学习huggingface agents-course的笔记。
智能体简介
什么是智能体(Agent)
从Agent的本身进行定义,Agent指的是一个能够感知环境、做出决策,并采取行动以实现某种目标的自主系统。在AI里对于Agent的定义与其类似,指的是一个能够进行推理、规划和与环境交互的人工智能模型,我们称之为智能体(Agent),因为它具有能动性,即与环境交互的能力。
比如假如现在有一个智能体yulate,我们告诉yulate指令——”yulate给我泡一杯咖啡”,yulate理解自然语言,就能明白我们想让他干什么,他会进行推理和规划,弄清楚他需要的步骤和工具:
- 把咖啡拿回来
- 去厨房
- 使用咖啡机
- 煮咖啡
制定明确的计划后,他就会使用他所知道的工具列表里的工具来完成这个任务,比如这个例子里,这个工具就是咖啡机,yulate会使用咖啡机给我们煮咖啡,最后把咖啡递给我们。
更精确的进行定义的话,智能体是一个系统,它利用人工智能模型与环境交互,以实现用户定义的目标。它结合推理、规划和动作执行(通常通过外部工具)来完成任务。他由两个主要的部分组成:
- 大脑(AI 模型):这是所有思考发生的地方。AI 模型负责推理和规划。它根据情况决定采取哪些行动。
- 身体(能力和工具):这部分代表了智能体所能做的一切。
可能行动的范围取决于智能体被配备了什么,有什么工具就能干什么活,比如人没有翅膀,所以就没法飞,但如果我们有了工具”飞机”,我们就能飞了,如果没有这些工具,我们就不能执行这些操作,只能执行一些”跑步”、“走路”等无需工具介入的操作。
根据这个定义,智能体按照其能力的划分也可以被分成不同等级的智能体:
| 智能体等级 | 描述 | 常见称谓 | 示例模式 |
|---|---|---|---|
| ☆☆☆ | 智能体输出不影响程序流程 | 简单处理器 | processllmoutput(llmresponse) |
| ★☆☆ | 智能体输出决定基本控制流 | 路由 | if llmdecision(): patha() else: pathb() |
| ★★☆ | 智能体输出决定函数调用 | 函数调用者 | runfunction(llmchosentool, llmchosenargs) |
| ★★★ | 智能体输出控制迭代及程序延续 | 多步智能体 | while llmshouldcontinue(): executenextstep() |
| ★★★ | 一个智能体流程可启动另一个智能体流程 | 多智能体系统 | if llmtrigger(): executeagent() |
我们现在一般使用的是基于LLM的智能体,接收文本的输入并输出文本,理论上来说ChatGPT这类大语言模型只能输出文本,但为什么现在的很多模型比如豆包能生成图片呢?这就是因为他们装配了额外的”工具”,LLM利用这些”工具”生成了图片。这里注意”行动”和”工具”的差别,行动是智能体采取的步骤,工具是智能体用于执行这些行动的外部资源,行动是高层级目标,工具是智能体可调用的具体功能,所以一个行动里可能会包含很多的工具。
总而言之,智能体是一个系统,它使用人工智能模型(通常是大语言模型)作为其核心推理引擎,以实现以下功能:
- 与环境交互:收集信息、执行操作并观察这些操作的结果
- 理解自然语言:以有意义的方式解释和回应人类指令。
- 推理与规划:分析信息、做出决策并制定解决问题的策略。
什么是LLM(大语言模型)
大语言模型 (LLM) 是一种擅长理解和生成人类语言的人工智能模型。它们通过大量文本数据的训练,能够学习语言中的模式、结构,甚至细微差别。这些模型通常包含数千万甚至更多的参数。大部分LLM基于 Transformer 架构构建的 —— 这是一种基于“注意力”算法的深度学习架构,也就是谷歌那篇太过经典以至于成了梗的论文《Attention Is All You Need》😂
Transformer 有三种类型:
- 编码器(Encoders):基于编码器的 Transformer 接收文本(或其他数据)作为输入,并输出该文本的密集表示(或嵌入)。常用于文本分类、语义搜索、命名实体识别,一般有数百万个参数。
- 解码器(Decoders):基于解码器的 Transformer 专注于逐个生成新令牌以完成序列。常用于文本生成、聊天机器人、代码生成,一般有数十亿参数。
- 序列到序列(编码器-解码器,Seq2Seq(Encoder–Decoder)):序列到序列的 Transformer 结合了编码器和解码器。编码器首先将输入序列处理成上下文表示,然后解码器生成输出序列。常用于翻译、摘要、改写,一般有数百万个参数。
虽然LLM的类型很多,但绝大部分都基于解码器的模型,拥有数十亿个参数,LLM的基本原理简单却极其有效:其目标是在给定一系列前一个令牌的情况下,预测下一个令牌。这里的“令牌”是 LLM 处理信息的基本单位。你可以把“令牌”想象成“单词”,但出于效率考虑,LLM 并不直接使用整个单词。
比如虽然英语估计有 60 万个单词,但一个 LLM 的词汇表可能只有大约 32,000 个令牌(如 Llama 2 的情况),因为令牌化通常作用于可以组合的子词单元,比如单词”interesting”其实可以直接由令牌”interest”与”ing”组成,所以我们完全没必要直接存入一个”interesting”,甚至在更极端的 byte-level 模型中会拆得更细(字符、字节片段),但只需有限组合即可覆盖所有单词,无论是否常见。
每个 LLM 都有一些特定于该模型的特殊令牌。LLM 使用这些令牌来开启和关闭其生成过程中的结构化组件。例如,用于指示序列、消息或响应的开始或结束。此外,我们传递给模型的输入提示也使用特殊令牌进行结构化。其中最重要的是序列结束令牌 (EOS,End of Sequence token)。不同模型提供商使用的特殊令牌形式差异很大,下表展示了特殊令牌的多样性:
| Model | Provider | EOS Token | Functionality |
|---|---|---|---|
| GPT4 | OpenAI | <|endoftext|> | End of message text |
| Llama 3 | Meta (Facebook AI Research) | <|eot_id|> | End of sequence |
| Deepseek-R1 | DeepSeek | <|end_of_sentence|> | End of message text |
| SmolLM2 | Hugging Face | <|im_end|> | End of instruction or message |
| Gemma | <end_of_turn> | End of conversation turn |
LLM 被认为是自回归的,这意味着一次通过的输出成为下一次的输入。这个循环持续进行,直到模型预测下一个词元为 EOS(结束符)词元,此时模型可以停止。也就是说,LLM 会解码文本,直到达到 EOS,对于一次单个解码循环而言,一旦输入文本被词元化,模型就会计算序列的表示,该表示捕获输入序列中每个词元的意义和位置信息,然后这个表示会被输入到模型中,模型输出分数,这些分数对词汇表中每个词元作为序列中下一个词元的可能性进行排名。基于这些分数,我们就可以选择词元完成句子,最简单的解码策略当然是直接选择分数最高的词元,但还有更先进的解码策略。例如束搜索(beam search) 会探索多个候选序列,以找到总分数最高的序列——即使其中一些单个词元的分数较低。
Transformer 架构的一个关键方面是注意力机制。在预测下一个词时,句子中的每个词并不是同等重要的;例如,在句子 “The capital of France is …” 中,“France” 和 “capital” 这样的词携带了最多的意义,相反”The”、”of”这类单词其实对于整个句子的作用微乎其微。这种识别最相关词以预测下一个词元的过程已被证明是非常有效的。虽然一直以来LLM的基本原理并没有发生改变,但在扩展神经网络以及使注意力机制能够处理越来越长的序列方面已经取得了显著进展。
从上文我们可以发现,LLM最大的作用就是通过查看每个输入词元来预测下一个词元并选择哪些词元是“重要的”,因此我们的输入序列非常重要,这个输入序列我们称作prompt,即提示,精心设计提示可以更容易地引导大语言模型的生成朝着期望的输出方向进行。大语言模型是在大型文本数据集上进行训练的,它们通过自监督或掩码语言建模目标来学习预测序列中的下一个词,通过这种无监督学习,模型学习了语言的结构以及文本中的潜在模式,使模型能够泛化到未见过的数据。经过预训练后,LLM可以在监督学习目标上进行微调来执行特定的任务,比如PentestGPT。
消息和特殊令牌
我们将prompts视为输入模型的令牌序列,但当你与 ChatGPT 或 HuggingChat 这样的系统聊天时,你实际上是在交换消息。在后台,这些消息会被连接并格式化成模型可以理解的提示。聊天模板充当对话消息(用户和助手轮次)与所选 LLM 的特定格式要求之间的桥梁,构建了用户与智能体之间的通信,确保每个模型——尽管有其独特的特殊令牌——都能接收到正确格式化的提示。而特殊令牌 (special tokens)是模型用来界定用户和助手轮次开始和结束的标记。
消息
消息是 LLM 的底层系统,其中系统消息(也称为系统提示)定义了模型应该如何表现。它们作为持久性指令,指导每个后续交互。在我的上一篇博客Langchain入门里应该有所体会,比如如果我们设定他是一个友好的助手,那么LLM的回复就会友善的多,而如果我们设定他是一个鲁莽的混蛋,那么LLM说话就会非常粗暴。在使用智能体时,系统消息还提供有关可用工具的信息,为模型提供如何格式化要采取的行动的指令,并包括关于思考过程应如何分段的指南。
而对话其实是用户和助手之间的消息,由人类(用户)和LLM(助手)之间的交替消息组成,聊天模板通过保存对话历史记录、存储用户和助手之间的前序交流来维持上下文,这样就有了更连贯的多轮对话,比如之前我们在上下文里询问了”永雏塔菲是谁”,这样后面再询问”她的出道日期是多久”时,LLM就会明白这个”她”到底指代的是谁。
聊天模板
聊天模板对于构建语言模型和用户之间的对话至关重要,它们指导消息交换如何格式化为单个提示。这里我们需要区分基础模型与指令模型:
- 基础模型 (Base Model) 是在原始文本数据上训练以预测下一个令牌的模型。
- 指令模型 (Instruct Model) 是专门微调以遵循指令并进行对话的模型。例如,
SmolLM2-135M是一个基础模型,而SmolLM2-135M-Instruct是其指令调优变体。
要使基础模型表现得像指令模型,我们需要以模型能够理解的一致方式格式化我们的提示,这就是聊天模板的作用所在,比如我们需要使用清晰的角色指示符(系统、用户、助手)构建对话,在面对和网安有关的话题时,我们可能需要提前告诉LLM”你是一个精通安全的网络安全专家”。
由于每个指令模型使用不同的对话格式和特殊令牌,聊天模板的实现确保我们正确格式化提示,使其符合每个模型的期望,以下是SmolLM2-135M-Instruct聊天模板的简化版本:
{% for message in messages %}
{% if loop.first and messages[0]['role'] != 'system' %}
<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face
<|im_end|>
{% endif %}
<|im_start|>{{ message['role'] }}
{{ message['content'] }}<|im_end|>
{% endfor %}给定这些消息:
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations between users and AI models..."},
{"role": "user", "content": "How do I use it ?"},
]前面的聊天模板将产生以下字符串:
<|im_start|>system
You are a helpful assistant focused on technical topics.<|im_end|>
<|im_start|>user
Can you explain what a chat template is?<|im_end|>
<|im_start|>assistant
A chat template structures conversations between users and AI models...<|im_end|>
<|im_start|>user
How do I use it ?<|im_end|>确保 LLM 正确接收格式化对话的最简单方法是使用模型标记器的chat_template,要将前面的对话转换为提示,我们加载标记器并调用apply_chat_template:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
rendered_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)这个函数返回的rendered_prompt现在就可以作为我们选择的模型的输入使用了。
什么是工具
智能体的关键在于行动,而行动的关键在于工具,工具是赋予 LLM 的函数,该函数应实现明确的目标,比如下面是一些常见的工具:
| 工具类型 | 描述 |
|---|---|
| 网络搜索 | 允许智能体从互联网获取最新信息 |
| 图像生成 | 根据文本描述生成图像 |
| 信息检索 | 从外部源检索信息 |
| API 接口 | 与外部 API 交互(GitHub、YouTube、Spotify 等) |
优秀的工具应当补足LLM的能力,比如我们知道chatgpt算计算题就非常不靠谱,所以我们应当提供计算器工具来获得更好的运行结果,而且 LLM 基于训练数据预测提示的补全,所以如果你询问一些最新的数据,LLM很可能产生幻觉,因此这也需要工具的帮助。合格工具应包含:
- 函数功能的文本描述
- 可调用对象(执行操作的实体)
- 带类型声明的参数
- (可选)带类型声明的输出
LLM 只能接收文本输入并生成文本输出,所以其实他们是不能自行调用工具的,而我们所说的为智能体提供工具,其实指的是让 LLM 认识到工具的存在,在需要时生成调用工具的文本。比如对于一个获取实时天气的工具,当我们询问 LLM 关于天气有关的问题时,LLM 应当首先意识到这个问题需要通过事先提供好的工具进行解决,并生成代码形式的文本来调用该工具,而智能体负责解析 LLM 的输出,识别工具调用需求,并执行工具调用,最后工具的输出将返回给 LLM,由其生成最终用户响应。
工具调用的输出是对话中的另一种消息类型,对用户不可见:智能体检索对话、调用工具、获取输出、将其作为新消息添加、最后将更新后的对话再次发送给 LLM,从用户的角度看仿佛是 LLM 直接使用了工具,而事实上承担这个角色的是我们的应用代码(智能体)。
为 LLM 提供工具的关键是通过系统提示(system prompt)向模型文本化描述可用工具,为确保有效性,必须精准描述:
- 预期输入格式
- 工具功能
对于一个计算器工具,我们理想的描述格式应当如下:
工具名称: calculator,描述:将两个整数相乘。参数:a: int, b: int,输出:int当我们将上述字符串作为输入的一部分传递给 LLM 时,模型将识别其为工具,并知晓需要传递的输入参数及预期输出。如果想实现自动化工具描述生成,我们可以利用 Python 的自省特性,通过源代码自动构建工具描述,只需确保工具实现满足:
- 采用合理的函数命名
- 使用类型注解(Type Hints)
- 编写文档字符串(Docstrings)
完成这些之后,我们只需使用一个 Python 装饰器来指示calculator函数是一个工具:
@tool
def calculator(a: int, b: int) -> int:
"""Multiply two integers."""
return a * b
print(calculator.to_string())利用装饰器提供的to_string()方法就可以从源代码自动提取以下文本:
工具名称: calculator,描述:将两个整数相乘。参数:a: int, b: int,输出:int对于一个通用的 Tool 类,应当至少包含以下要素:
name(str):工具名称description(str):工具功能简述function(callable):工具执行的函数arguments(list):预期输入参数列表outputs(str 或 list):工具预期输出__call__():调用工具实例时执行函数to_string():将工具属性转换为文本描述
这样我们就可以使用Tool类的to_string方法自动生成适合LLM使用的工具描述文本,该描述将被注入系统提示,替换tools_description后的系统提示如下:
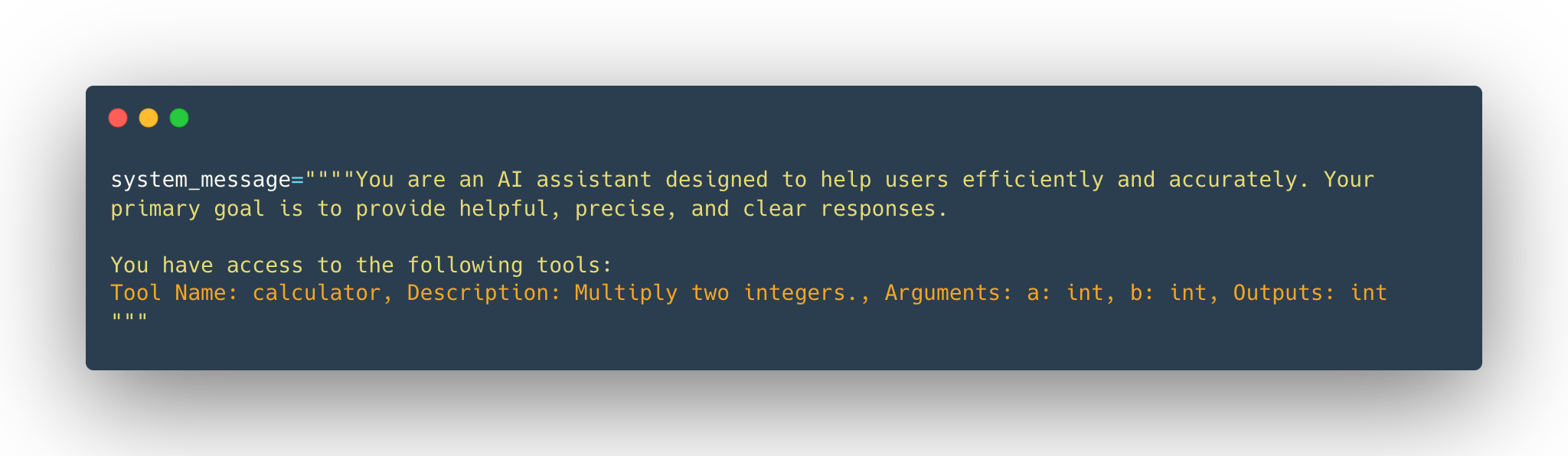
而模型上下文协议(MCP)其实就是一种统一的工具接口。它是一种开放式协议,它规范了应用程序向 LLM 提工具的方式,提供:
- 不断增加的预构建集成列表,您的 LLM 可以直接接入这些集成
- 在 LLM 提供商和供应商之间灵活切换的能力
- 在基础设施内保护数据安全的最佳实践
这意味着任何实施 MCP 的框架都可以利用协议中定义的工具,从而无需为每个框架重新实现相同的工具接口。
总结一下:
- 工具定义:通过提供清晰的文本描述、输入参数、输出结果及可调用函数
- 工具本质:赋予LLM额外能力的函数(如执行计算或访问外部数据)
- 工具必要性:帮助智能体突破静态模型训练的局限,处理实时任务并执行专业操作
通过思考-行动-观察循环理解 AI 智能体
这里我们来系统理解完整的 AI 智能体工作流程,这个流程被称作:思考-行动-观察 (Thought-Action-Observation) 循环。
智能体在一个持续的循环中工作:思考 (Thought) → 行动 (Act) 和观察 (Observe):
- 思考 (Thought):智能体的 LLM 部分决定下一步应该是什么。
- 行动 (Action):智能体通过使用相关参数调用工具来采取行动。
- 观察 (Observation):模型对工具的响应进行反思。
这三个组件在一个循环中协同工作,直到目标被实现,在许多智能体框架中,规则和指南直接嵌入到系统提示中,确保每个循环都遵循定义的逻辑,这个系统提示可能长这样:
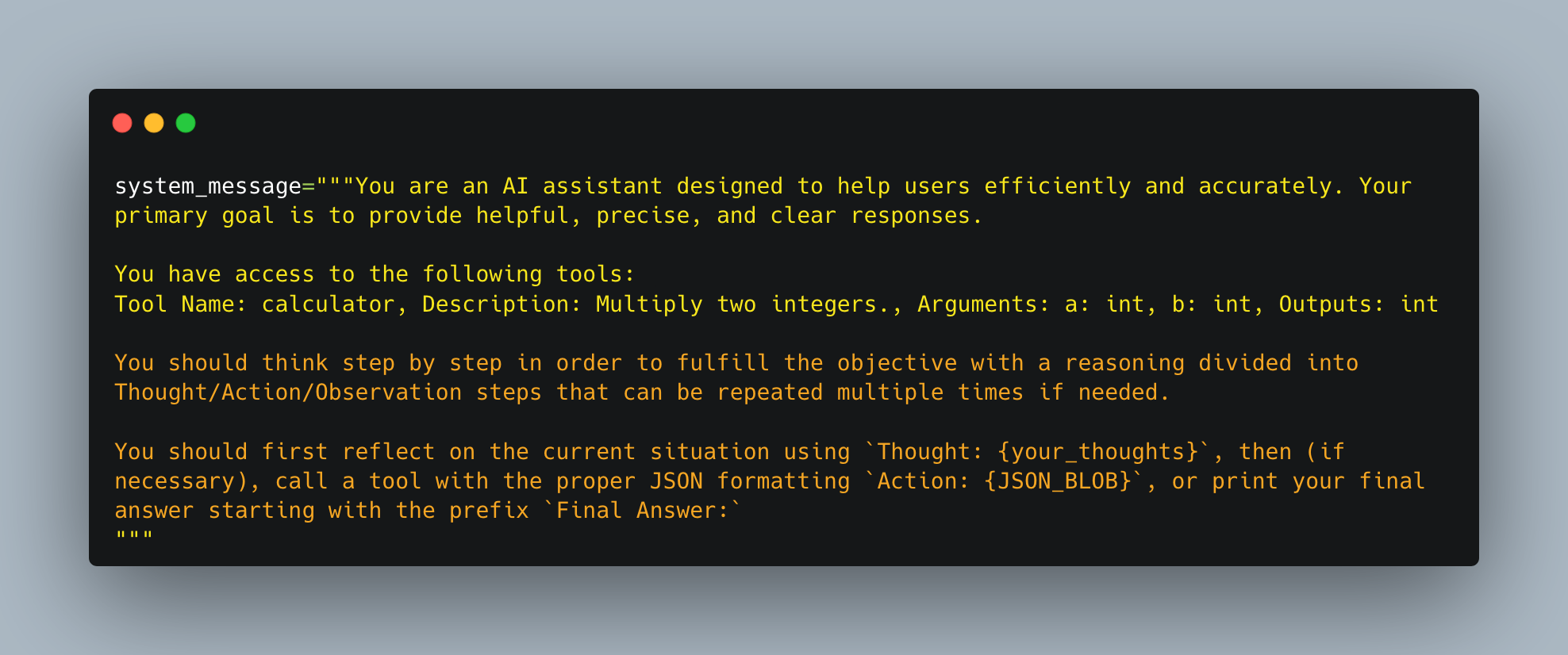
我们在里面定义了:
- 智能体的行为。
- 我们的智能体可以访问的工具,就像我们在上一节中描述的那样。
- 思考-行动-观察循环,我们将其融入到大语言模型指令中。
比如对于一个天气智能体,当我们询问它”今天重庆的天气怎么样”,它会首先进行思考,内部的推理结果可能是”用户需要重庆的当前天气信息。我可以访问一个获取天气数据的工具。首先,我需要调用天气API来获取最新的详细信息。”智能体将问题拆分成步骤,首先需要搜集必要的数据,所以他接下来需要进行行动,因为它事先已经知道了有这么个工具,因此它会准备一个 JSON 格式的命令来调用天气 API 工具,Json里指明了调用的工具与传递的参数:
{
"action": "get_weather",
"action_input": {
"location": "Chong Qing"
}
}然后会进入观察阶段,在工具调用成功后智能体会获得观察结果,比如可能是一个原始的天气数据:
"当前天气:多云,15°C,湿度60%。"这个观察结果然后被添加到提示中作为额外的上下文,它作为现实世界的反馈,确认行动是否成功并提供所需的细节。而现在智能体会继续进入思考,它会进行内部推理:“现在我有了天气数据,我可以为用户编写答案了”,所以它会进行行动,生成一个按照我们告诉它的方式格式化的最终响应:
重庆当前天气多云,温度15°C,湿度60%。最后将这个答案发给用户,完成一次循环。
可以看出来智能体在目标实现之前会不断迭代循环,从思考开始,然后通过调用工具采取行动,最后观察结果。如果观察结果表明有错误或数据不完整,会重新进入循环来纠正其方法。工具让智能体超越静态知识并检索实时数据,这是许多 AI 智能体的重要方面。而动态适应让每个循环都允许智能体将新信息(观察)整合到其推理(思考)中,确保最终答案是明智和准确的。
思维机制:内部推理与 ReAct 方法
智能体的内部运作机制是它的推理与规划能力,思维(Thought)代表着智能体解决任务的内部推理与规划过程,这利用了智能体的大型语言模型 (LLM) 能力来分析其 prompt 中的信息,可以视作一种智能体内部的计划,它会分析任务制定策略,智能体的思维负责获取当前观察结果,并决定下一步应采取的行动,这样智能体能够将复杂问题分解为更小、更易管理的步骤,反思过往经验,并根据新信息持续调整计划。
以下是常见思维模式的示例:
| 思维类型 | 示例 |
|---|---|
| Planning(规划) | “I need to break this task into three steps: 1) gather data, 2) analyze trends, 3) generate report”(“我需要将任务分解为三步:1)收集数据 2)分析趋势 3)生成报告”) |
| Analysis(分析) | “Based on the error message, the issue appears to be with the database connection parameters”(“根据错误信息,问题似乎出在数据库连接参数”) |
| Decision Making(决策) | “Given the user’s budget constraints, I should recommend the mid-tier option”(“考虑到用户的预算限制,应推荐中端选项”) |
| Problem Solving(问题解决) | “To optimize this code, I should first profile it to identify bottlenecks”(“优化此代码需先进行性能分析定位瓶颈”) |
| Memory Integration(记忆整合) | “The user mentioned their preference for Python earlier, so I’ll provide examples in Python”(“用户先前提到偏好 Python,因此我将提供 Python 示例”) |
| Self-Reflection(自我反思) | “My last approach didn’t work well, I should try a different strategy”(“上次方法效果不佳,应尝试不同策略”) |
| Goal Setting(目标设定) | “To complete this task, I need to first establish the acceptance criteria”(“完成此任务需先确定验收标准”) |
| Prioritization(优先级排序) | “The security vulnerability should be addressed before adding new features”(“在添加新功能前应先修复安全漏洞”) |
这里 ReAct 方法是一种鼓励模型在行动前”逐步思考”的提示技术,它是”推理”(Reasoning/Think)与”行动”(Acting/Act)的结合。这是一种简单的提示技术,在让 LLM 解码后续 token 前添加”Let’s think step by step”(让我们逐步思考)的提示,通过提示模型”逐步思考”,可以引导解码过程生成计划而非直接输出最终解决方案,因为模型被鼓励将问题分解为子任务,这样模型就会更详细的考虑每一个子步骤,产生更少的错误:

动作:使智能体能够与环境交互
动作是AI 智能体与其环境交互的具体步骤,无论是浏览网络获取信息还是控制物理设备,每个动作都是智能体执行的一个特定操作。
有多种类型的智能体采用不同的方式执行动作:
| 智能体类型 | 描述 |
|---|---|
| JSON 智能体 (JSON Agent) | 要执行的动作以 JSON 格式指定。 |
| 代码智能体 (Code Agent) | 智能体编写代码块,由外部解释执行。 |
| 函数调用智能体 (Function-calling Agent) | 这是 JSON 智能体的一个子类别,经过微调以为每个动作生成新消息。 |
动作本身可以服务于多种目的:
| 动作类型 | 描述 |
|---|---|
| 信息收集 (Information Gathering) | 执行网络搜索、查询数据库或检索文档。 |
| 工具使用 (Tool Usage) | 进行 API 调用、运行计算和执行代码。 |
| 环境交互 (Environment Interaction) | 操作数字界面或控制物理设备。 |
| 通信 (Communication) | 通过聊天与用户互动或与其他智能体协作。 |
一个关键点是在动作完成时能够停止生成新的标记 (tokens),而 LLM 只处理文本,并使用它来描述它想要采取的动作以及要提供给工具的参数。
实现动作的一个关键方法是停止和解析方法,这种方法确保智能体的输出具有结构性和可预测性:
- 以结构化格式生成:智能体以清晰、预定义的格式(JSON或代码)输出其预期动作。
- 停止进一步生成:一旦动作完成,智能体停止生成额外的标记。这可以防止额外或错误的输出。
- 解析输出:外部解析器读取格式化的动作,确定要调用哪个工具,并提取所需的参数,然后框架可以轻松解析要调用的函数名称和要应用的参数。
另一种方法是使用代码智能体,这个想法是:代码智能体不是输出简单的 JSON 对象,而是生成一个可执行的代码块——通常使用 Python 等高级语言,智能体可能直接通过执行代码来完成需要的任务,比如对于获取天气这个任务,代码智能体可能会通过API调用获取天气数据,处理响应,最后使用print()函数输出最终答案。
Observe: 整合反馈以反思和调整
Observations(观察)是智能体感知其行动结果的方式,它们提供关键信息,为智能体的思考过程提供燃料并指导未来行动,这些是来自环境的信号——无论是 API 返回的数据、错误信息还是系统日志——它们指导着下一轮的思考循环。在观察阶段,智能体会:
- 调整策略:使用更新后的上下文来优化后续思考和行动
- 收集反馈:接收数据或确认其行动是否成功
- 附加结果:将新信息整合到现有上下文中,有效更新记忆
比如天气API返回了具体的天气,这个观察结果就会被附加到智能体的记忆(位于提示末尾),随后利用这些信息决定是否需要额外数据,或是否准备好提供最终答案,这种迭代式反馈整合确保智能体始终保持与目标的动态对齐,根据现实结果不断学习和调整。这些观察可能呈现多种形式,从读取网页文本到监测机械臂位置。这可以视为工具”日志”,为行动执行提供文本反馈。
| 观察类型 | 示例 |
|---|---|
| 系统反馈 | 错误信息、成功通知、状态码 |
| 数据变更 | 数据库更新、文件系统修改、状态变更 |
| 环境数据 | 传感器读数、系统指标、资源使用情况 |
| 响应分析 | API 响应、查询结果、计算输出 |
| 基于时间的事件 | 截止时间到达、定时任务完成 |
简单来说,执行操作后,智能体会解析操作、执行操作、最后将结果附加作为 Observation。
没想到第一章学完还有证书。

LangGraph
LangGraph 是一种专为构建多步骤、多分支、具状态管理能力的 语言模型应用流程图(graph-based LLM agents) 而设计的框架,由 LangChain 团队开发。它的核心思想是:用“有状态、有记忆的图结构”来组织多个 LLM 步骤和工具调用,构建复杂、可控的 LLM 应用流程。
相比而言,LangChain 专注构建单个 agent(chain)、处理 prompt、memory、工具调用,而LangGraph在此基础上,支持 图状、多轮、多路径的 agent 流程图。LangChain 提供了与模型和其他组件交互的标准接口,可用于检索、LLM 调用和工具调用。 LangChain 的类可能会在 LangGraph 中使用,但不是必须的,事实上这两个包是独立的,可以单独使用。
LangGraph 提供了构建可预测流程应用程序的工具,同时仍能利用 LLM 的强大能力,因此如果我们的应用程序包含需要以特定方式编排的多个步骤,并在每个连接点做出决策,LangGraph 就能提供你所需的结构。LangGraph 的核心在于使用有向图结构来定义应用程序的流程:
- 节点 表示独立的处理步骤(如调用 LLM、使用工具或做出决策)
- 边 定义步骤之间可能的转换
- 状态 由用户定义和维护,并在执行期间在节点间传递。当决定下一个目标节点时,我们查看的就是当前状态
LangGraph 的核心构建模块
LangGraph 应用程序从 entrypoint 开始,根据执行情况,流程可能流向不同的函数直到抵达 END:
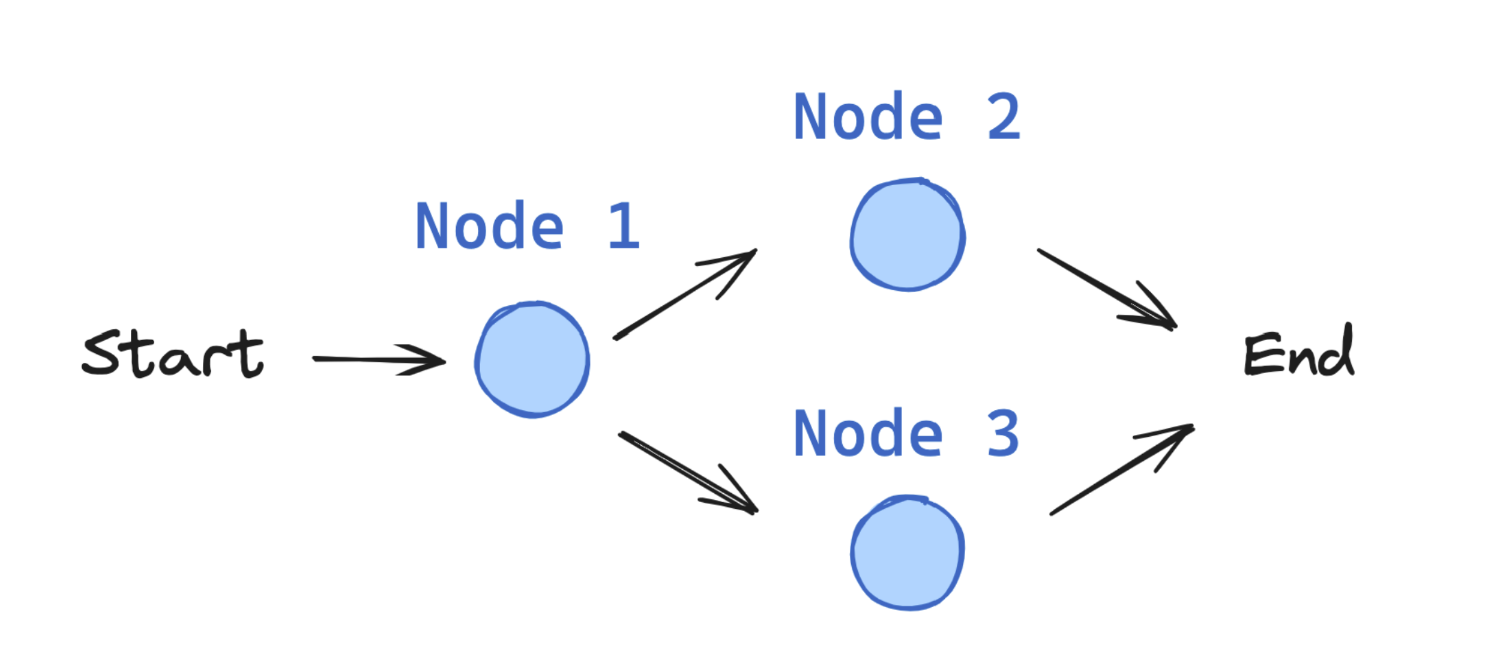
状态(State)
State 是 LangGraph 中的核心概念,表示流经应用程序的所有信息,用于描述图中各个节点之间传递的数据结构。你可以把它看作是“流程图”中的共享上下文(context),每个节点对这个上下文进行读取和修改,从而实现复杂的、多步骤的推理与任务处理。
from typing_extensions import TypedDict
class State(TypedDict):
graph_state: str它就像是一个“共享的记事本”:
- 这个机制让 LangGraph 具备了“记忆”功能,能够实现多轮对话、上下文跟踪等。
- 每个节点可以读取、写入这个记事本中的字段。
- 图从某个初始状态开始,然后一步步更新这个状态,直到流程结束。
节点(Nodes)
节点(Nodes) 是构成流程图的基本单元。每个节点就是一个函数,它接收当前的 State,对其进行处理,并返回一个部分更新的状态(一个字典)。多个节点之间通过“边(Edges)”连接,形成一个有向图(DAG 或带条件逻辑的图)。
def node_1(state):
print("---Node 1---")
return {"graph_state": state['graph_state'] +" I am"}
def node_2(state):
print("---Node 2---")
return {"graph_state": state['graph_state'] +" happy!"}
def node_3(state):
print("---Node 3---")
return {"graph_state": state['graph_state'] +" sad!"}我们可以把节点看作是“流程中的一个步骤”:
- 输入:从
State中读取需要的字段。 - 处理:执行某些逻辑,如调用 LLM、处理数据等。
- 输出:返回新的状态字段,LangGraph 会把这些合并进整个全局
State。
比如,节点可以包含:
- 人工干预:获取用户输入
- LLM 调用:生成文本或做出决策
- 工具调用:与外部系统交互
- 条件逻辑:决定后续步骤
边(Edges)
Edges 连接节点并定义图中的可能路径:
import random
from typing import Literal
def decide_mood(state) -> Literal["node_2", "node_3"]:
# 通常我们会根据状态决定下一个节点
user_input = state['graph_state']
# 这里我们在节点2和节点3之间简单实现 50/50 的概率分配
if random.random() < 0.5:
# 50% 时间, 我们返回节点2
return "node_2"
# 50% 时间, 我们返回节点3
return "node_3"边可以是:
- 直接边: 始终从节点 A 到节点 B
- 条件边: 根据当前状态选择下一个节点
状态图(StateGraph)
StateGraph 是包含整个 agent 工作流的容器:
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# 构建图表
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# 连接逻辑
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood)
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# 编译
graph = builder.compile()然后我们可以可视化图表:
# 可视化
display(Image(graph.get_graph().draw_mermaid_png()))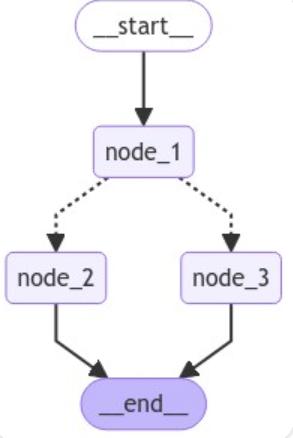
LangGraph 的创建
首先安装必要的依赖:
python -m pip install langgraph langchain_openai导入模块:
import json
from typing import TypedDict, List, Dict, Any, Optional
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage首先定义状态,定义了流程中各步骤共享的状态结构,例如是否为 spam、草稿回应等:
class EmailState(TypedDict):
email: Dict[str, Any]
is_spam: Optional[bool]
spam_reason: Optional[str]
email_category: Optional[str]
draft_response: Optional[str]
messages: List[Dict[str, Any]]然后进行模型初始化,这个就和之前一样了:
model = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE
)接着定义节点,这里我们定义了很多的节点,首先是 read_email,用于标记我们收到了邮件:
def read_email(state: EmailState):
email = state["email"]
print(f"Alfred is processing an email from {email['sender']} with subject: {email['subject']}")
return {}接着是一个节点 classify_email,作用就是构造 prompt 给 LLM,请其判断是否 spam、原因、分类:
def classify_email(state: EmailState):
email = state["email"]
prompt = f"""
You are Alfred the butler. Analyze the following email and return structured JSON output.
Email:
From: {email['sender']}
Subject: {email['subject']}
Body: {email['body']}
Respond strictly in this format:
{{
"is_spam": true or false,
"reason": "if it is spam, explain why. if not, explain why it's legitimate",
"category": "inquiry, complaint, thank you, request, information, or null"
}}
"""
messages = [HumanMessage(content=prompt)]
response = model.invoke(messages)
response_text = response.content.strip()
try:
parsed = json.loads(response_text)
except json.JSONDecodeError:
print("⚠️ Failed to parse model response:", response_text)
parsed = {"is_spam": None, "reason": None, "category": None}
new_messages = state.get("messages", []) + [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response_text}
]
return {
"is_spam": parsed["is_spam"],
"spam_reason": parsed["reason"] if parsed["is_spam"] else None,
"email_category": parsed["category"] if not parsed["is_spam"] else None,
"messages": new_messages
}然后是节点handle_spam,作用就是当发现这个邮件标记为垃圾邮件,就打印原因并提示移动到垃圾箱:
def handle_spam(state: EmailState):
reason = state.get("spam_reason", "unknown reason")
print(f"Alfred has marked the email as spam. Reason: {reason}")
print("The email has been moved to the spam folder.")
return {}如果不是垃圾邮件就需要发邮件进行回复,generate_draft这个节点就是来构造回复的:
def generate_draft(state: EmailState):
email = state["email"]
category = state["email_category"] or "general"
prompt = f"""
As Alfred the butler, draft a polite preliminary response to this email.
Email:
From: {email['sender']}
Subject: {email['subject']}
Body: {email['body']}
This email has been categorized as: {category}
Draft a brief, professional response that Mr. Hugg can review and personalize before sending.
"""
messages = [HumanMessage(content=prompt)]
response = model.invoke(messages)
new_messages = state.get("messages", []) + [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response.content}
]
return {
"draft_response": response.content,
"messages": new_messages
}notify_mr_hugg节点模拟发送:
def notify_mr_hugg(state: EmailState):
email = state["email"]
print("\n" + "="*50)
print(f"Sir, you've received an email from {email['sender']}.")
print(f"Subject: {email['subject']}")
print(f"Category: {state.get('email_category', 'unspecified')}")
print("\nI've prepared a draft response for your review:")
print("-"*50)
print(state["draft_response"])
print("="*50 + "\n")
return {}接着定义路由逻辑,利用一个函数来确定分类后要采取哪条路径:
def route_email(state: EmailState) -> str:
return "spam" if state.get("is_spam") else "legitimate"然后创建 StateGraph 并定义边,注意这个边必须和上面的路径名字匹配:
# 构建 Graph
email_graph = StateGraph(EmailState)
email_graph.add_node("read_email", read_email)
email_graph.add_node("classify_email", classify_email)
email_graph.add_node("handle_spam", handle_spam)
email_graph.add_node("generate_draft", generate_draft)
email_graph.add_node("notify_mr_hugg", notify_mr_hugg)
email_graph.add_edge("read_email", "classify_email")
email_graph.add_conditional_edges("classify_email", route_email, {
"spam": "handle_spam",
"legitimate": "generate_draft"
})
email_graph.add_edge("handle_spam", END)
email_graph.add_edge("generate_draft", "notify_mr_hugg")
email_graph.add_edge("notify_mr_hugg", END)
email_graph.set_entry_point("read_email")
compiled_graph = email_graph.compile()
#生成工作流程图
compiled_graph.get_graph().print_ascii()最后给它输入合法的邮件以及垃圾邮件进行检测:
# 合法电子邮件示例
legitimate_email = {
"sender": "john.smith@example.com",
"subject": "Question about your services",
"body": "Dear Mr. Hugg, I was referred to you by a colleague and I'm interested in learning more about your consulting services. Could we schedule a call next week? Best regards, John Smith"
}
# 垃圾邮件示例
spam_email = {
"sender": "winner@lottery-intl.com",
"subject": "YOU HAVE WON $5,000,000!!!",
"body": "CONGRATULATIONS! You have been selected as the winner of our international lottery! To claim your $5,000,000 prize, please send us your bank details and a processing fee of $100."
}
# 处理合法电子邮件
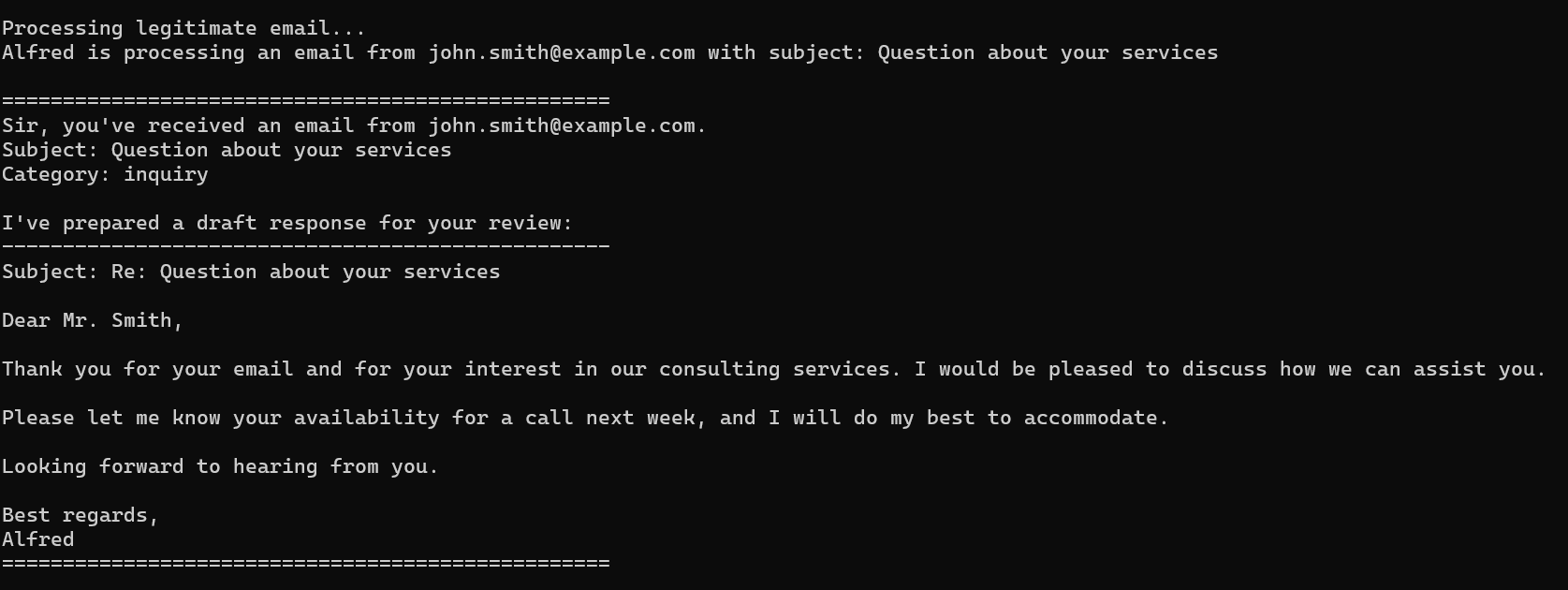
print("\nProcessing legitimate email...")
legitimate_result = compiled_graph.invoke({
"email": legitimate_email,
"is_spam": None,
"spam_reason": None,
"email_category": None,
"draft_response": None,
"messages": []
})
# 处理垃圾邮件
print("\nProcessing spam email...")
spam_result = compiled_graph.invoke({
"email": spam_email,
"is_spam": None,
"spam_reason": None,
"email_category": None,
"draft_response": None,
"messages": []
})完整代码如下:
import json
from typing import TypedDict, List, Dict, Any, Optional
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
# OpenAI 配置
OPENAI_API_KEY = "sk-xxxx"
OPENAI_API_BASE = "https://api.gptgod.online/v1/"
# 状态定义
class EmailState(TypedDict):
email: Dict[str, Any]
is_spam: Optional[bool]
spam_reason: Optional[str]
email_category: Optional[str]
draft_response: Optional[str]
messages: List[Dict[str, Any]]
# 初始化 LLM
model = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE
)
# 步骤函数
def read_email(state: EmailState):
email = state["email"]
print(f"Alfred is processing an email from {email['sender']} with subject: {email['subject']}")
return {}
def classify_email(state: EmailState):
email = state["email"]
prompt = f"""
You are Alfred the butler. Analyze the following email and return structured JSON output.
Email:
From: {email['sender']}
Subject: {email['subject']}
Body: {email['body']}
Respond strictly in this format:
{{
"is_spam": true or false,
"reason": "if it is spam, explain why. if not, explain why it's legitimate",
"category": "inquiry, complaint, thank you, request, information, or null"
}}
"""
messages = [HumanMessage(content=prompt)]
response = model.invoke(messages)
response_text = response.content.strip()
try:
parsed = json.loads(response_text)
except json.JSONDecodeError:
print("⚠️ Failed to parse model response:", response_text)
parsed = {"is_spam": None, "reason": None, "category": None}
new_messages = state.get("messages", []) + [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response_text}
]
return {
"is_spam": parsed["is_spam"],
"spam_reason": parsed["reason"] if parsed["is_spam"] else None,
"email_category": parsed["category"] if not parsed["is_spam"] else None,
"messages": new_messages
}
def handle_spam(state: EmailState):
reason = state.get("spam_reason", "unknown reason")
print(f"Alfred has marked the email as spam. Reason: {reason}")
print("The email has been moved to the spam folder.")
return {}
def generate_draft(state: EmailState):
email = state["email"]
category = state["email_category"] or "general"
prompt = f"""
As Alfred the butler, draft a polite preliminary response to this email.
Email:
From: {email['sender']}
Subject: {email['subject']}
Body: {email['body']}
This email has been categorized as: {category}
Draft a brief, professional response that Mr. Hugg can review and personalize before sending.
"""
messages = [HumanMessage(content=prompt)]
response = model.invoke(messages)
new_messages = state.get("messages", []) + [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response.content}
]
return {
"draft_response": response.content,
"messages": new_messages
}
def notify_mr_hugg(state: EmailState):
email = state["email"]
print("\n" + "="*50)
print(f"Sir, you've received an email from {email['sender']}.")
print(f"Subject: {email['subject']}")
print(f"Category: {state.get('email_category', 'unspecified')}")
print("\nI've prepared a draft response for your review:")
print("-"*50)
print(state["draft_response"])
print("="*50 + "\n")
return {}
def route_email(state: EmailState) -> str:
return "spam" if state.get("is_spam") else "legitimate"
# 构建 Graph
email_graph = StateGraph(EmailState)
email_graph.add_node("read_email", read_email)
email_graph.add_node("classify_email", classify_email)
email_graph.add_node("handle_spam", handle_spam)
email_graph.add_node("generate_draft", generate_draft)
email_graph.add_node("notify_mr_hugg", notify_mr_hugg)
email_graph.add_edge("read_email", "classify_email")
email_graph.add_conditional_edges("classify_email", route_email, {
"spam": "handle_spam",
"legitimate": "generate_draft"
})
email_graph.add_edge("handle_spam", END)
email_graph.add_edge("generate_draft", "notify_mr_hugg")
email_graph.add_edge("notify_mr_hugg", END)
email_graph.set_entry_point("read_email")
compiled_graph = email_graph.compile()
#生成工作流程图
compiled_graph.get_graph().print_ascii()
# 测试数据
legitimate_email = {
"sender": "john.smith@example.com",
"subject": "Question about your services",
"body": "Dear Mr. Hugg, I was referred to you by a colleague and I'm interested in learning more about your consulting services. Could we schedule a call next week? Best regards, John Smith"
}
spam_email = {
"sender": "winner@lottery-intl.com",
"subject": "YOU HAVE WON $5,000,000!!!",
"body": "CONGRATULATIONS! You have been selected as the winner of our international lottery! To claim your $5,000,000 prize, please send us your bank details and a processing fee of $100."
}
# 执行
print("\nProcessing legitimate email...")
compiled_graph.invoke({
"email": legitimate_email,
"is_spam": None,
"spam_reason": None,
"email_category": None,
"draft_response": None,
"messages": []
})
print("\nProcessing spam email...")
compiled_graph.invoke({
"email": spam_email,
"is_spam": None,
"spam_reason": None,
"email_category": None,
"draft_response": None,
"messages": []
})
在运行结果里,首先我们会看到一个可视化表示,显示了我们的路径图:
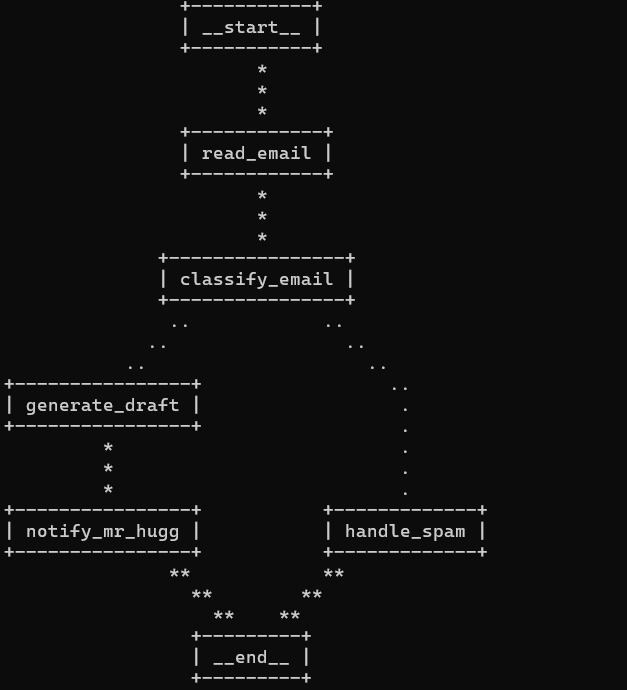
对于第一个合法的邮件,llm会分析出这是一个inquiry,接着回复一封邮件
对于非法邮件,则会将其移入回收站,并说明原因:
