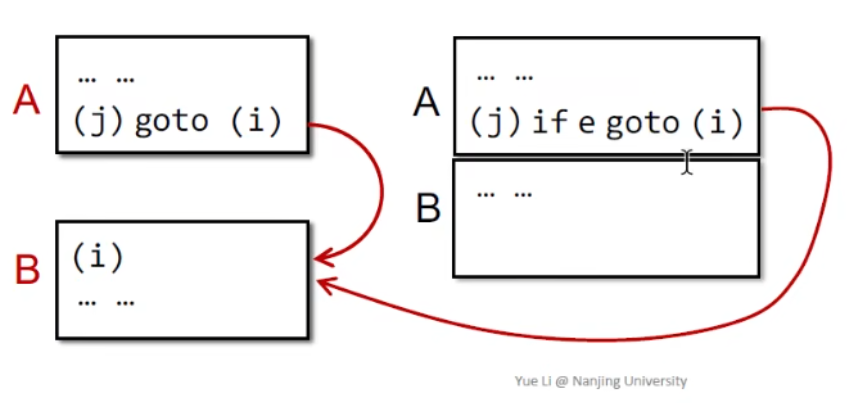
B立即按照原始指令顺序跟随A且A不会以无条件跳转结束
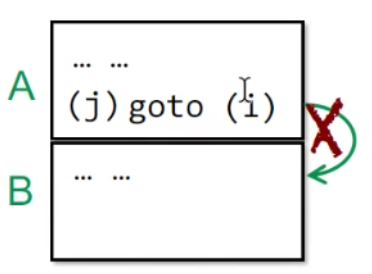
因此这种A以跳转结尾的情况下,A与B之间不存在边
若A不以跳转结尾,那么二者间存在边
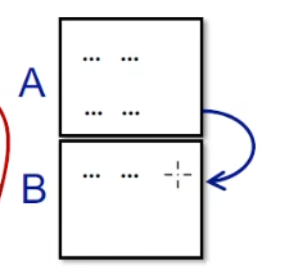
在日常的分析中,我们会经常把跳转到指令标签替换为跳转到基本块,这样就简化了我们分析的难度
对于我们最初给出的代码例子,画出来的CFG就是
编译器和静态分析器
这里可能有的师傅会比较疑惑,上面我们分析的代码都非常的规整,因此无论是划分BasicBlock还是画CFG都相对比较容易,对于实际中的代码,可能会非常复杂繁琐,并且一句代码里可能跟着许多奇怪的操作和定义,按照上面的方法在实际的代码中划分出来BasicBlock吗?这里再来补充一点与编译相关的知识。
我们编写的源文件本质上是一个ASCII码字符串文件,离变成真正的程序交由CPU处理还有非常遥远的距离。对于静态类型语言,其源代码向机器码转化的过程大致如下:
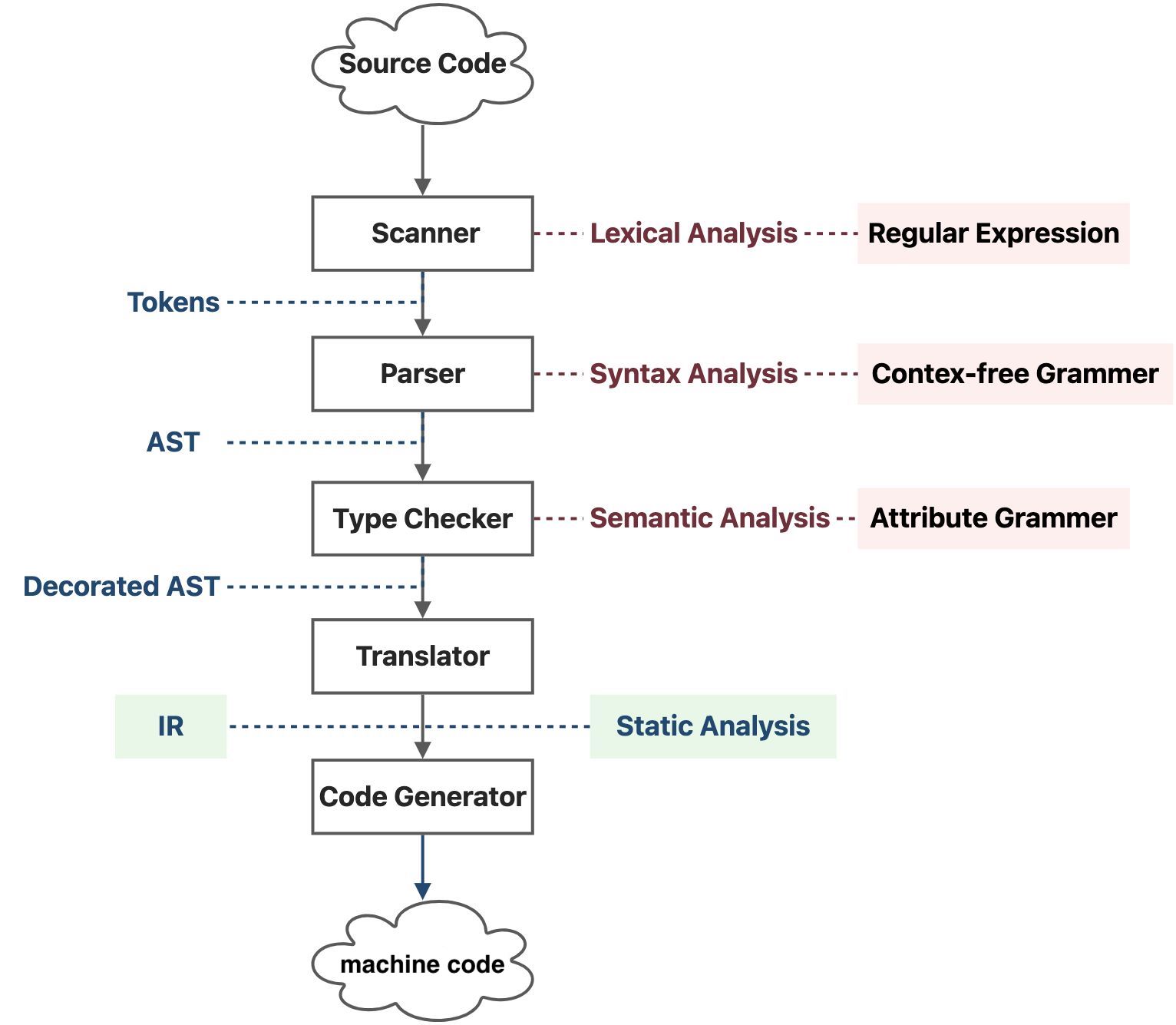
- Scanner: 扫描源代码,进行词法分析(Lexical Analysis),词法分析会用到正则表达式(Regular Expression),词法分析后的结果为一个标记(Token)串。
- Parser: 遍历标记串,进行语法分析(Syntax Analysis),这里的语法分析分析的是上下文无关的语法(Context Free Grammer),解析器的内部应该是实现了一个有限状态机,用于识别和分析每个语法块格式的正确性,语法分析的结果为一棵抽象语法树(Abstract Syntax Tree, AST)。
- Type Checker: 会遍历抽象语法树,进行语义分析(Semantic Analysis),不过编译器的语意分析是简单的,主要是分析属性语法(Attribute Grammer),比如说变量类型,并适当调整一下语法树。语义分析的结果我们称之为装饰过的抽象语法树(Decorated AST)。
- Translator: 会将抽象语法树翻译成中间表示(Intermediate Representation, IR),IR 的出现解耦了编译器的机器相关(Machine Dependent)部分和机器无关(Machine Independent)部分,上述几个层次在不同架构的机器上面是可以几乎不加改动地复用的。
- Code Generator: 会将 IR 转化成物理 CPU 能够直接执行的比特序列,也就是机器代码
而我们的静态分析发生在IR这个过程,也就是将抽象语法树翻译成中间表示的过程
AST vs IR
对于下面这个简单的代码
do i = i + 1; while (a[i] < v);AST和IR的结果分别是
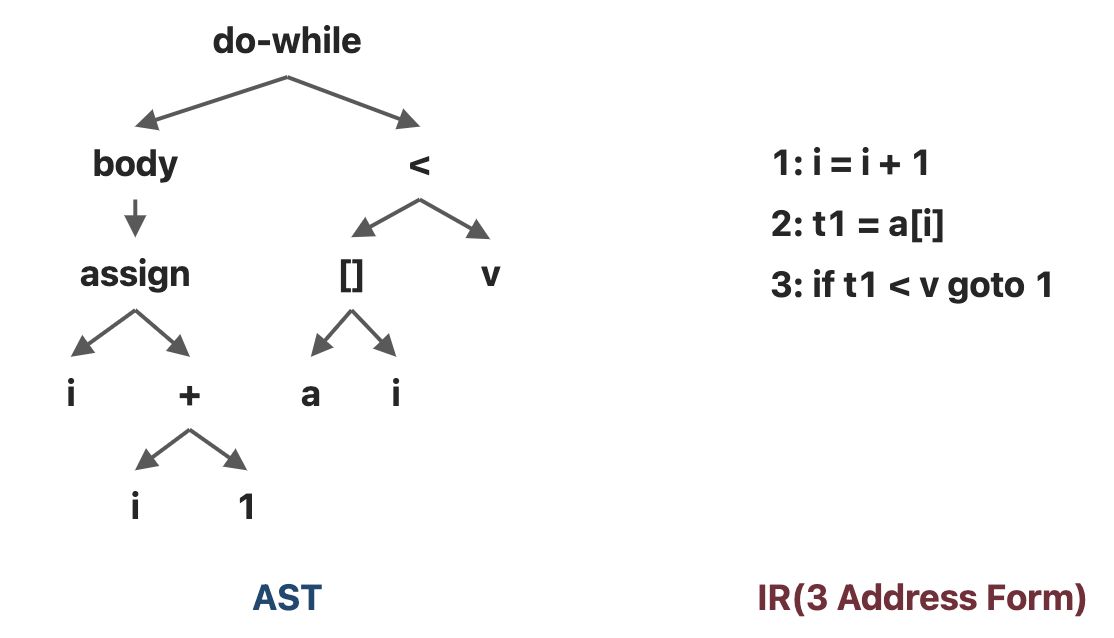
这里其实可以很直观的感受出来,抽象语法树(AST)是源代码结构的一种抽象表示,以树状的形式表现编程语言的语法结构,相对而言层次较高,和语法结构更接近,并且依赖于具体的语言类,缺少和程序控制流相关的信息
而IR与机器代码接近,通常与具体的语言无关,简单通用,包含程序的控制流信息,也是我们做静态分析的基础。
三地址码
我们通常使用3地址码(3 Address Form,缩写为TAC 或 3AC)形式的IR,三地址码叫三地址码不是因为他真的有三个地址,而是因为每个三地址码指令,都可以被分解为四个元组(4-tuple):(运算符,运算对象1,运算对象2,结果)。因为每个陈述都包含了三个变量,所以它被称为三地址码。
给个具体的例子,比如代码
a+b+3转化成三地址码就是
t1 = a + b
t2 = t1 + 3其中a, b是原始变量,3是常数,t1和t2是编译过程中生成的临时变量
常见的的三地址码形式有,这里的x y z即三个地址
x = y bop z //bop:二进制算术或逻辑运算
x = uop y //uop:一元运算(减号、否定、强制转换)
x = y
goto L //L: 表示程序位置的标签 goto L就是一种无条件跳转
if x goto L // if ... 满足条件后再xxx属于一种条件跳转
if x rop y goto L //rop:关系运算符(>、<、==、>=、<=等)有了这里的基础知识,再看上面的BasicBlock和CFG就会恍然大悟了,为什么我们之前分析的代码都那么规整,因为3AC下的代码本来就是这么规整的,通过3AC再分析复杂程序,就会大大减轻我们进行程序分析的难度
静态分析用于分析安全问题
信息流安全
信息流安全 vs 访问控制
访问控制(Access control),是一种保护敏感数据的标准方法,主要用于检查程序是否有权访问某些信息,关注如何访问信息
信息流安全(Information flow security),是一种端到端的方法,跟踪信息如何流经程序,以确保程序安全地处理信息,关注信息如何传播
什么是信息流
如果变量x中的信息被转移到变量y中,那么就有信息流x→y
比如现在有一个代码y=x,或者一个长一点的代码
a = x;
b.f = a;
y = b.f;这时,x中的信息就流向了y,就有信息流x->y
这里需要区分data flow,也就是数据流这个概念。事实上二者并不能完全画上等号,出现信息流x->y,并不一定是因为数据的直接流动导致的。学安全的师傅们,应该知道测信道这个概念,对于目标x,即使x的数据并没有直接流向y,我们也可以通过一些侧面的信息获取x的取值信息。比如下面这个代码:
x=int(input())
y="hello world"
if(x<1) printf(y);
else if(1==x) printf(y,"123");
else printf(y,"456") 这里虽然x与y之间并不存在直接的数据流动,但我们仍然可以通过程序最后的输出判断出来x的取值范围,这时我们也认为x的信息流向了y
什么是信息流安全
信息流安全(data flow security)将信息流与安全连接起来,将程序变量分为不同的安全级别,指定这些级别之间允许的流动,即信息流策略
最基本的模型是两级策略,即一个变量被归类为两个安全级别之一:
- H 级,意思是高安全等级(High Security),表示秘密信息;
- L 级,意思是低安全等级(Low Security),表示公开可见的信息。
比如下面的代码
h=getPassword(); //h是高安全等级
broadcast(l); // l是低安全等级h由一个获取密码的函数获得,属于保密信息,而l直接broadcast,也就是广播了出来,属于公众可见的信息,自然属于低安全等级的信息
安全等级可以建模成一个格(Lattice),“格”是一种特殊的偏序集。在许多数学对象中,若所考虑的元素之间具有某种顺序,我们将这个偏序集称之为格。由于安全等级之间存在偏序关系且两两之间存在上下确界: L≤H,所以我们可以用格的模型来抽象安全等级。当然,除了最简单的High和Low的二元划分,实际应用场景中,安全等级可以划分的非常复杂
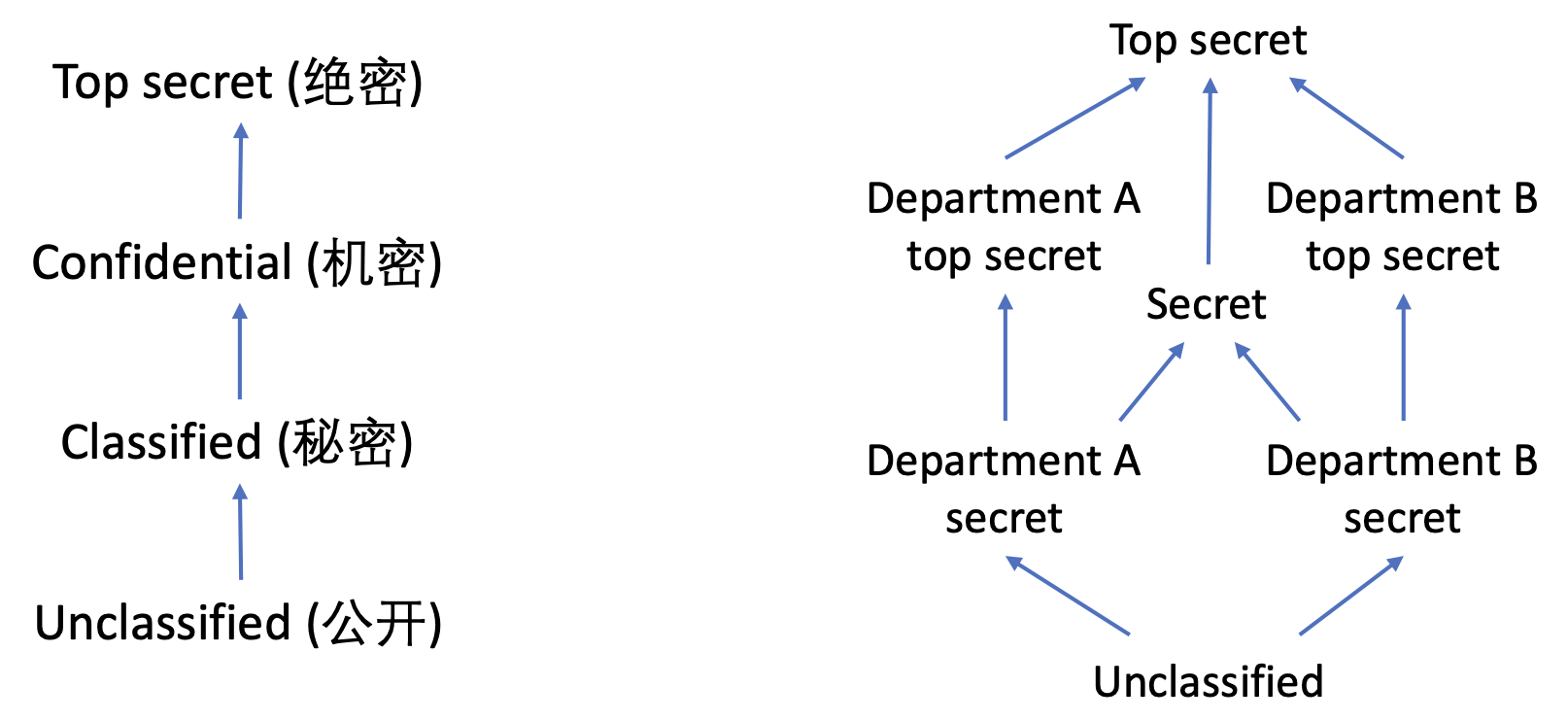
左边就是我们国内的信息的链式安全等级划分,比如高考试卷是全国性的试卷,属于绝密级别,是最高机密,泄露高考试卷一般都得判个五六年,相对而言中考试卷的等级就要低一些,一般属于机密或者秘密等级。
右边是一个可能的商业上的网状划分模式,这种划分方式就复杂的多。因为可能不同部门之间还有不同的划分方式,有部门内部的top secret和secret,不同部门的secret可能又从属于不同于部门top secret的secret中。
信息流政策
信息流策略(data flow policy)了限制不同安全级别之间的信息流动方式
信息流策略必须遵循不干扰策略(Noninterference policy),即要求高变量的信息对低变量的信息没有影响(即不应干扰)。直观地说,你不应该能够通过观察低变量得出有关高信息的任何结论(无论是直接的还是侧面的)
对于下面这个例子,假设下标H表示高安全等级,L表示低安全等级,H->H或者L->L都是允许的,因此1 2句代码是允许的,但对于第三句和第五句代码,无论什么情况下,H的信息都不允许流向L,但是L的信息允许流向H
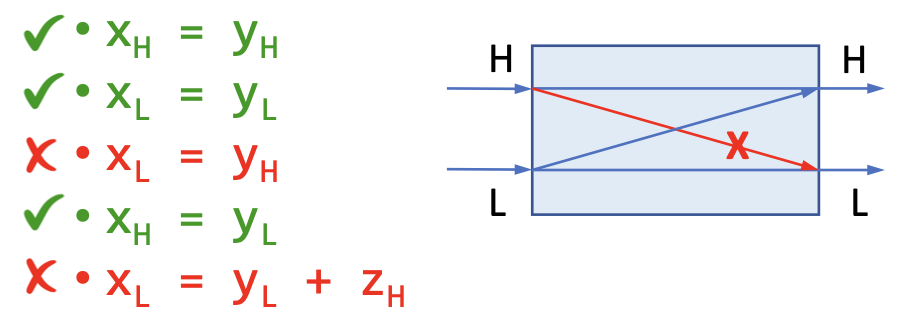
这样保证了在安全等级格当中信息流只会自下而上流动(从低安全等级流向高安全等级)
机密性和完整性
直观的讲,机密性(Confidentiality) 指的是阻止机密的信息泄漏,即不允许机密信息流向攻击者,可以理解成是一种“读保护”。

完整性(Integrity) 指的是防止不受信任的信息破坏(受信任的)关键信息,即不允许不受信任的信息流向受信任的信息,可以理解成是一种“写保护”

机密性很好理解,就是防止信息泄露嘛,那为什么还要有一个完整性呢,这里举一个最常见的代码注入例子:
x= readInput();//untrusted
cmd = "..." + x
cmd = execute(cmd);//critical(trusted)这里的x就属于不受信任的信息,而execute函数就属于受信任的关键信息,如果不受信任的x流向了受信任的execute函数,就会导致RCE,因此我们不但需要保护程序的机密性,也必须保护程序的完整性。
这里我们可以发现机密性和完整性恰好是对称的。机密性防止H(高安全等级信息)流向L(低安全等级信息),而完整性是防止L(不受信任的信息)流向H(受信任的信息)。
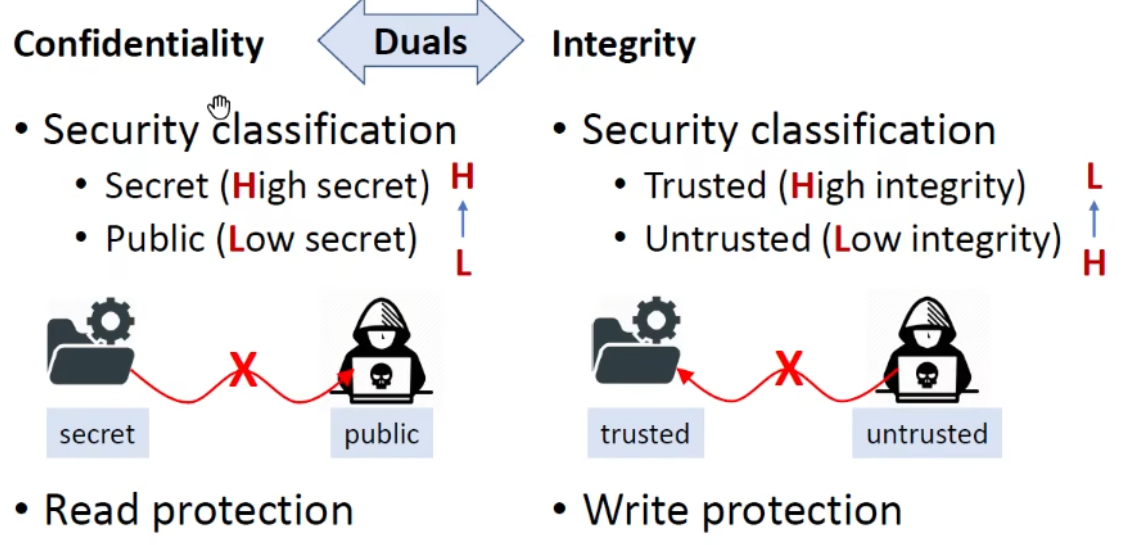
广义的完整性
广义的完整性,还需要维护和保证数据的准确性(Accuracy)、完全性(Completeness)和一致性(Consistency)
准确性(Accuracy):为了保证信息流的完整性,(可信的)关键数据不应被不可信的数据破坏
完全性(Completeness):数据库系统应完整存储所有数据
一致性(Consistency):文件传输系统应确保两端(发送方和接收方)的文件内容相同
显式流(Explicit Flows)和隐蔽信道(overt Channels)
信息如何流动
信息通过直接复制进行流动,这叫做显式流(Explicit Flows),比如a = b这种
但信息也可以通过影响控制流的方式向外传递,这样的信息流称为隐式流(Implicit Flow)
secret = getSectre();
if (secret < 0)
publik = 1;
else
publik = 0;秘密控制下副作用的任何差异都会对有关控制的信息进行编码,这些信息可能会被公开观察并泄露秘密信息。这里我们就可以通过观察 publik 的方式推测出 secret 是否为负,这样就泄漏了1比特的信息,当然,相比于显式流,隐式流的泄露影响小的多
隐蔽信道
我们将在计算系统中指示信息的机制为 信道(Channels) 。如果这个指示信息的机制的本意并不是信息传递,这样的信道称为 隐蔽信道(Covert/Hidden Channels) ,也就是说隐蔽信道实际上是正常信道传播中产生的副作用,只不过这种副作用存在了泄露信息的可能。
常见的隐蔽信道有很多种:
隐式流
通过程序的控制结构来指示信息
if (secret < 0)
public = 1;
else
public = 0;这里我们可以通过public的信息判断secret的取值
终止信道(Termination Channels)
通过程序是否终止来指示信息
while (secret < 0)
...;时间信道
通过程序的计算时间来指示信息
if (secret < 0)
for (int i = 0; i < 1000000; i++)
...;异常
通过程序的异常来指示信息
if (secret < 0)
throw new Exception("...");或者
int sa[] = getSecretArray();
sa[secret] = 0; // 若secret的值为负数,这条指令就会报错同样的,与正常信道相比,隐蔽信道的信息泄露效果会差的多。
污点分析(Taint Analysis)
污点分析(Taint Analysis)是最常见的信息流分析技术。它将程序数据分为两类:
- 感兴趣的数据(分析完整性时指的是不受信任的数据,分析机密性时指的是敏感数据),我们会给这些数据加标签,加上标签后叫做污点数据(Tainted Data)
- 其他数据,称为无污点数据(Untainted Data)
污点分析追踪污点数据是如何在程序中流动的,并且观察它们是否流动到了一些我们关心的敏感的地方。其中,污点数据产生的地方称为 源头(Source) ,我们不希望污点数据流向的敏感地带称为 水槽(Sink) 。在实际中,污点分析的source通常是一些特殊的方法,这些方法会返回一些污点数据(比如说密码、命令之类的);而污点分析的sink点通常也是一些敏感的方法(比如说写日志、执行命令之类的)。
我们现在来看看污点分析如何帮助我们解决程序的完整性和机密性问题。
机密性
- source:保密数据源
- sink:泄漏点
这时污点分析常用于处理信息泄漏,比如说代码:
x = getPassword(); // source
y = x
log(y); // sink这时污点数据(这时的污点数据指的是敏感数据)在x = getPassword()产生,这里也就是source点;而我们不希望污点数据流向的敏感地带sink点是log(y),因此,这时我们就需要判断从x = getPassword()这个source点产生的污点数据是否最终会流向sink点log(y)。
完整性
- source:不受信任的数据源
- sink:敏感函数
这时污点分析常用于处理代码注入等注入相关的漏洞,比如:
x = readInput(); // source
cmd = "..." + x;
execute(cmd); // sink这时污点数据(这时的污点数据指的是不受信任的数据)在x = readInput()产生,这里是source点;而我们不希望污点数据流向的敏感地带sink点是execute(cmd),因此我们需要判断从x = readInput()产生的污点数据最后是否会流向sink点execute(cmd)。
在实际中,我们常常将污点分析抽象成<sources,sinks,sanitizers>的形式,source和sink上面已经解释,此处不再赘述,那么sanitizer指的是什么呢?sanitizer翻译过来叫做消毒剂,这里我们应当理解成无害化处理,即代表通过数据加密或者移除危害操作等手段使数据传播不再对软件系统的信息安全产生危害
通过上面的模型,现在污点分析转化为分析程序中由污点源引入的数据是否能够不经无害处理,而直接传播到污点汇聚点。如果不能,说明系统是信息流安全的;否则,说明系统产生了隐私数据泄露或危险数据操作等安全问题
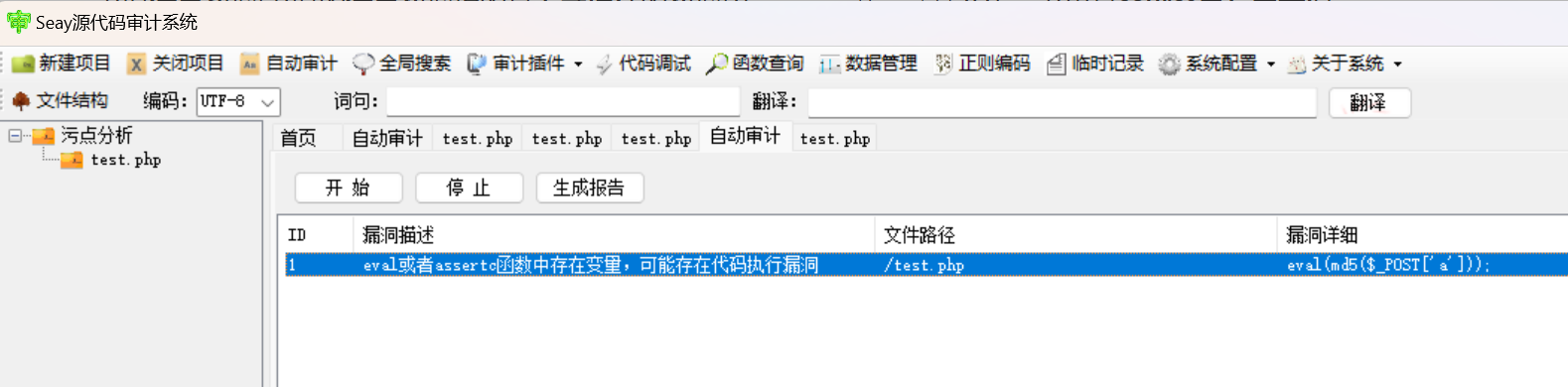
为什么非要加上一个sanitizer呢,这个其实很好理解,对于常见的静态分析软件,比如Seay这种基于正则匹配的代码审计程序,不但难以分析可控数据能否真的流向危险函数,即使真的流向了危险函数,我们也很难判断可控数据在流向危险函数时是否仍然具有威胁性,比如下面的代码
<?php eval(md5($_POST['a'])); ?>作为安全分析者的我们知道,虽然source点$_POST['a']产生的污点数据确实流向了sink点eval(),但由于数据流经过了sanitizer函数md5()的处理,不受信任的数据已经不再具有威胁性,而对于Seay这种基于正则的原始代码审计软件是没有这么智能的,只会匹配到eval就报漏洞
并且我们也可以非常直观的感受到,通过sanitizer我们是非常容易分析未授权漏洞的,比如有一个鉴权代码include(CheckSession.php),我们只需要分析我们的污点数据是否能不经过这个sanitizer流向sink点即可
污点分析的处理过程
污点分析的处理过程可以分为三个阶段:
- 识别污点源(source)和汇聚点(sink)
- 污点传播分析
- 无害处理
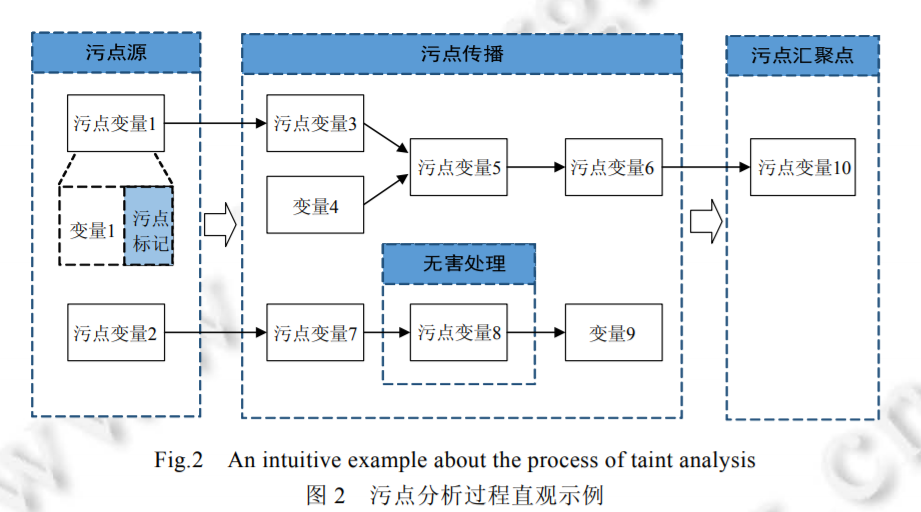
识别污点源(source)和汇聚点(sink)
不同程序中source和sink的识别方式不同,一般的,我们通过以下方式:
- 使用启发式的策略进行标记,例如把来自程序外部输入的数据统称为“污点”数据,保守地认为这些数据有可能包含恶意的攻击数据,也就是一种Overapproximate,当然为了实现Sound,这一点无可厚非
- 根据具体应用程序调用的 API 或者重要的数据类型,手工标记Source和Sink
- 使用统计或机器学习技术自动地识别和标记Source及Sink
下图是一些学术论文中提出的Web应用程序漏洞检测中的Source点

污点传播分析
污点传播分析,顾名思义,便是分析污点真正的数据流动轨迹,现在主要分为显式流分析和隐式流分析两种
显式流分析
这里前面其实已经解释过基本概念,也就是分析污点标记如何随程序中变量之间的数据依赖关系传播,这里主要给个例子来具体看看如何在代码中分析显式流和隐式流
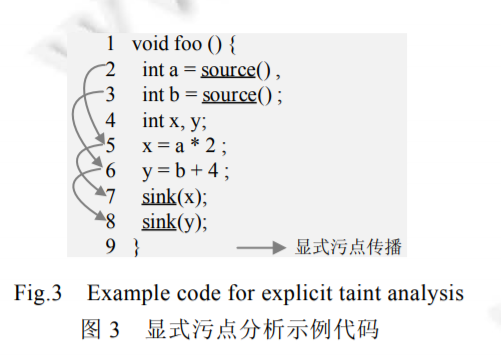
int a =source ↓x = a * 2 ↓sink(x) int b =source ↓y = b + 4 ↓sink(y)这两条就属于非常直接的、肉眼可见的从Source到Sink的流动,通过直接的赋值、函数调用实现信息的流动
隐式流分析
隐式流分析是分析污点标记如何随程序中变量之间的控制依赖关系传播,也就是分析污点标记如何从条件指令传播到其所控制的语句

这里的显式流较为明显,不再赘述,主要就是隐式流比较有意思。虽然x和y之间并不存在直接的赋值或者调用,但是信息仍然通过控制依赖从x传播到了y
for (int i=0;i<X.length();i++){
int x=(int)X.charAt(i);
int y=0;
for (int j= 0;j< x; j++){
y=y+1;
}x具体代表的值我们不知道,但这里的for循环的含义实际上就是x是多少,y就增加多少,最后for循环结束实际上x和y的值是一样的。因此虽然不存在直接的数据关系,信息仍然从x流向了y,这就叫隐式流传播
无害处理(sanitizer)
污点数据经过sanitizer的处理后,数据本身不再携带敏感信息或者针对该数据的操作不会再对系统产生危害。 正确地使用无害处理可以降低系统中污点标记的数量,提高污点分析的效率,并且避免由于污点扩散导致的分析结果不精确的问题。例如,加密库函数像是上面例子中的md5()应该被识别成无害处理模块,经过md5()处理后的md5($_POST['a'])不应再被认为是污点数据。