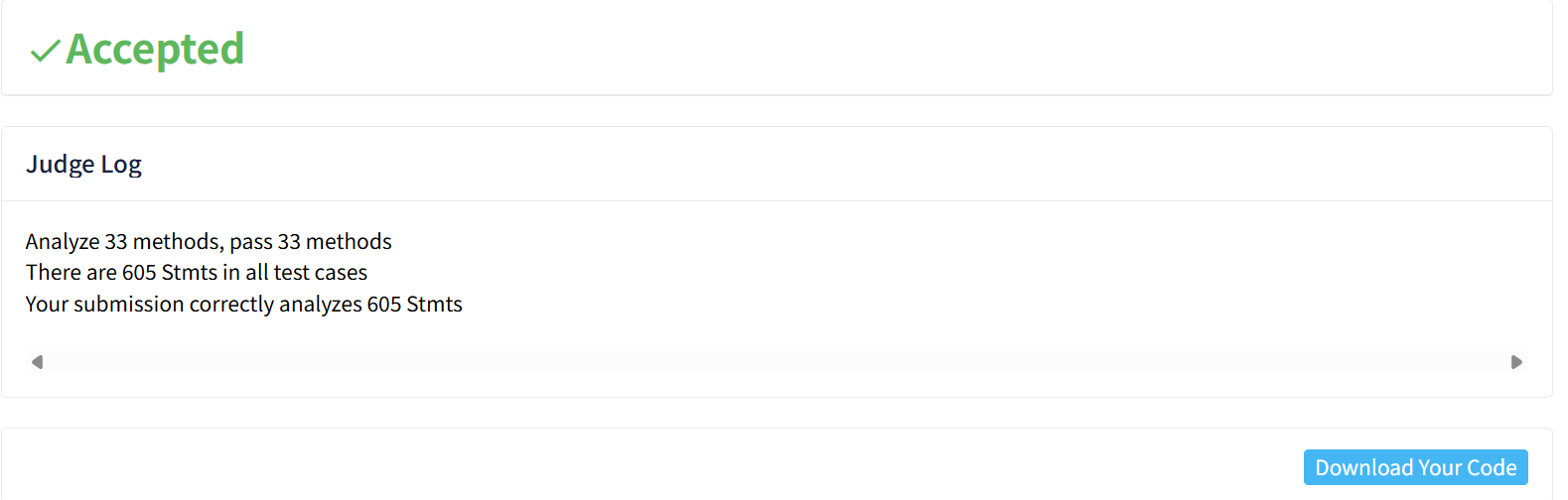
环境配置
这里我使用的是教学版,Tai-e的实验作业去github下一份就行了:https://github.com/pascal-lab/Tai-e-assignments,因为Tai-e是用 Gradle 构建的,所以每个作业也符合 Gradle 的基本结构:
build.gradle.kts,gradlew,gradlew.bat,gradle/:Gradle 脚本和 Tai-e 项目配置文件。src/main/java:Tai-e 源代码文件夹。你需要修改该文件夹中的文件以完成作业。src/test/java:运行测试用例所需的测试驱动程序(test drivers)所在文件夹。src/test/resources:测试用例(待分析的程序)文件夹。lib/:包含 Tai-e 类的文件夹。plan.yml:Tai-e 配置文件,设定了作业中需要执行的分析。COPYING,COPYING.LESSER:Tai-e 许可文件
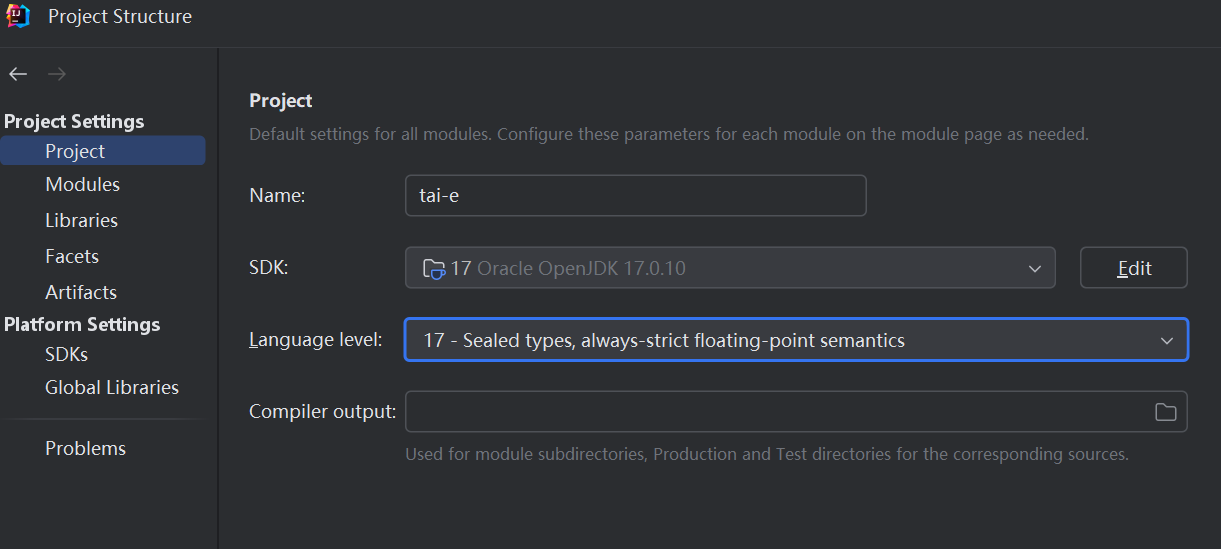
Tai-e需要 Java17,这里我按照官方教程打开了A1/tai-e/,然后Languege level这里选择17:
在 Tai-e 教学版里有一个特殊的类:
pascal.taie.Assignment它提供了一种简单的使用方式来分析Java程序:
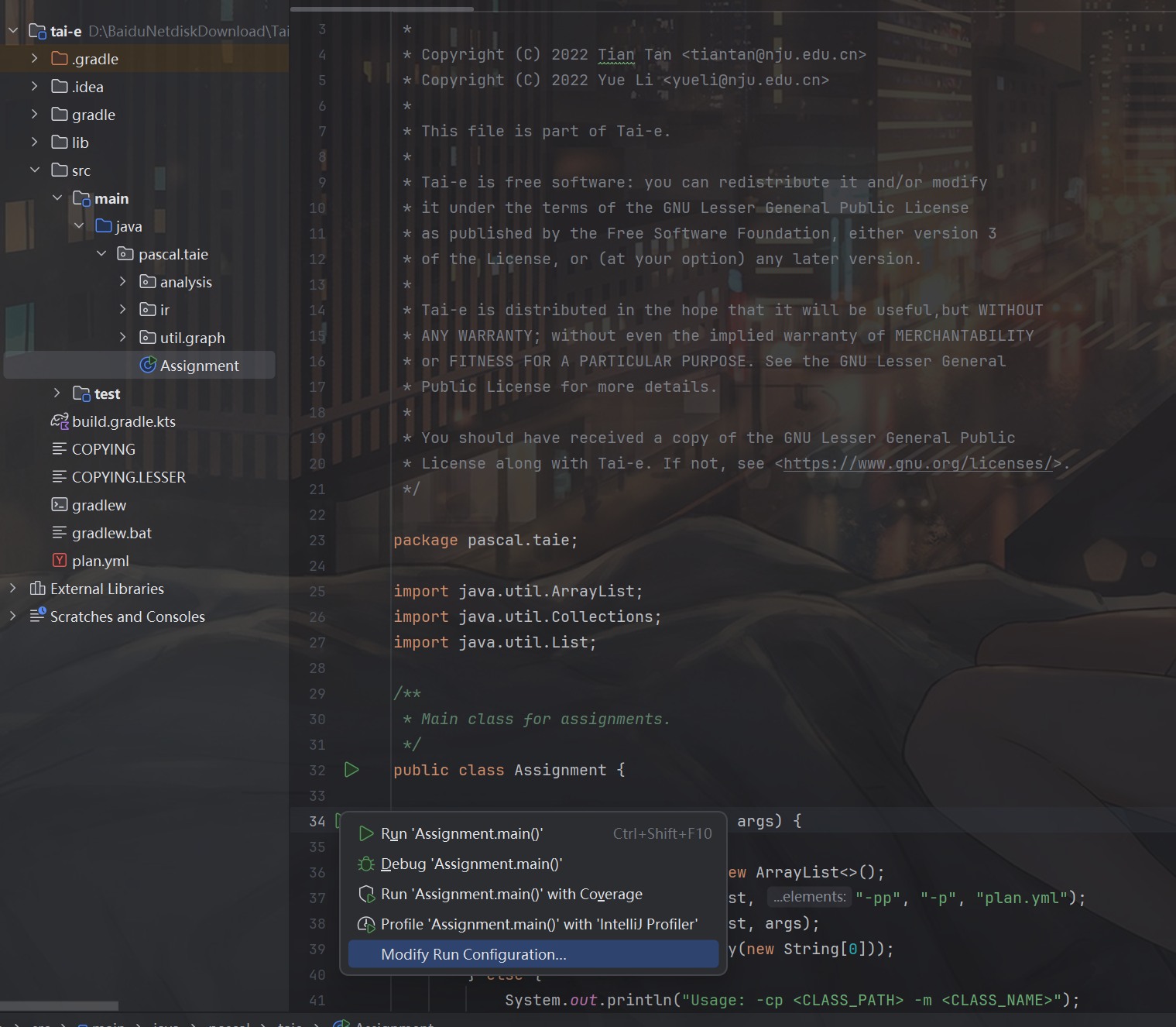
-cp <CLASS_PATH> -m <CLASS_NAME>顾名思义,<CLASS_PATH> 是 .class 文件所在文件夹的路径,<CLASS_NAME> 是待分析类的类名。比如如果我们想要分析 src/test/resources/dataflow/livevar 中的 Assign.java,首先在 IntelliJ IDEA 中打开 Assignment 的 “Run Configuration”:
按图里这样配置 Program arguments:
-cp src/test/resources/dataflow/livevar -m Assign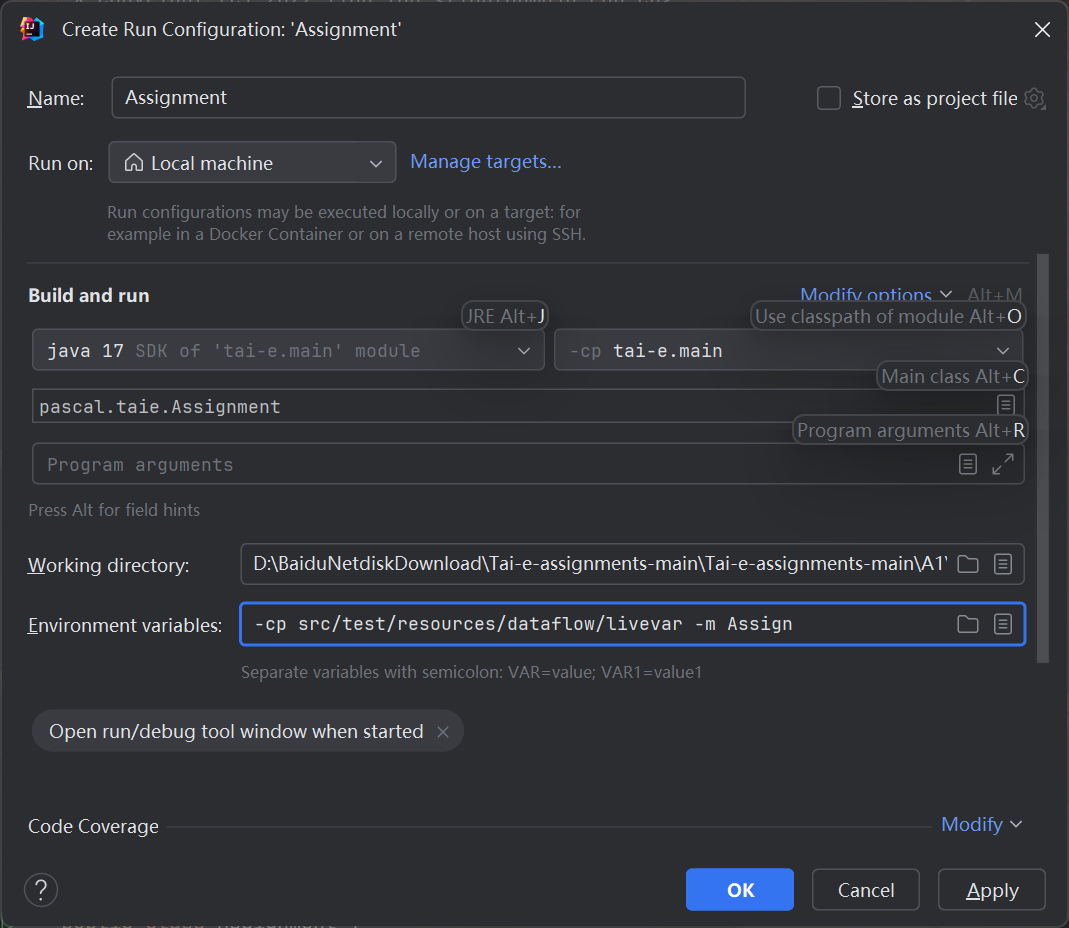
在 src/test/resources/ 文件夹有一些 Java 类和测试输入,每个类都对应于一个名为 *-expected.txt 的期望测试结果文件,测试驱动程序会对 src/test/resources/ 下所有测试用例执行分析,并将其输出与期望结果进行比较。如果实现正确会通过测试,否则测试驱动程序会失败并输出期望结果和执行结果的不同之处,只不过这里只有部分的测试样例,类似OJ里题目中显示的,还有一些边界样例只有平台上才有。
作业 1:活跃变量分析和迭代求解器
作业导览
- 为 Java 实现一个活跃变量分析(Live Variable Analysis)。
- 实现一个通用的迭代求解器(Iterative Solver),用于求解数据流分析问题,也就是本次作业中的活跃变量分析。
活跃变量分析
对于变量x和程序点p,如果在程序流图中沿着从p开始的某条路径会引用变量x在p点的值,则称变量x在点p是活跃(live)的,否则称变量x在点p是不活跃(dead)的,也就是说,它的值可能在之后被使用,而在此之前没有被重新赋值
主要作用有两个:
- 删除无用赋值:比如在某个点赋值之后发现后面其实用不到,那么其实就可以删除这个赋值
- 寄存器分配:如果需要分配寄存器,可以优先分配这些不活跃变量占据的寄存器。
在这里有几个符号:
- def[B]: 基本块B中定义的变量集合。即在B中被赋值(定义)的变量。
- use[B]: 基本块B中使用的变量集合。即在B中被使用但未先被定义的变量。
- 示例:
y = x + 3(且x未在B中先定义) 会导致x ∈ use[B]
- 示例:
- IN[B]:在进入
B时哪些变量是活跃的(可能在未来被使用)。 - OUT[B]:在离开
B时哪些变量是活跃的(由后继块的IN决定)
活跃变量分析是逆向数据流分析,其方程为:
OUT[B] = ∪ IN[S] (对于所有B的后继S)
IN[B] = use[B] ∪ (OUT[B] - def[B])- 一个变量在基本块的出口活跃,如果它在某个后继基本块的入口活跃
- 一个变量在基本块
B的入口是活跃的,如果它在B中被使用(即use[B]),或者它在B的后继块中活跃而在B中没有被定义(覆盖)。use[B]:在B中被使用(读取)但未先定义的变量(即它们的值来自B之前的计算)。OUT[B] - def[B]:如果一个变量在B的出口处是活跃的(即在B的后继块中被使用),但在B内部没有被重新定义,那么它的值 必须来自B的入口(即它在B的入口处也是活跃的),如果来自于 B 内部的赋值,其实我们就不能确定它一定在入口处活跃了
对于下面这个例子:
B1:
1: x = 10
2: y = 20
3: if x > y goto B3
B2:
4: z = x + y
5: w = z * 2
6: goto B4
B3:
7: z = x - y
8: w = z / 2
B4:
9: print(w)
其结果如下:
| 基本块 | def[B] | use[B] |
|---|---|---|
B1 | {x, y} | {} |
B2 | {z, w} | {x, y} |
B3 | {z, w} | {x, y} |
B4 | {} | {w} |
初始化时,所有 IN[B] = {},OUT[B] = {},由于是逆向分析,我们从 B4 开始,然后 B3 和 B2,最后 B1:
B4的分析use[B4] = {w},def[B4] = {}OUT[B4] = {}(没有后继)IN[B4] = use[B4] ∪ (OUT[B4] \ def[B4]) = {w} ∪ ({} \ {}) = {w}
B3的分析use[B3] = {x, y},def[B3] = {z, w}OUT[B3] = IN[B4] = {w}(B3的后继是B4)IN[B3] = {x, y} ∪ ({w} \ {z, w}) = {x, y} ∪ {} = {x, y}
B2的分析use[B2] = {x, y},def[B2] = {z, w}OUT[B2] = IN[B4] = {w}(B2 的后继只有 B4 ,直接跳转过去了)IN[B2] = {x, y} ∪ ({w} \ {z, w}) = {x, y} ∪ {} = {x, y}
B1的分析use[B1] = {},def[B1] = {x, y}OUT[B1] = IN[B2] ∪ IN[B3] = {x, y} ∪ {x, y} = {x, y}(B1 的后继是 B2和B3,一个来自条件跳转,一个来自直接相连的边)IN[B1] = {} ∪ ({x, y} \ {x, y}) = {} ∪ {} = {}
实现活跃变量分析
有关的类
pascal.taie.analysis.dataflow.analysis.DataflowAnalysis
这是一个抽象的数据流分析类,是具体的数据流分析与求解器之间的接口。也就是说,一个具体的数据流分析(如活跃变量分析)需要实现它的接口,而求解器(如迭代求解器)需要通过它的接口来求解数据流。
它共有七个 API,而在本次作业中,我们只关注与数据流分析相关的五个关键 API:分析方向、边界条件、初始条件、meet 操作、transfer 函数:
DataflowAnalysis只是一个接口,这里简单分析一下这个接口里的几个方法:
- boolean isForward():返回该分析是否是前向分析(forward analysis)
- 若返回
true:从 CFG 的入口节点出发向后传播(如:可达性分析)。 - 若返回
false:从 CFG 的出口节点反向传播(如:活跃变量分析)。
- 若返回
- Fact newBoundaryFact(CFG cfg):返回边界条件下的初始数据流事实
- 如果是前向分析,该 fact 作为入口节点的
in; - 如果是后向分析,该 fact 作为出口节点的
out;
- 如果是前向分析,该 fact 作为入口节点的
- Fact newInitialFact():非边界节点的新初始事实
- void meetInto(Fact fact, Fact target):将
fact与target合并,结果写入target中 - boolean transferNode(Node node, Fact in, Fact out):节点的 transfer 函数,处理数据流的转移,如果
out(或in)被修改了,返回true(说明数据流继续传播),否则false - boolean needTransferEdge(Edge edge):判断某条边是否需要进行数据流传播。
- Fact transferEdge(Edge edge, Fact nodeFact):此分析的边缘传递函数
pascal.taie.ir.exp.Exp
这是 Tai-e 的 IR 中的一个关键接口,用于表示程序中的所有表达式。它含有很多子类,对应各类具体的表达式。下面是一个 Exp 类继承结构的简单图示:
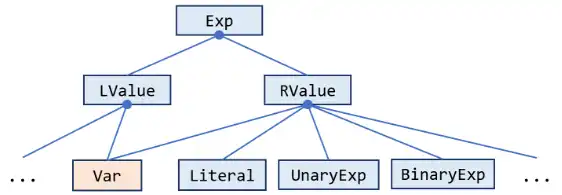
在 Tai-e 的 IR 中,我们把表达式分为两类:LValue 和 RValue。前者表示赋值语句左侧的表达式,如变量(x = … )、字段访问(x.f = …)或数组访问(x[i] = …);后者对应地表示赋值语句右侧的表达式,如数值字面量(… = 1;)或二元表达式(… = a + b;)。而有些表达式既可用于左值,也可用于右值,就比如变量(用Var类表示),这里由于我们只需要关注活跃变量,所以只考虑Var即可。
pascal.taie.ir.stmt.Stmt
这是 Tai-e 的 IR 中的另一个关键接口,它用于表示程序中的所有语句。对于一个典型的程序设计语言来说,每个表达式都属于某条特定的语句。为了实现活跃变量分析,你需要获得某条语句中定义或使用的所有表达式中的变量。Stmt 类贴心地为这两种操作提供了对应的接口:
Optional<LValue> getDef()
List<RValue> getUses()每条 Stmt 至多只可能定义一个变量、而可能使用零或多个变量,因此我们使用 Optional 和 List 包装了 getDef() 和 getUses() 的结果。
pascal.taie.analysis.dataflow.fact.SetFact<Var>
这个泛型类用于把 data fact 组织成一个集合。它提供了各种集合操作,如添加、删除元素,取交集、并集等。你同样需要阅读源码和注释来理解如何使用这个类表示活跃变量分析中的各种 data fact。
pascal.taie.analysis.dataflow.analysis.LiveVariableAnalysis
这个类通过实现 DataflowAnalysis 的接口来定义具体的活跃变量分析。你需要按照题目中的说明补全这个类。
具体的任务
第一个任务是实现 LiveVariableAnalysis 中的如下 API:
- SetFact newBoundaryFact(CFG)
- SetFact newInitialFact()
- void meetInto(SetFact,SetFact)
- boolean transferNode(Stmt,SetFact,SetFact)
这些 API 对应下图算法中的四个部分:

这里的 meetInto() 接受 fact 和 target 两个参数并把 fact 集合并入 target 集合, meetInto() 附近的那行伪代码会取出 B 的所有后继,然后把它们 IN facts 的并集赋给 OUT[B]。如果这行代码用 meetInto() 来实现,那么我们就可以根据下图所示,用 meetInto(IN[S], OUT[B]) 把 B 的每个后继 S 的 IN fact 直接并入到 OUT[B] 中

实现迭代求解器
有关的类
pascal.taie.analysis.dataflow.fact.DataflowResult
该类对象用于维护数据流分析的 CFG 中的 fact。你可以通过它的 API 获取、设置 CFG 节点的 IN facts 和 OUT facts
pascal.taie.analysis.graph.cfg.CFG
这个类用于表示程序中方法的控制流图。它是可迭代的,也就是说你可以通过一个 for 循环遍历其中的所有节点:
CFG<Node> cfg = ...;
for (Node node : cfg) {
...
}你也可以通过 CFG.getPredsOf(Node) 和 CFG.getSuccsOf(Node) 这两个方法遍历 CFG 中节点的所有前驱和后继:
for (Node succ : cfg.getSuccsOf(node)) {
...
}接口 CFG<N>表示控制流图(Control Flow Graph,CFG),是静态分析中非常核心的数据结构之一,用于描述程序中语句或基本块之间的执行流程,这个接口继承自 Graph<N> 接口,里面提供了很多方法:
- IR getIR():返回此 CFG 所对应的中间表示 IR(Intermediate Representation)
- JMethod getMethod():返回该 CFG 对应的方法对象
- N getEntry():返回入口
- N getExit():返回出口
- boolean isEntry(N node):判断是否是入口
- boolean isExit(N node):判断是否是出口
- Set<Edge<N>> getInEdgesOf(N node):返回以
node为终点的所有边(即从哪些节点可以到达它) - Set<Edge<N>> getOutEdgesOf(N node):返回从
node出发的所有边(即它可以到达哪些节点)
pascal.taie.analysis.dataflow.solver.Solver
这是数据流分析求解器的基类,包含了求解器的抽象功能。本次作业要实现的迭代求解器就是它的一个派生类。Tai-e 会构建待分析程序的 CFG 并传给 Solver.solve(CFG),然后世界就开始运转了。你可能注意到了,这个类中有两组 initialize 和 doSolve 方法,分别用于处理前向和后向的数据流分析。虽然稍显冗余,但在这样的设计下代码结构会更干净、直接一些。
pascal.taie.analysis.dataflow.solver.IterativeSolver
这个类扩展了 Solver 的功能并实现了迭代求解算法。
具体的任务
实现上面提到的 Solver 类的两个方法:
- Solver.initializeBackward(CFG,DataflowResult)
- IterativeSolver.doSolveBackward(CFG,DataflowResult)
因为活跃变量分析是一个后向分析,所以我们只需要关注后向分析相关的方法就足够了。在 initializeBackward() 中,我们需要实现算法的前三行;在 doSolveBackward() 则要完成对应的 while 循环。
完成作业
主要就是提交三个类:
LiveVariableAnalysis.javaSolver.javaIterativeSolver.java
首先看到LiveVariableAnalysis.java:

可以看到一堆的空白等着我们补全,那就来一个一个攻克吧!
newBoundaryFact其实就是边界条件,也就是算法里的IN[exit]=∅,毕竟活跃变量分析是一个自后向前的过程,exit是没有out的,它的in在最开始自然是空的,所以其实返回一个空集即可
public SetFact<Var> newBoundaryFact(CFG<Stmt> cfg) {
return new SetFact<Var>();
}这个其实也是同理,在最开始IN[B]=∅,返回空即可
public SetFact<Var> newInitialFact() {
return new SetFact<Var>();
}meetInto用于实现算法里的OUT[B] = ∪ IN[S] (对于所有B的后继S),主要就是一个合并操作,而在SetFact里其实有现成的union,用法就是public boolean union(SetFact<E> other),所以合并一下就行了
public void meetInto(SetFact<Var> fact, SetFact<Var> target) {
target.union(fact);
}transferNode 用于实现算法里 IN[B] = use[B] ∪ (OUT[B] - def[B])这一步:
public boolean transferNode(Stmt stmt, SetFact<Var> in, SetFact<Var> out) {
// 获取outFact
SetFact<Var> newInFact = new SetFact<>();
newInFact.union(out);
// outFact - def
// 如果当前语句有定义(def),并且定义的是一个变量(Var),就从 newInFact 中移除它
if (stmt.getDef().isPresent()) {
LValue def = stmt.getDef().get();
if (def instanceof Var) {
newInFact.remove((Var) def);
}
}
// (outFact - def ) + use
// 遍历当前语句中被使用的变量,并加入到 newInFact
for (RValue use : stmt.getUses()) {
if (use instanceof Var) {
newInFact.add((Var) use);
}
}
// 判断inFact是否改变,并返回Boolean表示
if (!newInFact.equals(in)) {
in.set(newInFact);
return true;
}
return false;
}完整代码:
/*
* Tai-e: A Static Analysis Framework for Java
*
* Copyright (C) 2022 Tian Tan <tiantan@nju.edu.cn>
* Copyright (C) 2022 Yue Li <yueli@nju.edu.cn>
*
* This file is part of Tai-e.
*
* Tai-e is free software: you can redistribute it and/or modify
* it under the terms of the GNU Lesser General Public License
* as published by the Free Software Foundation, either version 3
* of the License, or (at your option) any later version.
*
* Tai-e is distributed in the hope that it will be useful,but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY
* or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General
* Public License for more details.
*
* You should have received a copy of the GNU Lesser General Public
* License along with Tai-e. If not, see <https://www.gnu.org/licenses/>.
*/
package pascal.taie.analysis.dataflow.analysis;
import pascal.taie.analysis.dataflow.fact.SetFact;
import pascal.taie.analysis.graph.cfg.CFG;
import pascal.taie.config.AnalysisConfig;
import pascal.taie.ir.exp.LValue;
import pascal.taie.ir.exp.RValue;
import pascal.taie.ir.exp.Var;
import pascal.taie.ir.stmt.Stmt;
/**
* Implementation of classic live variable analysis.
*/
public class LiveVariableAnalysis extends
AbstractDataflowAnalysis<Stmt, SetFact<Var>> {
public static final String ID = "livevar";
public LiveVariableAnalysis(AnalysisConfig config) {
super(config);
}
@Override
public boolean isForward() {
return false;
}
@Override
public SetFact<Var> newBoundaryFact(CFG<Stmt> cfg) {
return new SetFact<Var>();
}
@Override
public SetFact<Var> newInitialFact() {
return new SetFact<Var>();
}
@Override
public void meetInto(SetFact<Var> fact, SetFact<Var> target) {
target.union(fact);
}
@Override
public boolean transferNode(Stmt stmt, SetFact<Var> in, SetFact<Var> out) {
// 获取outFact
SetFact<Var> newInFact = new SetFact<>();
newInFact.union(out);
// outFact - def
// 如果当前语句有定义(def),并且定义的是一个变量(Var),就从 newInFact 中移除它
if (stmt.getDef().isPresent()) {
LValue def = stmt.getDef().get();
if (def instanceof Var) {
newInFact.remove((Var) def);
}
}
// (outFact - def ) + use
// 遍历当前语句中被使用的变量,并加入到 newInFact
for (RValue use : stmt.getUses()) {
if (use instanceof Var) {
newInFact.add((Var) use);
}
}
// 判断inFact是否改变,并返回Boolean表示
if (!newInFact.equals(in)) {
in.set(newInFact);
return true;
}
return false;
}
}接着是Solver.java,主要是实现这个initializeBackward:
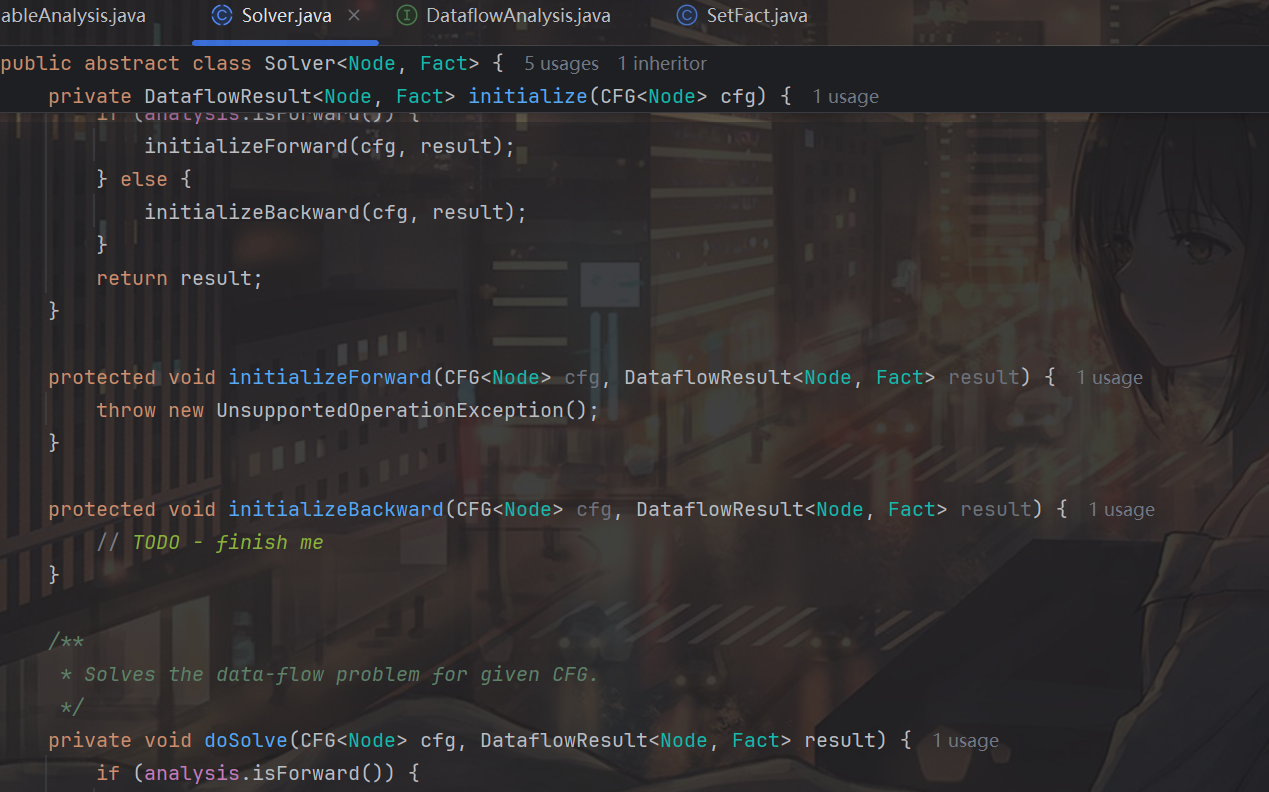
initializeBackward主要用于实现算法的前三行,也就是把IN[B]和IN[exit]初始化为∅,这里顺便把OUT[B]也初始化为空:
protected void initializeBackward(CFG<Node> cfg, DataflowResult<Node, Fact> result) {
result.setInFact(cfg.getExit(), analysis.newBoundaryFact(cfg));
for (Node node : cfg.getNodes()) {
if (cfg.isExit(node)) continue;
result.setInFact(node, analysis.newInitialFact());
result.setOutFact(node, analysis.newInitialFact());
}
}最后是迭代求解器:
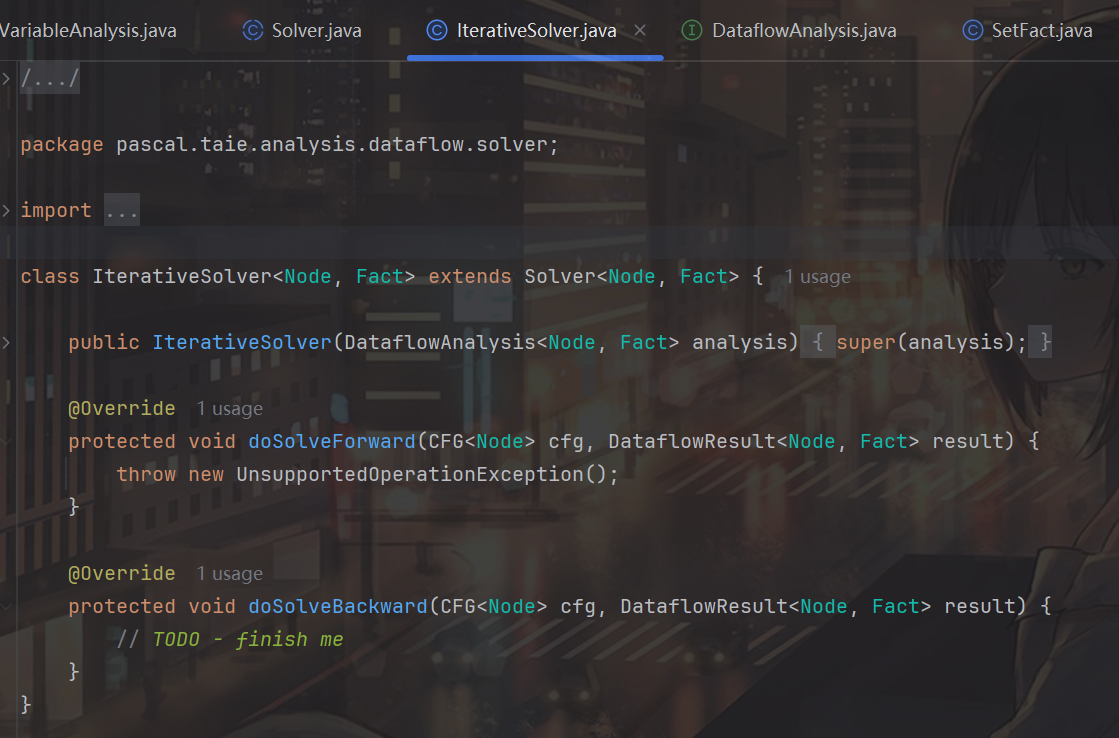
doSolveBackward其实就是用来实现那个while循环的,保证发生了IN的改变就会进行相应的处理
protected void doSolveBackward(CFG<Node> cfg, DataflowResult<Node, Fact> result) {
boolean changed = true;
while (changed) {
changed = false;
for (Node node : cfg.getNodes()) {
// 尾节点没有OUT
if (cfg.isExit(node)) continue;
// 计算OUT
for (Node succNode : cfg.getSuccsOf(node)) {
analysis.meetInto(result.getInFact(succNode), result.getOutFact(node));
}
// 利用transferNode计算IN并判断与之前的IN是否存在差异
if (analysis.transferNode(node, result.getInFact(node), result.getOutFact(node))) changed = true;
}
}
}