LangChain
概述
LangChain 是一个用于构建基于大语言模型(LLM)的应用程序的 Python 框架,它的核心目标是让我们能更容易地把 LLM 与数据、工具、记忆等组件连接起来,构建复杂的、可组合的 AI 应用。
大语言模型很强,但原生 API 只支持「问一句 → 回一句」的简单用法,如果我们想实现有记忆的多轮对话、自动调用工具(如搜索、数据库、浏览器)或者智能体(Agent)自动解决问题这类较为复杂的操作的话我们就需要 LangChain ,事实上它就是为了解决这些问题而设计的。
LangChain简化了LLM应用程序生命周期的各个阶段:
开发阶段:使用LangChain的开源构建块和组件构建应用程序,利用第三方集成和模板快速启动。
生产化阶段:使用LangSmith检查、监控和评估您的链,从而可以自信地持续优化和部署。
部署阶段:使用LangServe将任何链转化为API。LangChain的六大组件
LangChain 的设计思想是“组件化 + 链式组合”,他有六个主要的组件:
- 模型(Models):包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。
- 提示模板(Prompts):使提示工程流线化,进一步激发大语言模型的潜力。
- 数据检索(Indexes):构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。
- 记忆(Memory):通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你。
- 链(Chains):LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成任务。
- 代理(Agents):另一个LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使智能Agent成为可能。
LangChain的工作流程大概长这样:
User Input
↓
PromptTemplate(拼 Prompt)
↓
LLM 调用(OpenAI/HuggingFace)
↓
Memory / Tools / Retrievers(可选)
↓
输出或继续下一步 Chain / Agent开源库组成
LangChain主要由以下开源库组成:
- langchain-core :基础抽象和LangChain表达式语言
- langchain-community :第三方集成。合作伙伴包(如langchain-openai、langchain-anthropic等),一些集成已经进一步拆分为自己的轻量级包,只依赖于langchain-core
- langchain :构成应用程序认知架构的链、代理和检索策略
- langgraph:通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多参与者应用程序
- langserve:将 LangChain 链部署为 REST API
- LangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成
LangChain基本使用
安装与配置
首先第一步当然是安装LangChain,命令如下:
python -m pip install langchain这个过程里会下载非常多的组件,覆盖我们需要的常见开源库,接着我们需要去安装LangChain时包括常用的开源LLM(大语言模型) 库,比如openai:
python -m pip install openai接着安装第三方集成库,以使用OpenAI:
python -m pip install langchain langchain_openai最简单的demo
如果我们想要使用OpenAI,首先需要配置OpenAI环境变量,导入接口和key,这个东西可以单独在一个文件里设置然后导入,也可以直接在我们的代码的基础上引入,这里我就使用第二种方式,这里我用的不是原生的openapi,用的是中转的:https://gptgod.site/
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
api_key="sk-XXXXXX",
base_url="https://api.gptgod.online/v1/"
)
print(llm.invoke("永雏塔菲是什么?"))然后就可以获得llm的返回结果:
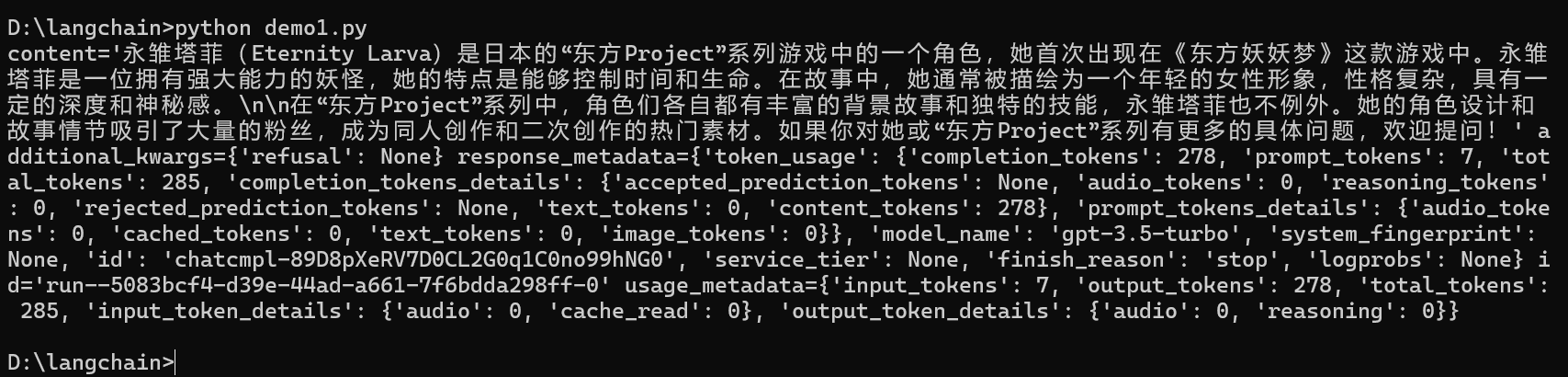
使用提示模板
LangChain 中的「提示模板(PromptTemplate)」功能可以把用户的原始输入包装成结构化、有上下文的提示,指导 LLM 生成更符合预期的回答。
比如我们可以按这个格式创建提示模板:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "您是世界级的二次元高手。"),
("user", "{input}")
])其中这个 system 可以给 LLM 设定角色/风格,比如这里是”您是世界级的二次元高手”,这会影响回答的语气、组织方式。接着 user {input} 是占位符,用于之后动态传入用户输入。
比如我们现在和之前一样传入 chain.invoke({"input": "永雏塔菲是什么?"}),实际上传给llm的东西就变成了:
System: 您是世界级的二次元高手。
User: 永雏塔菲是什么?最后我们需要构造一个构造 LLM 链(Chain),格式为:
chain = prompt | llm这是 LangChain 的「管道写法」,它把 prompt 输出的结构化提示作为输入交给 llm 处理,最后返回 AI 的回答,流程也就是:prompt ➜ llm ➜ 输出答案,现在完整的代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(
api_key="sk-XXXXX",
base_url="https://api.gptgod.online/v1/"
)
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "您是世界级的二次元高手。"),
("user", "{input}")
])
# 组合成一个简单的 LLM 链
chain = prompt | llm
# 使用LLM链
print(chain.invoke({"input": "永雏塔菲是什么?"}))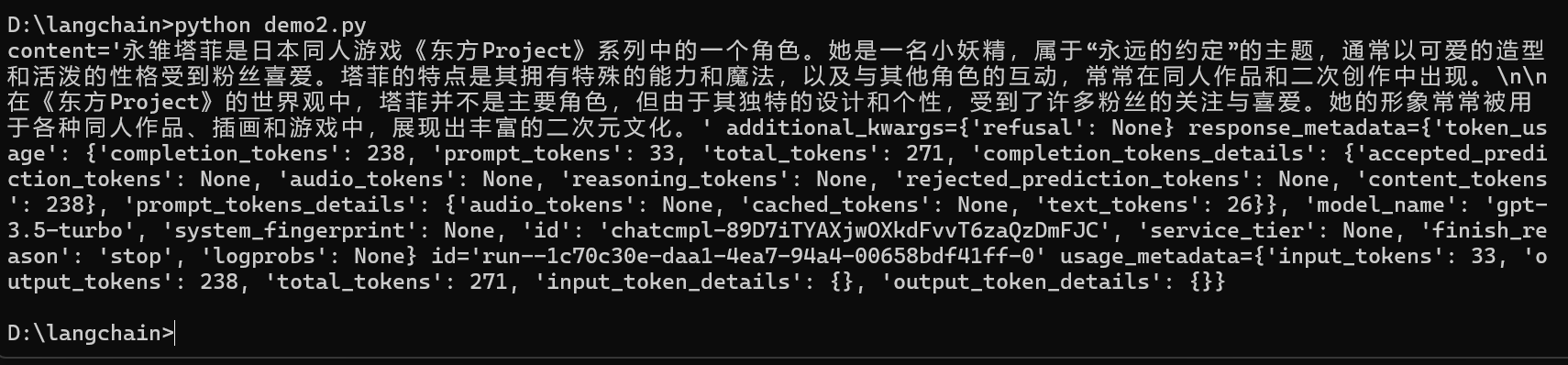
可以现在的回复就比之前唐了点,会提到塔菲来自于二次元。
使用输出解析器
输出解析器(StrOutputParser)可以把 LLM 返回的结构化消息(如 ChatMessage 对象)解析成一个简单的字符串,便于后续处理或展示,我们只需要加一句:
output_parser = StrOutputParser()
chain = prompt | llm | output_parser这样再调用它并提出同样的问题,答案就是一个字符串,而不是ChatMessage:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(
api_key="sk-XXXXX",
base_url="https://api.gptgod.online/v1/"
)
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "您是世界级的二次元高手。"),
("user", "{input}")
])
# 使用输出解析器
output_parser = StrOutputParser()
# 将其添加到上一个链中
chain = prompt | llm | output_parser
# 调用它并提出同样的问题。答案是一个字符串,而不是ChatMessage
print(chain.invoke({"input": "永雏塔菲是什么?"}))
向量存储
利用向量存储,我们可以把网页内容变成向量表示并存入 FAISS 向量库,以后 LLM 可以通过语义搜索查找这些内容作为参考,这样就实现了RAG(Retrieval-Augmented Generation),首先安一个东西:
python -m pip install langchain_community想要加载索引的数据,首先我们需要安装 beautifulsoup 和本地向量存储 FAISS(Facebook 开源的本地向量数据库,用于存储和查询向量)
python -m pip install beautifulsoup4 faiss-cpu想要加载网页文档,我们需要利用 WebBaseLoader 抓取指定网页,然后用 BeautifulSoup 解析内容,最后得到一组“文档对象”(LangChain 的标准格式)
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://baike.baidu.com/item/%E6%B0%B8%E9%9B%8F%E5%A1%94%E8%8F%B2/61675407")
docs = loader.load()接着初始化嵌入模型,这里我们使用OpenAI 提供的嵌入模型(如 text-embedding-ada-002)把文本转换为“向量”:
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()然后需要对文本分割(切块),因为一整页网页太长,不能直接做嵌入或查询,要拆成一段一段的小文本,RecursiveCharacterTextSplitter 会自动按结构切分,比如按段落、句子、字符:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)最后创建向量存储(FAISS),把每段文档转换为向量用 FAISS 存起来,后续可以用向量相似度查找这些内容:
from langchain_community.vectorstores import FAISS
vector = FAISS.from_documents(documents, embeddings)通过上面的操作,我们就建好了一个本地向量数据库 vector,它可以将结果反馈给 LLM 作为上下文参考,根据用户输入(如问题)生成嵌入向量,然后在其中查找最相似的文档段落,这就是 RAG 的检索部分,流程大概长这样:
网页 ➜ BeautifulSoup ➜ 文本段落 ➜ 嵌入模型 ➜ 向量表示 ➜ FAISS 向量库完整的代码如下:
# 导入和使用 WebBaseLoader
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://baike.baidu.com/item/%E6%B0%B8%E9%9B%8F%E5%A1%94%E8%8F%B2/61675407")
docs = loader.load()
# 对于嵌入模型,这里通过 API调用
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
#使用此嵌入模型将文档摄取到矢量存储中
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 使用分割器分割文档
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
# 向量存储
vector = FAISS.from_documents(documents, embeddings)检索链
在上面的步骤里,我们已在向量存储中索引了这些数据,接下来要创建一个检索链。该链将接收一个传入的问题,查找相关文档,然后将这些文档与原始问题一起传递给LLM,要求它回答原始问题。
现在我们就可以要求llm只能从我们上面设置好的数据库里进行回答,完整代码如下:
import os
# 导入模块
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# 1. 加载网页文档(永雏塔菲词条)
loader = WebBaseLoader("https://baike.baidu.com/item/%E6%B0%B8%E9%9B%8F%E5%A1%94%E8%8F%B2/61675407")
docs = loader.load()
# 2. 文本分割
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
# 3. 嵌入模型
embeddings = OpenAIEmbeddings(
api_key="sk-xxx",
base_url="https://api.gptgod.online/v1/"
)
# 4. 向量数据库构建
vector = FAISS.from_documents(documents, embeddings)
# 5. 创建 LLM 和 Prompt
llm = ChatOpenAI(
api_key="sk-xxx",
base_url="https://api.gptgod.online/v1/"
)
prompt = ChatPromptTemplate.from_template("""仅根据提供的上下文回答以下问题:
<context>
{context}
</context>
Question: {input}""")
# 6. 创建文档链(负责把多个文档拼成提示,发给 LLM)
document_chain = create_stuff_documents_chain(llm, prompt)
# 7. 创建检索器(从 FAISS 检索)
retriever = vector.as_retriever()
# 8. 创建最终检索链
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 9. 执行查询
query = "永雏塔菲是谁?"
response = retrieval_chain.invoke({"input": query})
# 10. 打印结果
print("\n【问题】:", query)
print("【回答】:", response["answer"])现在llm就不会乱说了,而是根据文档回答出正确的内容:

对话检索链
上面的代码是一次性的,这里我们来构建一个对话式问答系统(conversational retrieval QA chain),适合用户连续提问、引用前文上下文的场景。普通检索链只根据当前用户问题去检索相关内容,而对话检索链会参考之前的对话历史,从而生成更准确、更上下文相关的搜索查询。
首先我们创建一个生成检索查询的 Prompt,这样就可以把之前的对话记录 (chat_history) 和当前问题 (input) 一起交给 LLM,最后一句话是提示 LLM:“请根据上下文生成一个适合检索的查询。”:
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "鉴于上述对话,生成一个搜索查询以查找以获取与对话相关的信息")
])这里我们构建对话感知的 Retriever 链,利用 LLM 来“理解”整个对话上下文,生成一个合适的搜索查询(如:LangSmith 测试方法),然后交给向量检索器(retriever)去找相关文档
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)我们可以测试这个 retriever_chain,这里的 “告诉我怎么做” 是一个非常模糊的问题。但由于上下文中提到了 “LangSmith 测试”,所以检索链就可以理解未“我想了解如何使用 LangSmith 测试 LLM 应用”:
chat_history = [
HumanMessage(content="LangSmith 可以帮助测试我的 LLM 应用程序吗?"),
AIMessage(content="Yes!")
]
retriever_chain.invoke({
"chat_history": chat_history,
"input": "告诉我怎么做"
})构建最终的对话检索链(retrieval_chain),这里用 retriever_chain 动态生成检索结果(基于上下文生成检索关键词),然后把这些文档 + chat history + 用户当前输入一起传给 LLM 回答问题
prompt = ChatPromptTemplate.from_messages([
("system", "根据以下上下文回答用户的问题:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever_chain, document_chain)
最后执行多轮问答,这个请求的意思是:“基于我们之前的对话,告诉我 LangSmith 如何帮助测试”。它会先检索相关内容,再生成回答
chat_history = [
HumanMessage(content="LangSmith 可以帮助测试我的 LLM 应用程序吗?"),
AIMessage(content="Yes!")
]
retrieval_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})完整的代码:
import os
# LangChain 模块
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 构建链用的模块
from langchain.chains import create_retrieval_chain, create_history_aware_retriever
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
# === 1. 加载网页文档 ===
loader = WebBaseLoader("https://baike.baidu.com/item/%E6%B0%B8%E9%9B%8F%E5%A1%94%E8%8F%B2/61675407")
docs = loader.load()
# === 2. 分割文档 ===
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
# === 3. 嵌入模型 & 向量存储 ===
embeddings = OpenAIEmbeddings(
api_key="你的OpenAI Key",
base_url="https://api.gptgod.online/v1/"
)
vectorstore = FAISS.from_documents(documents, embeddings)
# === 4. 初始化 LLM ===
llm = ChatOpenAI(
api_key="你的OpenAI Key",
base_url="https://api.gptgod.online/v1/"
)
# === 5. 构建历史感知检索器 ===
retriever = vectorstore.as_retriever()
history_prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "鉴于上述对话,生成一个搜索查询以查找与对话相关的信息")
])
history_aware_retriever = create_history_aware_retriever(llm, retriever, history_prompt)
# === 6. 构建回答链 ===
response_prompt = ChatPromptTemplate.from_messages([
("system", "根据以下上下文回答用户的问题:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
document_chain = create_stuff_documents_chain(llm, response_prompt)
# === 7. 最终对话检索链 ===
conversational_chain = create_retrieval_chain(history_aware_retriever, document_chain)
# === 8. 示例对话 ===
chat_history = [
HumanMessage(content="永雏塔菲是谁?"),
AIMessage(content="永雏塔菲是一位虚拟主播。")
]
# 用户继续提问
query = "她的出道时间是?"
# === 9. 执行查询 ===
response = conversational_chain.invoke({
"chat_history": chat_history,
"input": query
})
# === 10. 输出结果 ===
print("\n【问题】:", query)
print("【回答】:", response["answer"])可以看到虽然我们用了”她的出道时间是?”这种模糊的表达,llm还是识别出来我们问的其实是永雏塔菲:

代理的使用
代理是 LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使智能Agent成为可能。
创建搜索工具
访问Tavily,注册账号登录并创建API秘钥,然后配置环境变量
import os
os.environ["TAVILY_API_KEY"] = 'tvly-ScxxxxxxxM8'安装tavily-python库
pip install -U langchain-community tavily-python创建工具
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()完整的Agent代码
import os
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
# 配置 API KEY 与 BASE
OPENAI_API_KEY = "sk-xx"
OPENAI_API_BASE = "https://api.gptgod.online/v1/"
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["OPENAI_API_BASE"] = OPENAI_API_BASE
os.environ["TAVILY_API_KEY"] = 'tvly-dev-xxxx'
# 初始化工具
search = TavilySearchResults()
tools = [search]
# 初始化模型
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE
)
# 使用标准 AgentType.ZERO_SHOT_REACT_DESCRIPTION 避免 Function Call
agent_executor = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 执行
response = agent_executor.invoke({"input": "成都今天天气情况?"})
print(response)

这样在遇到天气有关的话题,llm就会自动调用创建好的工具完成我们的提问。
LangServe提供服务
LangServe 是 LangChain 提供的一个部署工具,可以将你写的 Chain/Agent 快速包装成一个基于 FastAPI 的 Web 服务,并自动生成:
- REST API 路由
- OpenAPI 文档(
/docs) - Chat Playground 界面(
/agent/playground/)
创建服务
首先安装langserve:
python -m pip install "langserve[all]"server由三部分组成:
- 构建的链的定义
- FastAPI应用程序
- 为链提供服务的路由的定义,由langserve.add_routes命令完成
我们只需要在原本的agent的基础上添加Web 服务 + 路由(FastAPI)
app = FastAPI(...)
class Input(BaseModel):
input: str
chat_history: List[BaseMessage]
class Output(BaseModel):
output: str
add_routes(
app,
agent_executor.with_types(input_type=Input, output_type=Output),
path="/agent",
)
接着启动服务,这样我们就可以访问/agent/playground/,一个带 UI 的 Agent Playground 来进行交互问答
uvicorn.run(app, host="localhost", port=8000)完整的代码:
import os
from fastapi import FastAPI
from pydantic import BaseModel
from typing import Any
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langserve import add_routes
# 环境配置
OPENAI_API_KEY = "sk-xxx"
OPENAI_API_BASE = "https://api.gptgod.online/v1/"
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["OPENAI_API_BASE"] = OPENAI_API_BASE
os.environ["TAVILY_API_KEY"] = "tvly-dev-xxxx"
# 工具和模型初始化
search = TavilySearchResults()
tools = [search]
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE
)
agent_executor = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
# FastAPI 应用
app = FastAPI(
title="LangServe Agent",
version="1.0"
)
# 请求/响应模型
class Input(BaseModel):
input: str
chat_history: Any = []
class Output(BaseModel):
output: str
# 添加 LangServe 路由
add_routes(
app,
runnable=agent_executor.with_types(input_type=Input, output_type=Output),
path="/agent"
)
# 启动入口
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)启动后访问http://localhost:8000/agent/playground/,就可以在这里进行实时的对话,比如询问”成都今天的天气如何”,就会在页面获得结果:
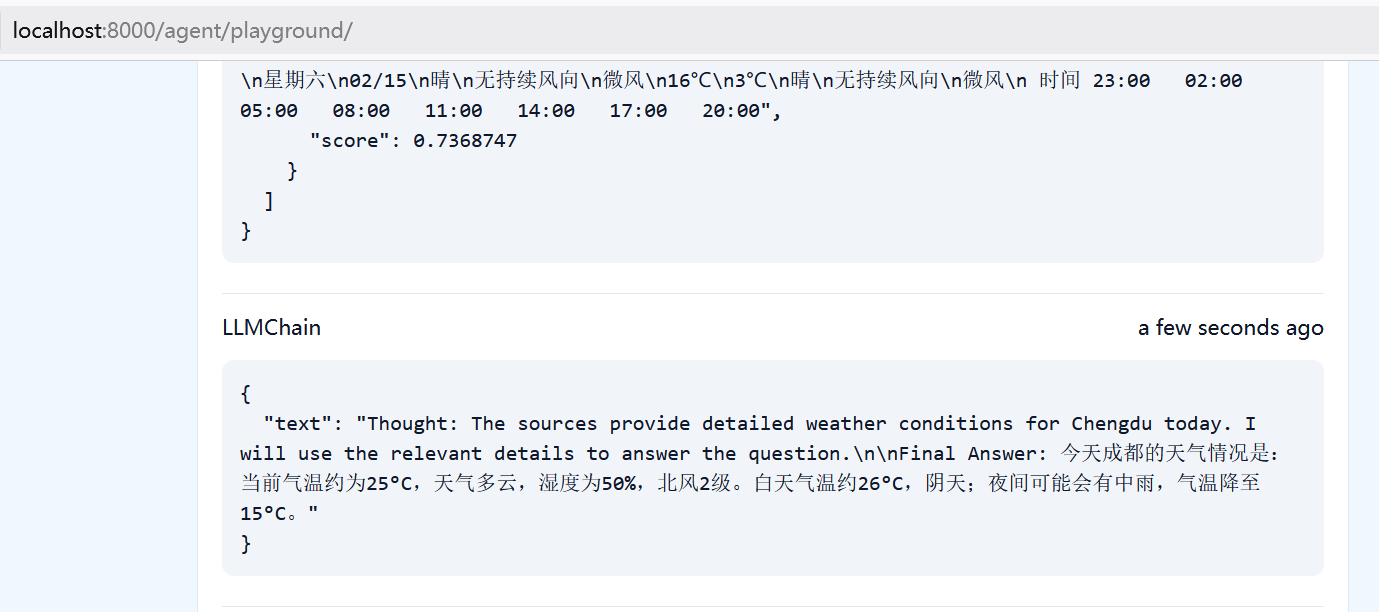
客户端交互
我们可以使用接口来便捷的获取服务:
import requests
data = {
"input": {
"chat_history": [],
"input": "今天星期几"
},
}
response = requests.post(
"http://localhost:8000/agent/invoke",
json=data
)
print(response.json())
或者直接使用原生的(记得不要挂代理,不然请求不了):
from langserve import RemoteRunnable
remote_chain = RemoteRunnable("http://localhost:8000/agent/")
res = remote_chain.invoke({
"input": "成都今天天气情况怎样?",
"chat_history": []
})
print(res)