Task #0: 在CIFAR-10上实现LeNet-5模型
目标
- 掌握图像分类任务和LeNet-5模型的基本构成
- 掌握卷积神经网络模型LeNet-5的前向计算和反向更新过程
- 掌握损失函数、随机梯度下降等概念
实验内容
- 在CIFAR-10数据集上实现LeNet-5模型训练和测试全流程
- 在实验环境中训练LeNet-5模型,存储最终获得的模型参数
- 加载模型参数和测试集,计算模型的平均分类准确度
- Milestone:分类准确度超过65%
实验过程
LeNet-5是由Yann LeCun在1998年提出的经典卷积神经网络,最初用于手写数字识别。其结构简洁而高效,为现代CNN的发展奠定了基础。原始的LeNet-5接收32×32的单通道(灰度)图像,而CIFAR-10是32×32的3通道(彩色)图像,因此我们需要对输入层进行微调。
标准的LeNet-5结构包含:
- 两个卷积层(Convolutional Layer)
- 两个下采样层(Subsampling/Pooling Layer)
- 三个全连接层(Fully Connected Layer)
这里我是在本机跑的,因为训练的要求也不是很高,具体的实验流程如下:
- 数据加载与预处理
- 使用
torchvision.datasets.CIFAR10模块自动下载并加载数据集。通过设置download=True参数,在本地首次运行时会自动下载数据。 - 预处理流程
transforms.Compose包含两个关键步骤:transforms.ToTensor():将PIL格式的图像数据转换为PyTorch张量(Tensor),并将其像素值从[0, 255]的范围归一化到[0.0, 1.0]。transforms.Normalize():对图像张量的三个通道(R, G, B)进行标准化,公式为output = (input - mean) / std。此操作有助于模型更快地收敛。
- 最后,使用
torch.utils.data.DataLoader将数据集封装成迭代器,以实现批量(batch)训练和数据洗牌(shuffle)。
- 使用
- 模型构建 (LeNet-5)
- 我们构建了一个LeNet-5的变体以适应CIFAR-10的输入。关键调整在于第一个卷积层:
- 原始LeNet-5:输入为单通道(灰度)图像,
in_channels=1。 - 本次实验:输入为CIFAR-10的三通道(彩色)图像,因此
in_channels设置为3。
- 原始LeNet-5:输入为单通道(灰度)图像,
- 模型结构如下:
- 输入层:3x32x32 的图像。
- C1 – 卷积层:使用16个5×5的卷积核,输出为16x28x28。后接ReLU激活函数。
- S2 – 池化层:2×2的最大池化,输出为16x14x14。
- C3 – 卷积层:使用32个5×5的卷积核,输出为32x10x10。后接ReLU激活函数。
- S4 – 池化层:2×2的最大池化,输出为32x5x5。
- 展平 (Flatten):将32x5x5的特征图展平为长度为800的一维向量。
- F5 – 全连接层:800个输入节点,120个输出节点。后接ReLU激活函数。
- F6 – 全连接层:120个输入节点,84个输出节点。后接ReLU激活函数。
- 输出层:84个输入节点,10个输出节点,对应CIFAR-10的10个类别。
- 我们构建了一个LeNet-5的变体以适应CIFAR-10的输入。关键调整在于第一个卷积层:
- 定义损失函数与优化器
- 损失函数 (Loss Function):选用
nn.CrossEntropyLoss(交叉熵损失函数)。它内部集成了Softmax操作和负对数似然损失,是多分类任务的标准选择。 - 优化器 (Optimizer):选用
optim.SGD(随机梯度下降)。为了加速收敛并减少震荡,设置了momentum=0.9。学习率(lr)设置为0.001。
- 损失函数 (Loss Function):选用
- 模型训练
- 训练过程在一个循环中执行20个周期(Epoch)。在每个周期内,模型遍历整个训练数据集。对于每一个批次(batch)的数据:
- 前向传播:将输入数据
inputs送入网络net,得到预测值outputs。 - 计算损失:使用
criterion比较预测值outputs和真实标签labels,计算出损失loss。 - 反向传播:调用
loss.backward(),PyTorch会自动计算损失相对于模型各参数的梯度。 - 参数更新:调用
optimizer.step(),优化器根据计算出的梯度来更新模型的权重。 - 梯度清零:在下一次迭代前,调用
optimizer.zero_grad()清除旧的梯度。
- 前向传播:将输入数据
- 训练完成后,使用
torch.save(net.state_dict(), PATH)将模型的权重参数保存到磁盘。
- 训练过程在一个循环中执行20个周期(Epoch)。在每个周期内,模型遍历整个训练数据集。对于每一个批次(batch)的数据:
- 模型评估
- 创建一个新的LeNet-5实例,并使用
load_state_dict()加载已保存的权重。 - 将模型切换到评估模式
net.eval()。这会关闭Dropout等只在训练时使用的层。 - 使用
with torch.no_grad()上下文管理器,禁止梯度计算以节省内存和加速计算。 - 遍历测试集,将图片送入模型进行预测,并将预测结果与真实标签进行比较。
- 计算总的正确数量,最终通过公式
Accuracy = (Correct / Total) * 100%计算出模型的平均分类准确度。
- 创建一个新的LeNet-5实例,并使用
完整代码如下:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 加载与预处理CIFAR-10数据集
print("正在加载和预处理数据...")
# 定义数据预处理步骤
# ToTensor()将PIL图像或numpy.ndarray转换为FloatTensor,并将像素值从[0, 255]缩放到[0.0, 1.0]
# Normalize()使用均值和标准差对张量图像进行归一化
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载训练集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
# 加载测试集
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=2)
# CIFAR-10的类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
print("数据加载完毕!")
# 构建LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 卷积层部分
self.conv_net = nn.Sequential(
# 原始LeNet-5输入是单通道,CIFAR-10是3通道,故in_channels=3
# C1: 卷积层1, 输入3x32x32, 输出6x28x28
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
# S2: 池化层1, 输入16x28x28, 输出16x14x14
nn.MaxPool2d(kernel_size=2, stride=2),
# C3: 卷积层2, 输入16x14x14, 输出32x10x10
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
# S4: 池化层2, 输入32x10x10, 输出32x5x5
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 全连接层部分
self.fc_net = nn.Sequential(
# F5: 全连接层1, 输入32*5*5=800, 输出120
nn.Linear(32 * 5 * 5, 120),
nn.ReLU(),
# F6: 全连接层2, 输入120, 输出84
nn.Linear(120, 84),
nn.ReLU(),
# Output: 输出层, 输入84, 输出10 (对应10个类别)
nn.Linear(84, 10)
)
def forward(self, x):
# 前向计算
x = self.conv_net(x)
# 将卷积层的输出展平 (flatten) 以输入到全连接层
x = x.view(-1, 32 * 5 * 5)
x = self.fc_net(x)
return x
# 实例化模型
net = LeNet5()
print("LeNet-5 模型已构建。")
# 检查是否有可用的GPU,并移动模型到对应设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
net.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练模型
print("开始训练模型...")
num_epochs = 20 # 训练周期
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取输入数据;data是一个[inputs, labels]的列表
inputs, labels = data[0].to(device), data[1].to(device)
# ---- 前向计算 ----
outputs = net(inputs)
loss = criterion(outputs, labels)
# ---- 反向更新 ----
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 200 == 199: # 每200个mini-batches打印一次
print(f'[Epoch: {epoch + 1}, Batch: {i + 1:5d}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
print("模型训练完成!")
# 存储模型参数
MODEL_PATH = 'cifar_lenet5.pth'
torch.save(net.state_dict(), MODEL_PATH)
print(f"模型参数已保存至 {MODEL_PATH}")
# 加载模型并进行测试
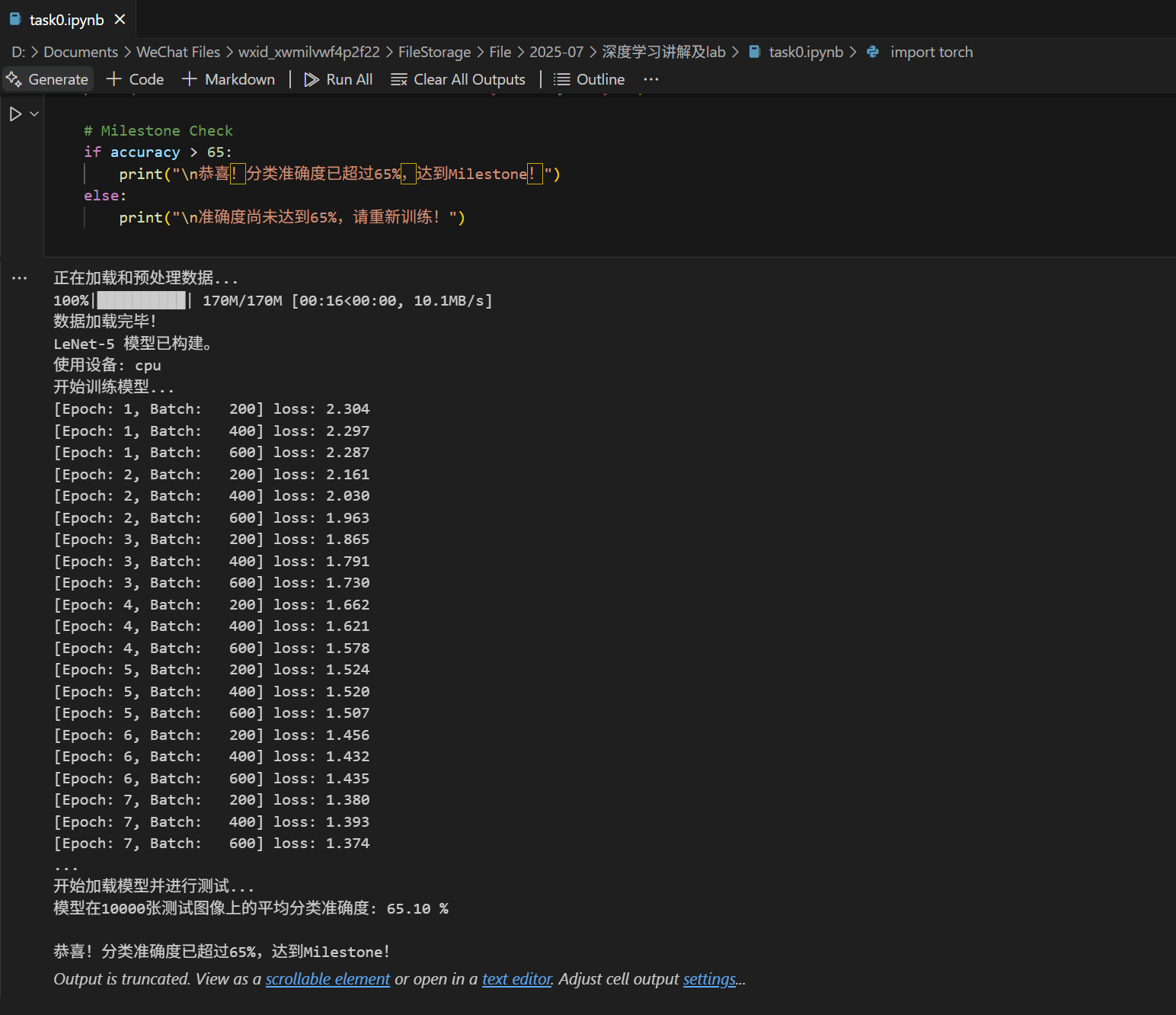
print("\n开始加载模型并进行测试...")
# 创建一个新的模型实例并加载已保存的参数
trained_net = LeNet5()
trained_net.load_state_dict(torch.load(MODEL_PATH))
trained_net.to(device)
# 将模型设置为评估模式(这会关闭dropout等层)
trained_net.eval()
correct = 0
total = 0
# 在测试时,我们不需要计算梯度
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
# 运行模型得到预测输出
outputs = trained_net(images)
# 获取最可能的预测类别
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算并打印平均分类准确度
accuracy = 100 * correct / total
print(f'模型在10000张测试图像上的平均分类准确度: {accuracy:.2f} %')
# Milestone Check
if accuracy > 65:
print("\n恭喜!分类准确度已超过65%,达到Milestone!")
else:
print("\n准确度尚未达到65%,请重新训练!")
Task #1: 将预训练深度卷积模型在CIFAR-10上做迁移
目标
- 掌握模型迁移学习概念
- 掌握模型迁移学习的基本方法
实验内容
- 从torchvision上下载预训练的深度卷积神经网络,如ResNet、VGG等
- 调整网络结构,使其适配CIFAR-10数据集分类任务冻结特征提取部分,训练分类头
- 加载测试集,计算迁移后模型的平均分类准确度
- Milestone:分类准确度超过90%
实验过程
深度神经网络的成功往往依赖于海量标注数据和强大的计算资源。迁移学习(Transfer Learning)为在数据或资源有限的场景下构建高性能模型提供了有效的解决方案。其核心思想是,将在大型通用数据集(如ImageNet)上训练好的模型所学到的知识“迁移”到新的、特定的任务中。
本次实验涉及两种主要的迁移学习策略:
- 特征提取 (Feature Extraction):此策略假定预训练模型(如ResNet)的卷积基础层已经学习到了足够通用的视觉特征。因此,我们冻结这部分网络,仅替换并训练顶部的分类层,使其适应新数据集的类别。此方法训练速度快,计算开销小。
- 微调 (Fine-tuning):此策略在特征提取的基础上更进一步。在初步训练好新的分类头之后,解冻一部分甚至全部预训练的卷积层,并使用一个非常低的学习率对整个网络进行训练。这使得模型能够在不遗忘通用知识的前提下,微调其特征以更好地适应新数据集的特定分布,通常能带来更高的性能。
具体流程如下:
- 数据准备
- 加载CIFAR-10数据集。
- 定义数据变换(
transforms):将32×32的图像缩放至ResNet-18所需的224×224尺寸。对训练集进行随机裁剪、水平翻转等数据增强操作。 - 使用ImageNet的均值和标准差对所有图像进行归一化。
- 创建
DataLoader以进行批量加载。
- 模型构建
- 从
torchvision.models加载预训练的ResNet-18模型。 - 替换其原有的全连接层(
model.fc),使其输出维度从1000(ImageNet类别数)变为10(CIFAR-10类别数)。
- 从
- 训练策略
- 方法A:特征提取(初始方案)
- 冻结除新替换的
model.fc层外的所有网络层参数(param.requires_grad = False)。 - 定义优化器,使其只更新
model.fc层的参数。 - 进行10个周期的训练。
- 但仅使用特征提取的方法,最后的测试率只有78.18%,效果一般,提供了有效的基线,但未达到90%的目标。
- 冻结除新替换的
- 方法B:两阶段微调(优化方案)
- 阶段一(特征提取):同方法A,但只训练较少周期(例如5个),以快速训练分类头
- 阶段二(微调):
- 解冻模型的所有层(
param.requires_grad = True)。 - 重新定义一个优化器,包含模型的所有参数,并设置一个非常低的学习率(例如
1e-4)。 - 继续进行若干周期(例如10个)的训练,微调整个网络。
- 解冻模型的所有层(
- 方法A:特征提取(初始方案)
完整的代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import time
def main():
"""
主函数,执行整个迁移学习流程。
"""
# --- 1. 设备配置 ---
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
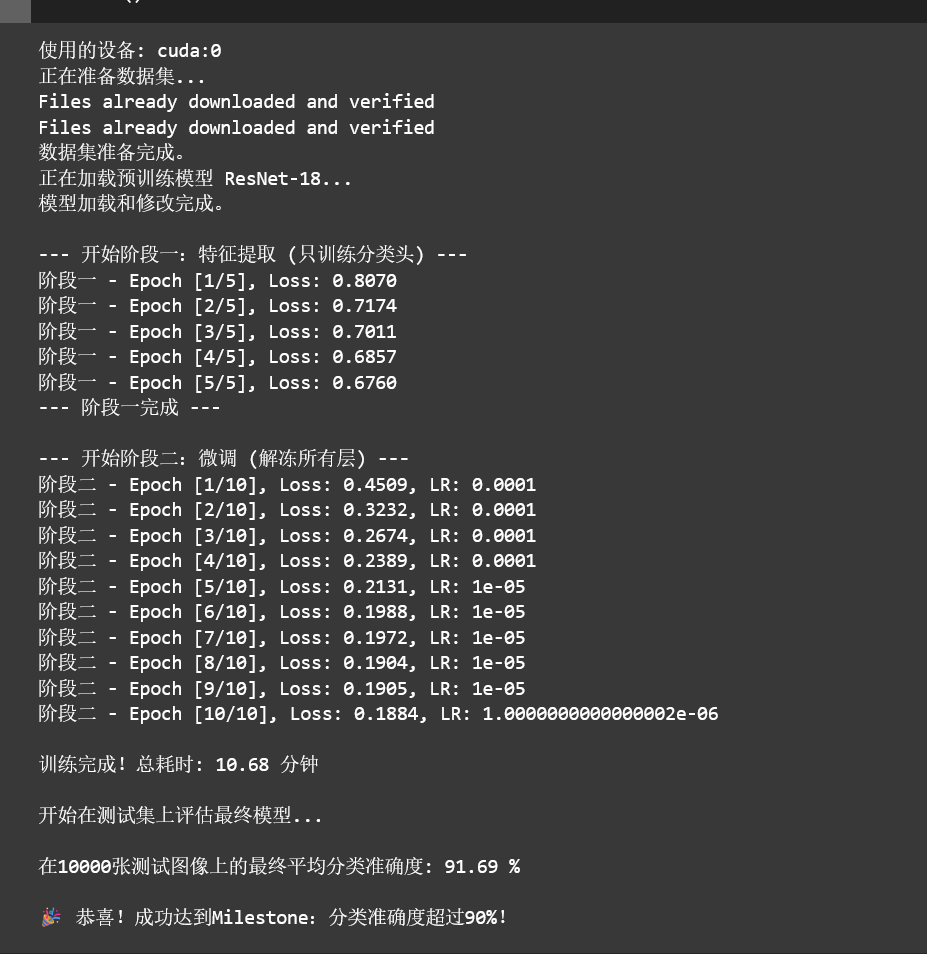
print(f"使用的设备: {device}")
# --- 2. 数据加载与预处理 ---
print("正在准备数据集...")
transform_train = transforms.Compose([
transforms.Resize(224),
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
transform_test = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
try:
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
except Exception as e:
print(f"数据下载失败,请检查网络连接。错误信息: {e}")
return
trainloader = DataLoader(trainset, batch_size=64, shuffle=True, num_workers=4, pin_memory=True)
testloader = DataLoader(testset, batch_size=64, shuffle=False, num_workers=4, pin_memory=True)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
print("数据集准备完成。")
# --- 3. 加载预训练模型并修改网络结构 ---
# 【重要】我们使用 'ResNet18_Weights.DEFAULT' 来获取最新的预训练权重
print("正在加载预训练模型 ResNet-18...")
model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
# 获取最后一个全连接层(fc)的输入特征数
num_ftrs = model.fc.in_features
# 替换为新的分类头
model.fc = nn.Linear(num_ftrs, len(classes))
model = model.to(device)
print("模型加载和修改完成。")
# --- 4. 两阶段训练 ---
criterion = nn.CrossEntropyLoss()
start_time = time.time()
# === 阶段一:只训练分类头 ===
print("\n--- 开始阶段一:特征提取 (只训练分类头) ---")
# 首先冻结所有层
for param in model.parameters():
param.requires_grad = False
# 然后解冻我们新加的fc层
for param in model.fc.parameters():
param.requires_grad = True
# 为分类头创建一个新的优化器
optimizer_head = optim.SGD(model.fc.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
num_epochs_head = 5 # 先训练5个epoch
for epoch in range(num_epochs_head):
model.train()
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer_head.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer_head.step()
running_loss += loss.item()
print(f'阶段一 - Epoch [{epoch + 1}/{num_epochs_head}], Loss: {running_loss / len(trainloader):.4f}')
print("--- 阶段一完成 ---")
# === 阶段二:微调整个网络 ===
print("\n--- 开始阶段二:微调 (解冻所有层) ---")
# 解冻所有层,让它们都可以被训练
for param in model.parameters():
param.requires_grad = True
# 为整个网络创建一个新的优化器,使用一个非常低的学习率
# 这是微调的关键!
optimizer_finetune = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer_finetune, step_size=5, gamma=0.1) # 学习率衰减
num_epochs_finetune = 10 # 微调10个epoch
for epoch in range(num_epochs_finetune):
model.train()
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer_finetune.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer_finetune.step()
running_loss += loss.item()
# 每个epoch后更新学习率并打印
scheduler.step()
print(f'阶段二 - Epoch [{epoch + 1}/{num_epochs_finetune}], Loss: {running_loss / len(trainloader):.4f}, LR: {scheduler.get_last_lr()[0]}')
end_time = time.time()
print(f'\n训练完成!总耗时: {(end_time - start_time) / 60:.2f} 分钟')
# --- 5. 测试模型 ---
print("\n开始在测试集上评估最终模型...")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'\n在10000张测试图像上的最终平均分类准确度: {accuracy:.2f} %')
# --- 6. Milestone检查 ---
if accuracy > 90:
print("\n🎉 恭喜!成功达到Milestone:分类准确度超过90%!")
else:
print("\n- 准确度未达到90%目标。")
if __name__ == '__main__':
main()
这里我使用的是学姐上课说的那个算力平台,因为我本地有点带不动:
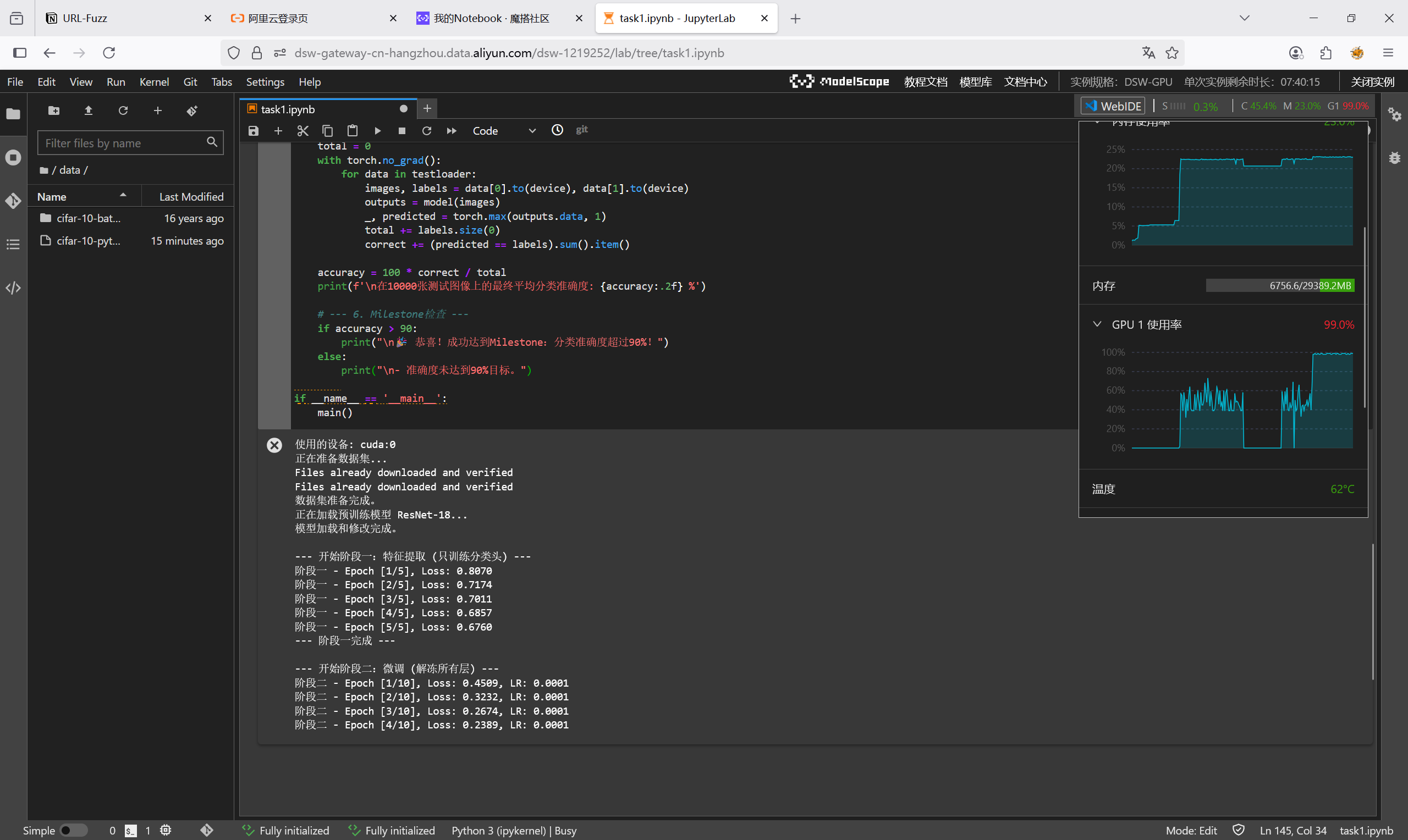
最后的实验结果如下: