前言
对于一般工业界的漏扫工具,比如xray,它和爬虫之间其实是解耦的,比如xray是外接了一个rad。xray本身专注于漏洞检测逻辑(Payload 发送 + 响应判断),而不负责目标页面/接口的路径发现(URL 枚举),这项工作是由rad完成的,这是一个xray官方推出的专注于信息搜集的爬虫工具。换句话说,xray 专注做漏洞检测逻辑本身,而不负责 URL 的发现与采集工作;这部分通常通过外部爬虫来完成,并以输入流的形式与 xray 对接。
这带来一个问题:比如我们知道对于有些URL的访问是有顺序的,比如假设在购物场景中,购买成功让你填收货地址的表单里存在一个XSS,想要访问到这个漏洞点,我们需要按照顺序:选择一个商品加入购物车=>回到购物车=>选择该商品进行付款=>进入一个付款界面进行付款=>付款成功跳转到填写收获地址界面,只有按照这个流程触发不同的功能点击不同的URL,我们才能最终走向存在漏洞的URL。我印象里的这些漏扫工具只是对着搜集到的URL发payload,或者是保存了爬虫的包进行重放包,但是对于一些验证较为严格的站点,单纯的重放包可能会被检测出来(比如验签),只有我们按照这个访问流程才能走向真正有漏洞的URL,然后检测到漏洞。
该如何保证扫描工具”记住”正确的API请求顺序,从而发现这些一般漏扫发现不了的潜藏的比较深的漏洞呢?这就是今天这篇论文的主题了,这是一篇来自于四大网安顶会之一的USENIX Security的论文:NAUTILUS: Automated RESTful API Vulnerability Detection,值得注意的是该论文的大部分作者都来自中国,比如奇安信、中信所等等,是一次典型的工业界与学术界的结合。
背景
这里首先来介绍一下论文标题中的RESTful API是什么,RESTful API 是一种符合 REST 架构风格 的 Web API 设计方式,用于客户端和服务端之间通过 HTTP 协议进行通信,REST(Representational State Transfer) 是一种面向资源(Resource)的架构设计理念,由 Roy Fielding 在 2000 年提出,它强调:
- 每个资源都可以用 URL 唯一表示
- 使用标准的 HTTP 方法进行操作
- 无状态通信(每次请求都是独立的)
- 返回的数据是资源的“表现形式”(Representation)
因此 REST 是一组架构规范,并非协议或标准,你可以采用各种方式实现 REST,只要最后符合REST的核心理念,我们都认为这是一种RESTful API:
- 客户端-服务器架构由客户端、服务器和资源组成,并且通过 HTTP 管理请求。
- 无状态客户端 – 服务器通信,即 Get 请求间隔期间,不会存储任何客户端信息,并且每个请求都是独立的,互不关联。
- 可缓存性数据:可简化客户端-服务器交互。
在这里论文着重介绍了一个案例:CVE-2021-21389,在 BuddyPress 系统中,NAUTILUS 成功检测了一个特权提升漏洞,需要 6 次 API 调用才能触发(如注册、登录、创建群组、读取 token、伪造身份等),传统工具因无法理解 nonce 传递和接口顺序而完全无法检测该漏洞:

想要触发该漏洞,你的工作流程必须是:注册=>登录=>创建群组=>获取群组中的管理员对象(包括一个令牌)=>通过该令牌修改用户属性=>查看自身是否权限提升
显然,现在传统的漏扫工具是没法发现这种漏洞的,首先你没有令牌就压根没法在请求中带载荷,访问都访问不到,其次就算访问到了也没法感知攻击是否成功,因为你需要再访问一次关于自身的接口才能看到自己是否真的权限提升了,针对这种问题,作者设计了 NAUTILUS 工具以解决这种传统漏扫工具的缺陷。
NAUTILUS的总体设计
下面是他的设计图:
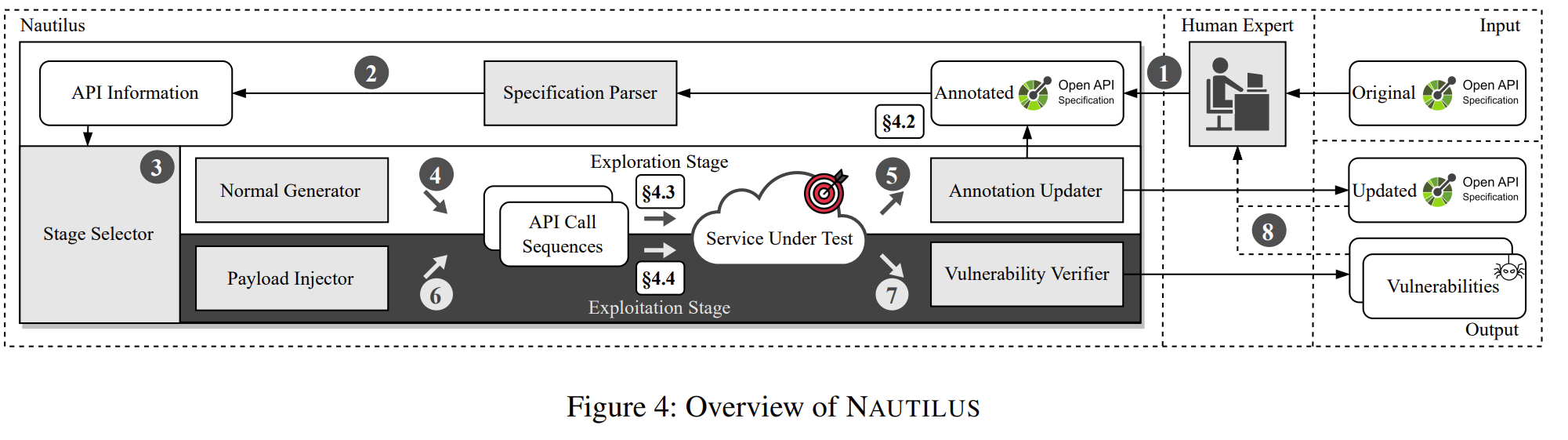
可以看到 NAUTILUS 整体输入是待测项目的 OpenAPI 规范,而总体输出是带有定制注释的更新的 OpenAPI 规范以及检测到的漏洞,NAUTILUS 的工作流程包括三个阶段:注释处理,两阶段测试以及结果处理,下面我们来分析分析。
注释处理
在测试开始前,使用者可以为待测项目提供的原始 OpenAPI 规范添加注释,这些注释需遵循 NAUTILUS 的设计规范,确保机器可解析且人类易读。在 NAUTILUS 自动生成注释之后,用户也可以根据业务知识对注释进行补充或修改。
借助这些带注释的规范,NAUTILUS 能通过其解析器提取 API 的结构信息,包括各接口之间的依赖关系以及每个接口的参数细节
两阶段测试
NAUTILUS 的测试过程分为两个阶段:探索阶段和利用阶段,这两个阶段会循环交替执行,这里他设定了一个预定义时间阈值t,若时间阈值后仍未成功请求任何端点,则NAUTILUS从探索阶段切换到利用阶段,同样的,如果阈值时间之后没能利用成功, NAUTILUS也会利用阶段切换回探索阶段。
在探索阶段,NAUTILUS 通过分析注释提取到的 API 信息,自动构造调用序列,目标是成功调用尽可能多的 POST 或 PUT 类型的接口。调用序列中的参数将根据注释策略自动填充。在此过程中,NAUTILUS 会根据执行反馈不断完善或更新注释,从而提升后续测试的准确性和效率,进一步挖掘新的接口调用路径。
当系统在一定时间内无法成功调用新的接口,或所有接口均已访问过时,NAUTILUS 会切换至利用阶段。在利用阶段,NAUTILUS 会将预定义的 payload 注入到探索阶段构造的成功接口调用路径中,并根据被测系统的反馈判断是否存在漏洞。
结果处理
测试完成后,NAUTILUS 会输出两类结果:
- 自动更新后的 OpenAPI 规范(包含结构化注释)
- 检测到的漏洞报告
这两部分内容可供用户进一步分析和验证,辅助开发者修复潜在风险。
注释规范
NAUTILUS的注释设计既容易被人类理解,也容易被自动处理,完全兼容OpenAPI 3.0 标准,目的是在 OpenAPI 规范中嵌入更多信息,主要是两种类型的注释——操作注释和参数注释,作者这里给出了示例:
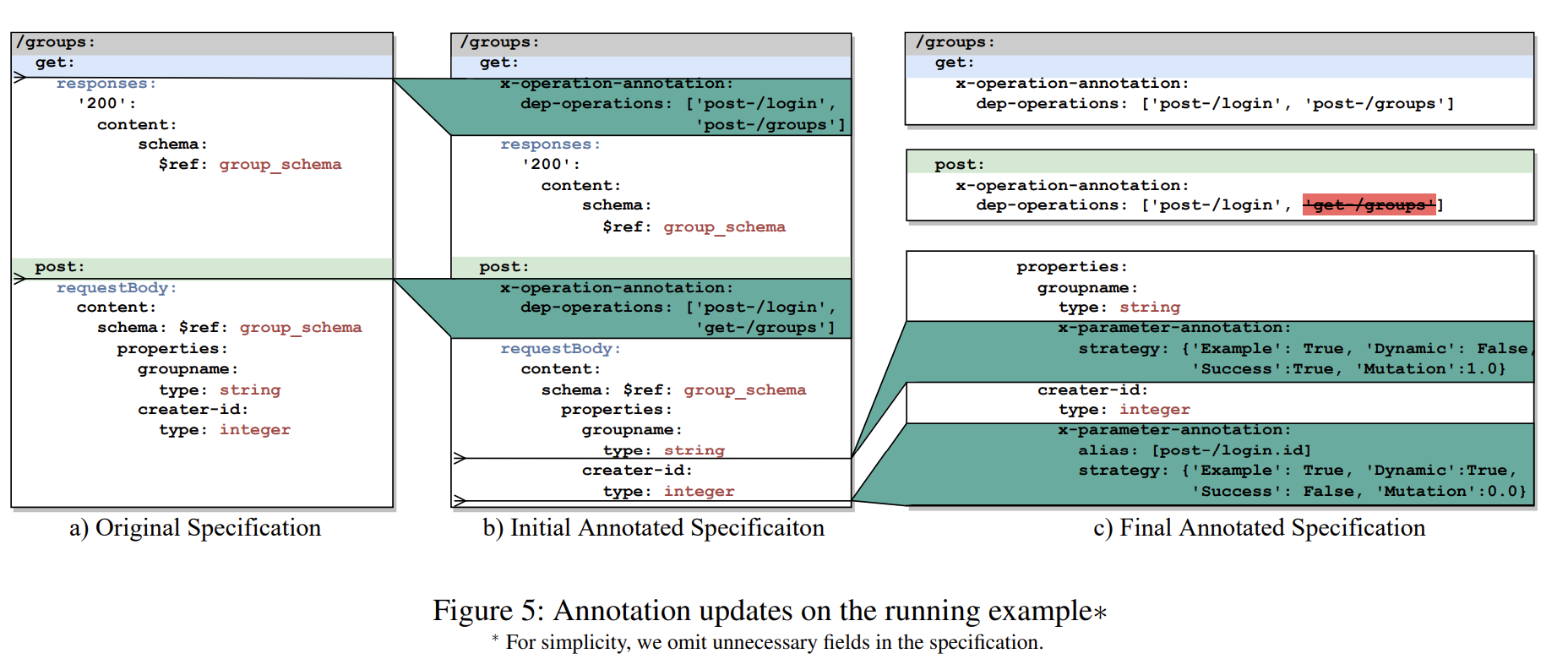
操作注释
操作注释用于描述接口与接口之间的调用关系、逻辑依赖,帮助 NAUTILUS 构建合法的调用序列。在图里我们可以很明显的看到用绿框框圈出来了多的几个部分,比如GET这里:
x-operation-annotation:
dep-operations: ['post-/login', 'post-/groups']x-operation-annotation 是 OpenAPI 的扩展字段,其中 dep-operations 表示当前操作依赖于哪些先前的操作完成之后才能合法执行,格式是一个字符串列表,每项表示方法 + 路径,比如这里 ‘post-/login’ 就表示必须先调用 /login 接口。在POST这里也有类似的逻辑,这里他的dep-operations就是[‘post-/login’, ‘get-/groups’]
这里的操作依赖关系主要有三种:参数数据依赖、CRUD 依赖和逻辑依赖。
- 参数数据依赖:指的是一个 API 的 响应结果中的某些变量,被用作另一个 API 的请求参数的情况,比如get-/groups 被标记为 post-/groups 的依赖操作就是出于这个原因,二者都使用了group_schema,说明get-/groups 可能提供了 post/groups 所需的数据字段。
- CRUD 依赖关系:主要为了强制执行 CRUD 限制并根据 CRUD关系链接操作。比如图里 post-/groups被标记为get-/groups的依赖操作,因为按照 CRUD 关系,应该先创建⼀个组,然后才能读取它。(不过参数数据依赖和CURD 依赖关系是有可能产生矛盾的,比如这里post-/groups是get-/groups的依赖,get-/groups又是post-/groups的依赖,岂不是死循环了)
- 逻辑依赖:指由系统里内部逻辑引⼊的依赖关系。比如图里post-/login是get-/groups和post-/groups的依赖操作。原因是post-/login可以返回⼀个nonce,它是标头中⽤作访问其他 API 端点的⾝份令牌的必需参数。
除此之外还有个Term-operation,但是图里没看到,主要是注释与终止会话有关的操作,比如假设Term-operation里有个logout接口,显然你测试的时候应该把他放在最后测试而不是插到中间。在这里还引入了一个alias,也就是别名机制,格式为 {操作}.{参数名称},并指向特定操作的参数,比如图里的[post-/login.id],就表示这个接口以id作为参数。
参数注释
参数注释用于描述请求中参数的生成方式、依赖来源和 fuzzing 策略,用于精准生成符合逻辑的 payload,同时支持漏洞检测,为了解决参数值的随机性和正确性,作者这里设计了四个字段进行描述:
- Example:是否使⽤ OpenAPI 规范中记录的参数值
- Dynamic:是否从先前成功请求的操作中按相同顺序获取相应的参数值
- Success:是否使⽤上次成功请求的参数值
- Mutation:Mutation是一个浮点数,取值范围从 0.0 到 1.0,表示参数值的“变异程度”,值越大表示系统越容忍变异后的参数,表示我们可以狠狠fuzz的程度
参数值的最终生成方式最终由四个字段共同作用决定的,Dynamic 优先级最高,Example 优先级最低。
注释更新
在测试 RESTful API 的时候,NAUTILUS 要知道:
- 哪些接口依赖其他接口(比如先登录才能获取信息)
- 某些参数来自其他操作(比如 token、用户 ID)
- 哪些参数可以 fuzz(变异)、哪些需要用示例值
所以它需要在测试前和测试中,维护一套注解系统来告诉自己:怎么调用每个接口、怎么构造请求参数,主要有两个阶段:注解初始化 + 手动更新和测试过程中的动态更新。
注解初始化 + 手动更新
在测试一开始,NAUTILUS 提供一个工具来自动生成初始注解,你也可以手动修改注解来更贴合业务语义,但这一步也可以完全跳过。系统会根据参数之间的数据依赖关系(比如响应字段是否匹配请求参数结构)以及一些启发式规则(比如接口路径里有 “login” 就认为是登录接口)来自动给 OpenAPI 文件中的接口加上注解(如图里的 x-operation-annotation, x-parameter-annotation)。当然,作为使用者的我们也可以根据自己的业务知识,对这些注解进一步完善或修正,只要格式正确即可。
测试过程中的动态更新
在测试运行时,NAUTILUS 会根据真实执行结果,动态修正注解,以让整个调用路径更真实、有效、合理,主要就是对于操作注解和参数注解的更新。
操作注解的更新有三种更新情况:
- OpenAPI 文档没写响应体。比如有些接口官方标准里没有写明返回的字段,NAUTILUS就会去发请求看看最后发送了什么字段;或者如果有些字段在别的接口作为请求参数用了 ,那就自动建立起参数依赖关系。
- 自动识别参数值之间的别名关系。比如
POST /groups需要一个creator-id,而GET /members/me返回一个id,文档里没说它们是同一个参数,但实际运行发现只有当creator-id == id时,创建群组才成功,那么 NAUTILUS 会认定这两个参数是别名。 - 删掉无效的依赖链。在调用了某个依赖若干次之后(默认是 10 次)仍然失败,就认为这个依赖可能是错误的,会删掉,比如之前
POST /groups和GET /groups之间的死循环依赖。
参数注解的更新策略会稍微简单一点,在成功请求之后 Mutation 字段会增加(认为服务端可以接收更大的变异参数),Success 字段更新为 True,失败请求之后 Mutation 字段会降低,使用粒度更⼩的变异来保证参数的正确性。
探索阶段
探索阶段 NAUTILUS 的目标是构造尽可能多能成功调用的 API 操作序列,为后续漏洞扫描做好准备,因此它的原则就是只探索有价值的接口,比如那些可能存在漏洞的接口,像是存在用户输入的、能改服务器数据的接口等等,在这期间他会递归构建 API 操作序列,比如如果接口 A 依赖接口 B,就先调用 B,再调用 A(用 dep-operations 构建依赖链),然后会基于注解生成参数(示例、变异、别名取值等等),按顺序依赖逐个请求(毕竟是有操作顺序的),最后通过 API 是否返回 2xx 响应来判断是否调用成功,并据此更新注解。
和一般的漏扫相比它的优越性确实强一点,毕竟 NAUTILUS 只测试有攻击价值的接口,而不是所有接口,而且它会据运行反馈动态选择最佳参数生成策略,而不是通过某个写死的规则。
利用阶段
当无法再成功发现新接口,或所有接口都已成功调用时,NAUTILUS 进入利用阶段,目标就是在已探索的调用路径基础上,尽可能发现漏洞。
首先,它会收集成功的调用序列,NAUTILUS 会把探索阶段中那些能成功调用目标接口的 API 调用序列记录下来这些将作为漏洞利用的测试样本路径。构造请求时存在两种参数处理方式,对于存在依赖的 API 操作(比如登录、获取 token),会使用上次成功请求的参数值(从注解中提取),而对于目标攻击操作(如创建对象、上传内容),它会使用预定义的漏洞 payload 替换其参数值,测试的时候会根据不同漏洞类型使用不同的payload,比如XSS、SQLi、命令注入会有一个对应的payload集合。
这里文章介绍了它的注入机制:
基于漏洞的参数变异。核心就是不是盲目地注入 payload,而是精准地变异真正可注入的参数,它会识别可注入参数(那些不是从前面 API 响应中继承的参数,即dynamic = False的参数),定位包含这些参数的接口为候选操作,如果是 GET 请求就使用探索阶段已有序列,把 URL 参数替换为 payload,如果是 POST/PUT 请求就随机选一个 CURD 相关的 GET 接口插入序列(用于获取数据 or 验证)。
如何判断注入是否成功。不同类型的 payload,需要用不同方式判断是否成功触发漏洞,被称为“oracle”机制,主要就是状态码变化(登录绕过后从400变成200),返回结构变化(SQL注入后返回了额外的数据),语义关联(payload 是 1+1,结果返回 2,说明命令被执行了)
实施与评估
作者基于 Python 3.9.0 实现了 NAUTILUS,代码量为 6,500 行,并进行了实验以评估其性能,主要针对的问题如下:
- RQ1(漏洞检测)NAUTILUS 的漏洞识别能力如何?
- RQ2(覆盖率)NAUTILUS 的操作探索能力如何?
- RQ3(消融研究)注释策略对 NAUTILUS 的性能有何影响?
- RQ4(真实目标)NAUTILUS 能否识别真实应用中(包括工业产品)的漏洞?
RQ1 识别能力
作者与现有的一些的漏扫工具进行了对比实验,虽然我一个也没听说过,主要是ZAP、w3af、RESTLER和MORES。测试的目标是三个基准应用程序(出于教育目的故意被植入漏洞的应用程序):OWASP NodeGoat 、OWASP JuiceShop 和 VAmPI 和三个具有良好 RESTful API 端点的正常的开源程序。
在测试结果中,NAUTILUS 明显优于其他基线工具(如 ZAP、w3af、RESTLER),它能发现更多类型的漏洞:SQL 注入、命令注入、XSS、权限管理等。具体而言,在三个教育性测试系统中,NAUTILUS 比其他方案多发现了平均 69.8%的漏洞,在三个真实系统中发现了 10 个 0day 漏洞,而其他工具只发现了 3 个。
对于为什么该工具效果这么好,作者解释说是因为传统工具多数只能单接口测试,无法处理多步骤依赖,并且基线方案使用的是相同 payload 字典 + 类似策略,而 NAUTILUS 可以进行动态的调整而非写死的逻辑。
在具体的测试中,NAUTILUS 的假阳性率为 24.74%,与其他工具相当,出现假阳性主要是因为接口实现不标准导致触发了错误的判断,或者服务行为异常导致 crash 但并非真正可利用,这一点可以通过完善 OpenAPI 文档来减少假阳性。
而在假阴性的分析中 NAUTILUS 的效果要好的多,在对 50 个已知 CVE 测试中,NAUTILUS 成功识别了其中的 70%,明显优于其他工具(平均 39.5%),主要是因为 NAUTILUS 能覆盖更多的端点。部分漏洞没有覆盖到是是因为payload 字典未覆盖或者服务实现不符合标准导致判断失效。
总而言之,NAUTILUS 在覆盖率和检测能力上明显优于传统方案,能识别更多真实漏洞和 0day,同时具备较低的假阳性与合理的漏报率。其优势来自于对接口依赖关系的理解与注解驱动的测试策略。
RQ2 覆盖率
在接口覆盖率方面,NAUTILUS 显著优于其他工具,比传统漏洞扫描器(如 ZAP、w3af)多覆盖了 163.1% 的端点,甚至比 RESTful API 专用工具(如 RESTLER、MOREST)分别高出 54.8% 和 36.9%。
传统工具无法生成有效的 POST / PUT 请求,难以和接口正确交互,而普通的 RESTful 工具不理解多步骤逻辑(如登录-登出流程),难以生成格式严格的参数(比如邮箱、UUID),缺乏对复杂用例的调用顺序建模,因此NAUTILUS 凭借注解驱动和依赖感知策略,在接口覆盖率上大幅领先传统和现有 RESTful 工具,尤其擅长处理多步骤操作和格式受限的参数。
RQ3 消融实验
为了评估注解策略对 NAUTILUS 整体性能的提升作用,作者设计了消融实验,创建 3 个变体版本进行对比:
- NAUTILUS-PARAMETER-ONLY:只保留参数注解,去掉操作注解
- NAUTILUS-NO-ANNOTATION:不使用任何注解
- NAUTILUS-OPERATION-ONLY:只保留操作注解,去掉参数注解
完整版 NAUTILUS 明显优于所有变体,在漏洞检测和接口覆盖上都更好,完全去掉注解(NO-ANNOTATION)后性能下降,甚至略低于 RESTLER 和 MOREST,因为探索策略忽视了端点间的关系,且缺少参数注解会导致语法错误和参数对不上的问题;操作注解更关注于接口调用顺序复杂的系统如 Juice Shop 中需要登录、权限操作等逻辑链;参数注解更关注于参数格式严格的系统如 SeoPanel 中邮箱、UUID、token 等必须格式正确才能成功调用接口。
作者观察发现,每个服务平均生成 15.3 条注解(每个端点约 0.66 条),接口调用序列最长可达 5.3 步,并且 67% 的漏洞只能通过使用注解发现,因此注解机制对提升漏洞发现和接口覆盖率至关重要。
RQ4 真实目标
NAUTILUS 在多个真实 RESTful 应用中识别出 23 个独立漏洞,其中 21 个已被厂商确认,包括开源项目(如 SeoPanel、Navigate CMS),也包括商业产品(如 Microsoft 和 Atlassian 的服务),并且提交 MITRE获得了 10 个 CVE 编号。
一个案例就是 Gila CMS 的多接口存储型 XSS,这个漏洞需要普通用户登录后通过 fm/upload 上传带 XSS payload 的文件名,接着接口响应返回生成的 blog ID,用户再通过 GET 请求查看内容时,XSS 被触发,涉及 POST 注入 + GET 触发,属于典型的多步骤 API 漏洞。
另一个案例是 Atlassian Confluence 的 OGNL 注入漏洞,这个漏洞需要攻击者创建账号并启用 API 服务,然后用 POST /doEditDailyBackupSettings 向 dailyBackupFilePrefix 参数注入 '{222*3}' 等 payload,最后再用 GET 获取结果,如果发现返回值为 666,说明 payload 被执行。
作者这里特意提到,有些漏洞必须通过注解引导参数生成才能被发现,在 23 个 0day 漏洞中,有 7 个必须依赖手动注解,特别适用于需要从 CLI 或外部接口动态获取参数的复杂系统。
总结
NAUTILUS 提供了一种结构化、自动化、支持多接口组合测试的 REST API 漏洞检测新方法,极大提升了对复杂逻辑、深层接口、组合攻击路径的识别能力,弥补了传统工具只支持单点 fuzz 的缺陷。