Task #0: 用脚本请求商用大模型
目标
- 学会使用python脚本请求商用大模型
实验内容
- 注册并选择硅基流动上的任意大语言模型作为你的实验对象 ,获取免费额度
- 阅读文档,撰写Python脚本,实现对大模型的自动化请求包装成一个名为chat的函数,便于后面使用
实验流程
先去https://cloud.siliconflow.cn注册一个号,拿到api,这里就选不要钱的模型了,然后写个简单的方法,传入的参数是想问的问题,返回是llm的回答,完整代码如下:
from langchain_openai import ChatOpenAI
API_KEY = "sk-xxx"
BASE_URL = "https://api.siliconflow.cn/v1/"
MODEL_NAME = "deepseek-ai/DeepSeek-R1-0528-Qwen3-8B"
# --- 全局 LLM 实例 ---
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL_NAME,
temperature=0.7
)
def ask(question: str) -> str:
"""
向大语言模型提问并获取纯文本回答。
参数:
- question (str): 你想要问的问题。
返回:
- str: 大语言模型返回的回答内容。
"""
try:
# 使用 llm.invoke() 方法发送请求
response_message = llm.invoke(question)
# 从返回的 AIMessage 对象中提取 .content 属性,即模型的回答文本
return response_message.content
except Exception as e:
print(f"请求模型时发生错误: {e}")
return "抱歉,无法获取回答。"
if __name__ == "__main__":
my_question = "永雏塔菲是什么?"
answer = ask(my_question)
print(answer)
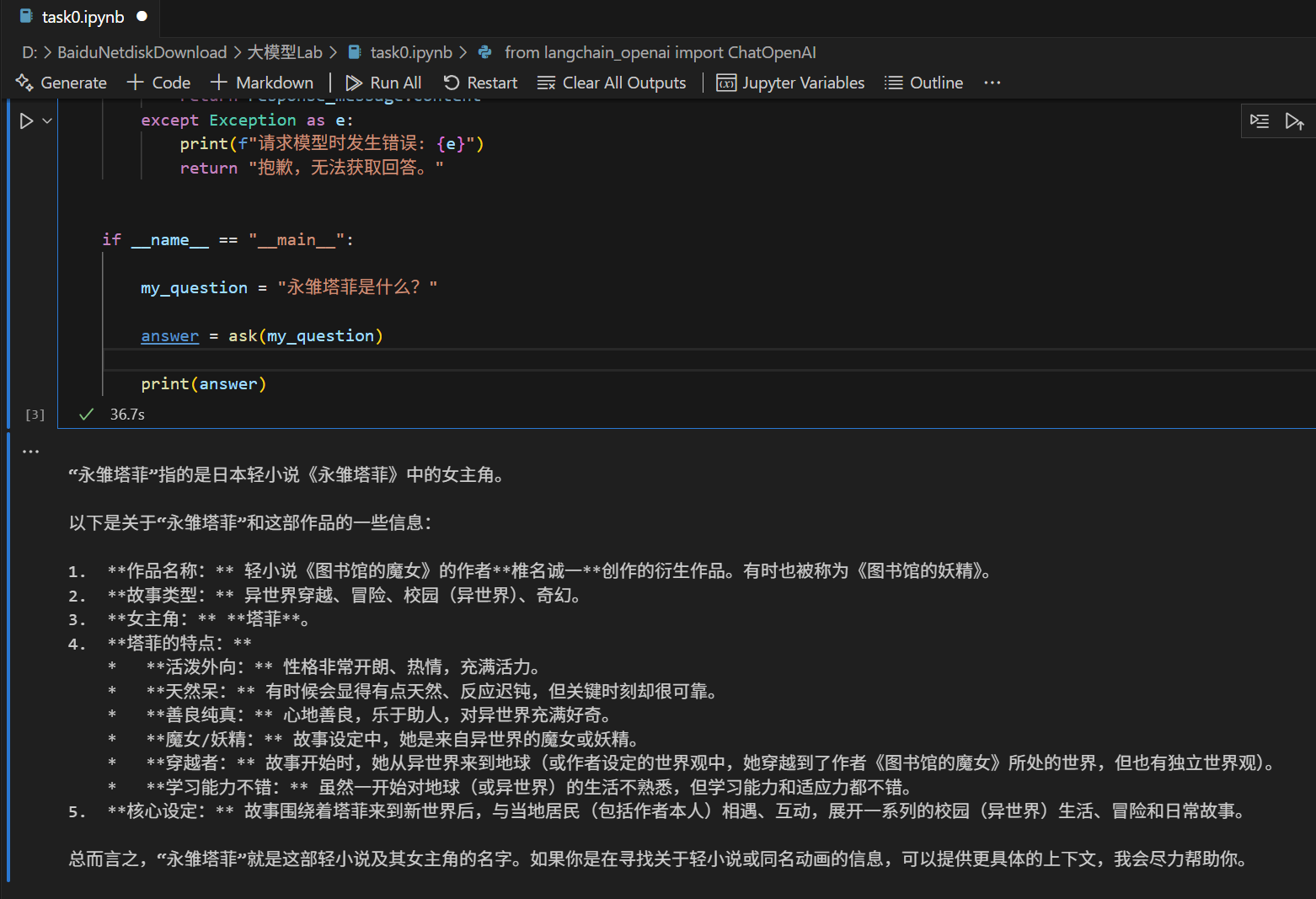
Task #1: 大模型能力评测和上下文学习(In-Context Learning)
目标
- 理解大模型能力测评的全流程
- 理解0-shot和few-shot的概念
- 学会In-Context Learning
实验内容
- 学习大模型能力选择题Benchmark C-Eval
- 选择50个测试问题,对0x0中的大模型进行评测,对比0—shot和5—shot的结果
实验流程
我们不能简单地通过聊天来判断一个模型的好坏。需要一套标准化、可复现的流程,包括:
- 基准 (Benchmark):一个或多个标准化的数据集,用来测试模型的特定能力(如常识推理、代码生成、数学计算等)。
- 指标 (Metric):量化模型表现的方式,对于选择题,最常用的就是“准确率 (Accuracy)”。
- 方法 (Method):如何向模型提问,比如是直接提问(0-shot)还是给一些例子再提问(Few-shot)
上下文学习这是现代大模型(如GPT系列)最惊人的能力之一,不需要重新训练模型,只需在输入的提示(Prompt)中提供几个示例(“shots”),模型就能“秒懂”你的任务要求和输出格式,并给出更高质量的回答。
- 0-shot (零样本):不给任何示例,直接向模型提出问题。这考验的是模型在预训练阶段学到的通用知识和推理能力。
- 例子:“中国的首都是哪里?A. 上海 B. 北京” -> 模型回答
- Few-shot (少样本):在提问前,先给出几个“问题 + 正确答案”的范例。这能帮助模型更好地理解任务的意图和期望的输出格式。
- 例子:“问题:法国的首都是哪里?答案:巴黎。 问题:日本的首都是哪里?答案:东京。 问题:中国的首都是哪里?” -> 模型回答
学长说的那个网站的接口有点慢,换了一个,用的数据集是boolq_train
import re
from tqdm import tqdm
from datasets import load_dataset, load_from_disk
from langchain_openai import ChatOpenAI
import os
API_KEY = "sk-xxxx"
BASE_URL = "https://api.gptgod.online/v1/"
MODEL_NAME = "gpt-3.5-turbo"
# --- 评测数据集配置 ---
EVAL_SUBJECT = "boolq"
CACHE_DIR = ".boolq_cache"
print(f"正在初始化模型: {MODEL_NAME}...")
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL_NAME,
temperature=0.1,
request_timeout=60,
)
def normalize_answer(raw_answer):
return "A" if raw_answer is True else "B"
def ask(question: str) -> str:
try:
response_message = llm.invoke(question)
return response_message.content.strip()
except Exception as e:
print(f"\n[错误] 请求模型时发生错误: {e}")
return "ERROR"
def parse_model_answer(model_output: str) -> str:
if "是" in model_output or "对" in model_output or "A" in model_output:
return "A"
elif "否" in model_output or "不" in model_output or "B" in model_output:
return "B"
else:
match = re.search(r"[A-B]", model_output.upper())
return match.group(0) if match else ""
def load_boolq_data(num_questions: int = 50):
os.makedirs(CACHE_DIR, exist_ok=True)
cache_path = os.path.join(CACHE_DIR, "boolq_train")
if os.path.exists(cache_path):
print(f"正在从本地缓存加载数据集:{cache_path}")
dataset = load_from_disk(cache_path)
else:
print("从 Hugging Face 下载 boolq 数据集...")
dataset = load_dataset("boolq", split="train")
dataset.save_to_disk(cache_path)
dataset = dataset.shuffle(seed=42)
eval_questions = dataset.select(range(num_questions))
shot_examples = dataset.select(range(5))
return eval_questions, shot_examples
def run_evaluation(eval_type: str, questions, shots=None):
print(f"\n--- 开始 {eval_type.upper()} 评测 ---")
correct_count = 0
for idx, q in enumerate(tqdm(questions, desc=f"{eval_type.capitalize()} Progress")):
passage = q["passage"]
question = q["question"]
correct_letter = normalize_answer(q["answer"])
if eval_type == "0-shot":
prompt = f"""请根据下面的段落判断问题的答案是“是”还是“否”。请直接回答字母。
段落:{passage}
问题:{question}
选项:
A. 是
B. 否
答案:"""
else:
shot_prompt = ""
for shot in shots:
shot_passage = shot["passage"]
shot_question = shot["question"]
shot_answer = "A" if shot["answer"] else "B"
shot_prompt += f"段落:{shot_passage}\n问题:{shot_question}\n答案:{shot_answer}\n\n"
prompt = f"""你将看到一些判断题,请根据段落内容直接判断“是”还是“否”,回答字母 A 或 B。
A. 是
B. 否
{shot_prompt}段落:{passage}
问题:{question}
答案:"""
model_output = ask(prompt)
predicted_letter = parse_model_answer(model_output)
if predicted_letter == correct_letter:
correct_count += 1
accuracy = correct_count / len(questions)
print(f"\n--- {eval_type.upper()} 评测完成 ---")
print(f"总题数: {len(questions)}, 正确数: {correct_count}, 准确率: {accuracy:.2%}")
return accuracy
if __name__ == "__main__":
eval_questions, shot_examples = load_boolq_data(num_questions=50)
zero_shot_accuracy = run_evaluation("0-shot", eval_questions)
five_shot_accuracy = run_evaluation("5-shot", eval_questions, shot_examples)
print("\n\n" + "="*30)
print(" 评测结果汇总")
print("="*30)
print(f" 模型 : {MODEL_NAME}")
print(f" 数据集 : {EVAL_SUBJECT}")
print(f" 问题数量 : {len(eval_questions)}")
print("-" * 30)
print(f" 0-Shot 准确率: {zero_shot_accuracy:.2%}")
print(f" 5-Shot 准确率: {five_shot_accuracy:.2%}")
print("="*30)
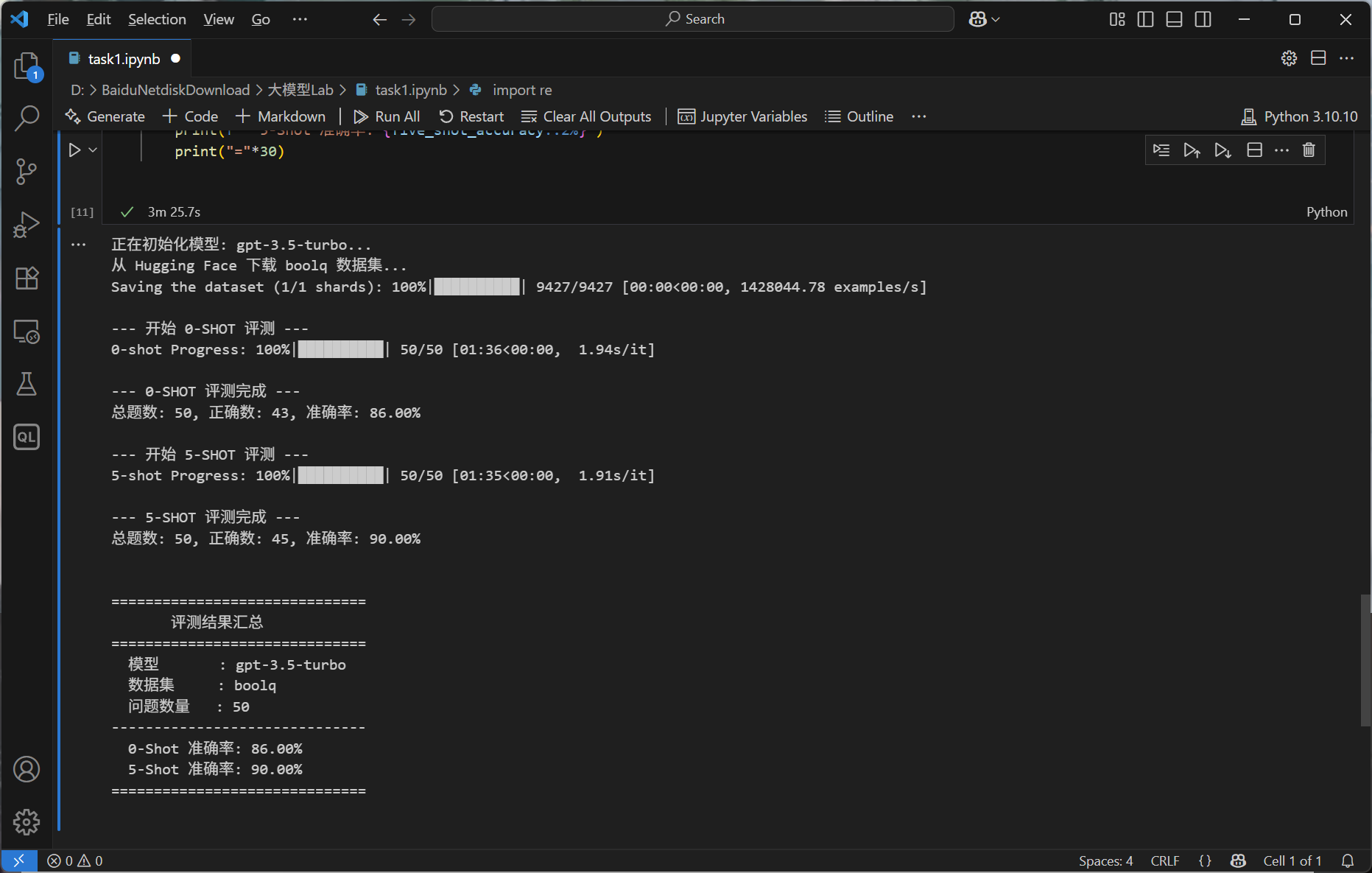
可以看到有few-shot的话,准确率会高一点
Task #2: 学会使用文本Embedding
目标
- 理解文本embedding模型的结构
- 部署和使用embedding model
实验内容
- 学习基于language model的文本
- embedding参考BERT模型原文 https://arxiv.org/abs/1810.04805
- 参考SentBERT https://arxiv.org/abs/1908.10084
- 尝试在自己的电脑上或者modelscope平台的云服务器上部署一个embedding模型(无需GPU)
- GTE文本向量-英文-通用领域-small https://www.modelscope.cn/models/iic/nlp_gte_sentence-embedding_english-small/summary
- GTE文本向量-中文-通用领域-small https://www.modelscope.cn/models/iic/nlp_gte_sentence-embedding_chinese-small/summary
- 思考并尝试:Embedding模型有什么用?自己设计一个Case
实验流程
Embedding是将文本转换为固定维度向量的过程,使其能被计算机理解,通常embedding模型是语言模型的一部分,比如 BERT、GTE,它们会抽取文本的语义信息。
直接抄的nlp_gte_sentence-embedding_chinese-small官网的代码例子:
from modelscope.models import Model
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_id = "iic/nlp_gte_sentence-embedding_chinese-small"
pipeline_se = pipeline(Tasks.sentence_embedding,
model=model_id,
sequence_length=512
, model_revision='master') # sequence_length 代表最大文本长度,默认值为128
# 当输入包含“soure_sentence”与“sentences_to_compare”时,会输出source_sentence中首个句子与sentences_to_compare中每个句子的向量表示,以及source_sentence中首个句子与sentences_to_compare中每个句子的相似度。
inputs = {
"source_sentence": ["吃完海鲜可以喝牛奶吗?"],
"sentences_to_compare": [
"不可以,早晨喝牛奶不科学",
"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",
"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",
"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"
]
}
result = pipeline_se(input=inputs)
print (result)
# 当输入仅含有soure_sentence时,会输出source_sentence中每个句子的向量表示。
inputs2 = {
"source_sentence": [
"不可以,早晨喝牛奶不科学",
"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",
"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",
"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"
]
}
result = pipeline_se(input=inputs2)
print (result)
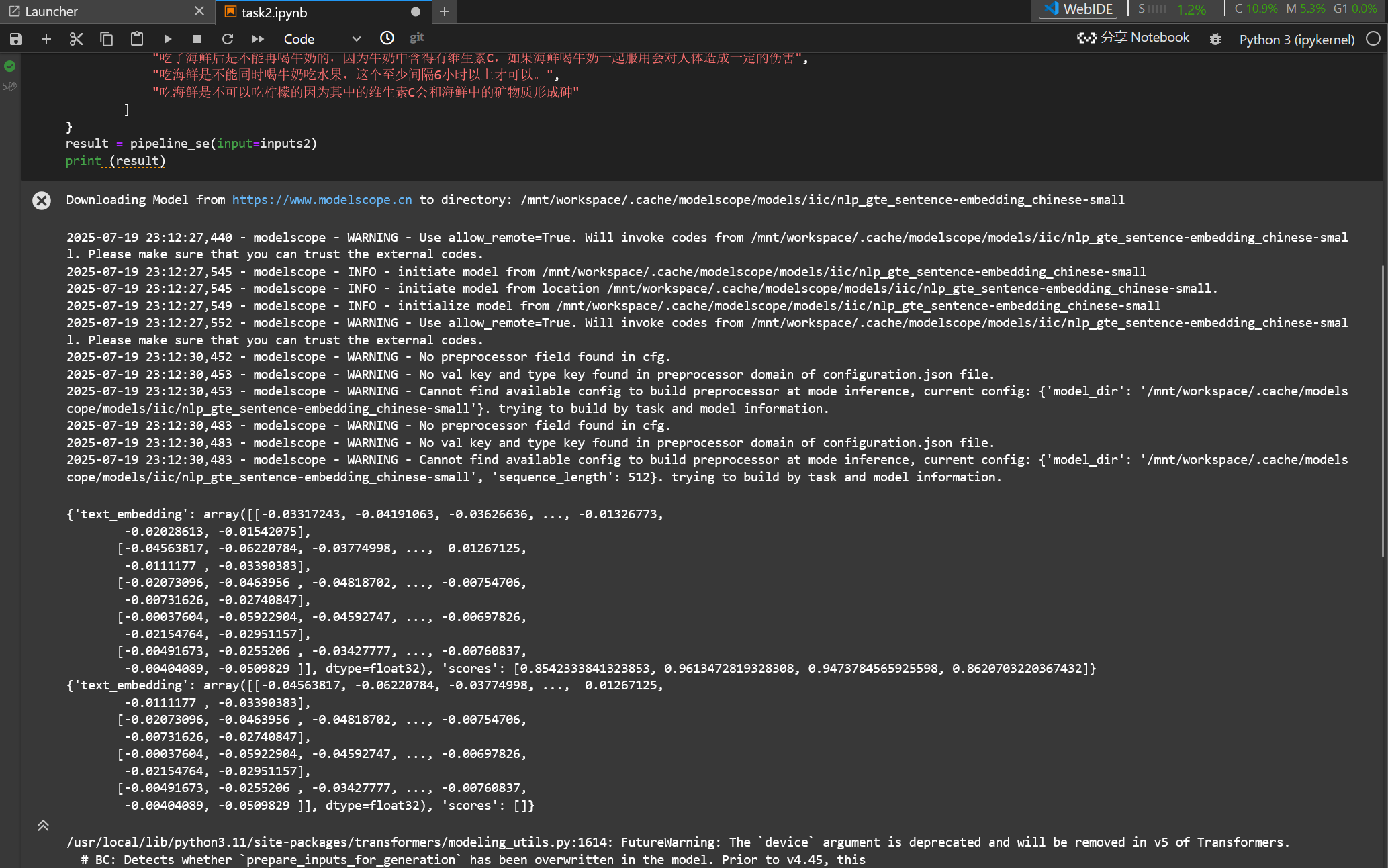
可以看到输出每个句子的向量表示。
这里其实可以想到最简单的运用,就是给定一个源句子和一组候选句子,程序会自动找出与源句子意思最相近的那个候选句子,并把它打印出来,也就是利用相似度找句子。
import numpy as np
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
print("正在加载模型,请稍候...")
model_id = "iic/nlp_gte_sentence-embedding_chinese-small"
pipeline_se = pipeline(Tasks.sentence_embedding,
model=model_id,
sequence_length=512,
model_revision='master')
print("模型加载完毕!\n")
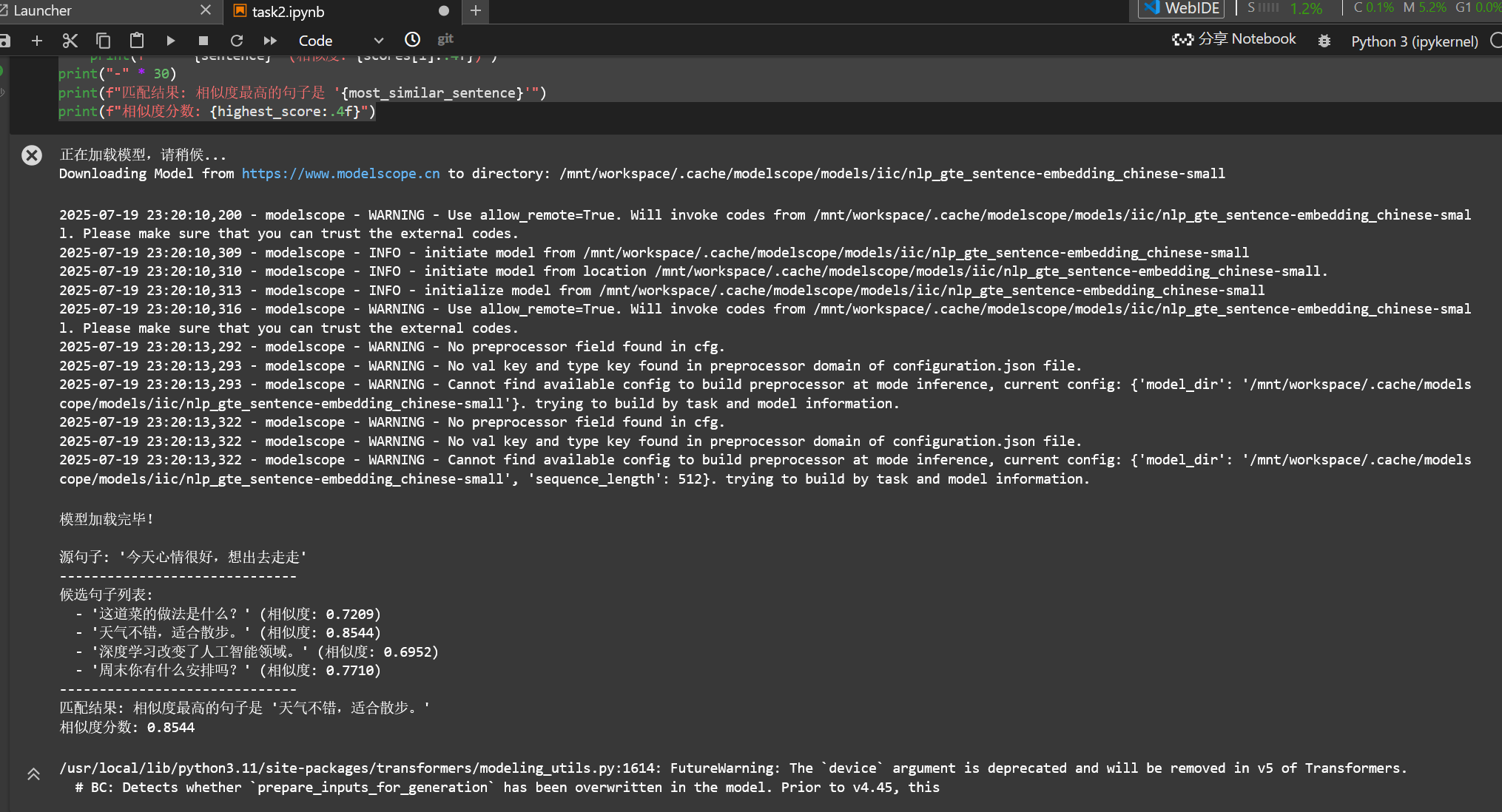
source_sentence = "今天心情很好,想出去走走"
sentences_to_compare = [
"这道菜的做法是什么?",
"天气不错,适合散步。",
"深度学习改变了人工智能领域。",
"周末你有什么安排吗?"
]
inputs = {
"source_sentence": [source_sentence],
"sentences_to_compare": sentences_to_compare
}
result = pipeline_se(input=inputs)
scores = result['scores']
# 使用numpy找到分数列表中的最大值及其索引
highest_score = np.max(scores)
best_match_index = np.argmax(scores)
# 通过索引找到最匹配的句子
most_similar_sentence = sentences_to_compare[best_match_index]
print(f"源句子: '{source_sentence}'")
print("-" * 30)
print("候选句子列表:")
for i, sentence in enumerate(sentences_to_compare):
print(f" - '{sentence}' (相似度: {scores[i]:.4f})")
print("-" * 30)
print(f"匹配结果: 相似度最高的句子是 '{most_similar_sentence}'")
print(f"相似度分数: {highest_score:.4f}")
Task #3: 知识库构建和向量索引
目标
- 学习构建向量知识库
实验内容
- 找一篇你感兴趣的文章
- 学习Langchain中TextSplitter的概念,将文章分成chunks
- 使用#2中构建的Embedding模型,将chunks转换为embedding
- 学习FAISS向量数据库的概念和使用方法基于这篇文章构建并保存一个VectorStore,并能够读取
实验流程
当我们处理一篇长文章时(例如几千上万字),会遇到一个很实际的问题:大部分深度学习模型,包括我们在任务 #2 中使用的 Embedding 模型,都有一个输入长度限制(Context Window)。例如,GTE-small 模型的最大长度是512个字符。我们不可能把整篇文章一次性丢给模型来生成一个单一的向量,这样做不仅会超出限制,而且生成的向量也无法很好地代表文章中具体、细节的语义。TextSplitter的作用就是将一篇长文档,按照预设的规则,切分成多个更小的、语义完整的文本块(Chunks)
在我们将文章切分成数百上千个 chunks,并把它们都转换成向量之后,又来了一个新问题:当用户提问时,我们如何快速地从这成百上千个向量中,找到与问题向量最相似的那几个?最朴素的方法是:用问题向量和知识库里的每一个向量逐一计算相似度,然后排序。当知识库很小时可行,但当有成千上万个向量时,这个过程会变得极其缓慢。
FAISS (Facebook AI Similarity Search) 就是为了解决这个问题而生的。它是一个专门为海量向量进行高效相似度搜索和聚类的开源库。FAISS 并不是一个传统意义上的数据库(如MySQL),它更像一个向量索引。它通过内部的特殊算法(如LSH、HNSW等)对向量进行预先组织和划分,建立索引。当进行搜索时,它不需要进行“暴力”的逐一比较,而是能通过索引快速定位到最可能相似的向量区域,从而实现毫秒级的快速检索。它速度极快,并且可以完全在本地运行(faiss-cpu 版本),非常适合构建个人或中小型的本地知识库。
这里我们选择抓取永雏塔菲的百度百科:https://baike.baidu.com/item/%E6%B0%B8%E9%9B%8F%E5%A1%94%E8%8F%B2/61675407,建立本地数据库
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from typing import List
from langchain.embeddings.base import Embeddings
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
def load_document_from_local_file(file_path):
"""使用TextLoader从本地的.txt文件加载文档内容。"""
print(f"正在从本地文件加载文档: {file_path}")
if not os.path.exists(file_path):
print(f"错误: 文件 '{file_path}' 不存在。")
return None
# 使用 TextLoader 并指定 utf-8 编码
loader = TextLoader(file_path, encoding='utf-8')
try:
docs = loader.load()
print("文档加载成功!")
return docs
except Exception as e:
print(f"加载文档时出错: {e}")
return None
# 文本切分: 将加载的文档切分为小块 (Chunks)
def split_documents_into_chunks(docs):
"""将加载的文档列表切分为更小的文本块。"""
if not docs:
print("没有文档可以切分。")
return []
print("\n正在将文档切分为文本块 (Chunks)...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个chunk的最大长度(字符数)
chunk_overlap=50, # chunk之间的重叠长度
length_function=len,
is_separator_regex=False,
)
chunks = text_splitter.split_documents(docs)
print(f"切分完成,共得到 {len(chunks)} 个文本块。")
return chunks
# 初始化Embedding模型
def initialize_embedding_model():
"""
初始化用于将文本转换为向量的嵌入模型。
使用ModelScope Pipeline并包装成Langchain兼容的Embeddings类。
"""
print("\n正在初始化ModelScope Embedding模型 (GTE-small)...")
class ModelScopeEmbeddings(Embeddings):
def __init__(self, model_id):
self.pipeline_se = pipeline(
Tasks.sentence_embedding,
model=model_id,
sequence_length=512
)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
inputs = {"source_sentence": texts}
result = self.pipeline_se(input=inputs)
return result['text_embedding']
def embed_query(self, text: str) -> List[float]:
inputs = {"source_sentence": [text]}
result = self.pipeline_se(input=inputs)
return result['text_embedding'][0]
model_id = "iic/nlp_gte_sentence-embedding_chinese-small"
embedding_model = ModelScopeEmbeddings(model_id=model_id)
print("ModelScope Embedding模型初始化成功!")
return embedding_model
# 构建、保存与加载FAISS向量数据库
def create_and_load_vectorstore(chunks, embedding_model, save_path):
"""构建、保存并从本地重新加载FAISS向量数据库。"""
if not chunks:
print("没有文本块可以创建索引。")
return None
print("\n正在将文本块转换为向量并构建FAISS索引...")
vector_store = FAISS.from_documents(chunks, embedding_model)
vector_store.save_local(save_path)
print(f"FAISS索引已成功构建并保存到: '{save_path}'")
print(f"\n正在从 '{save_path}' 加载FAISS索引...")
loaded_vector_store = FAISS.load_local(
save_path,
embedding_model,
allow_dangerous_deserialization=True
)
print("FAISS索引加载成功!")
return loaded_vector_store
# 执行语义搜索
def search_in_vectorstore(vector_store, query):
"""在向量数据库中执行语义搜索。"""
print("\n--------------------------------------------------")
print(f"开始执行语义搜索,查询内容: '{query}'")
results = vector_store.similarity_search_with_score(query, k=3)
if not results:
print("未找到相关结果。")
return
print("\n搜索结果如下:")
for i, (doc, score) in enumerate(results):
print(f"\n--- [结果 {i+1} | 相似度得分: {score:.4f}] ---")
print(doc.page_content)
print("\n--------------------------------------------------")
if __name__ == "__main__":
# 指定要读取的本地 1.txt 文件
LOCAL_FILE_PATH = "1.txt"
FAISS_INDEX_PATH = "faiss_yongchu_tafei_index"
# 调用修改后的函数从本地文件加载
documents = load_document_from_local_file(LOCAL_FILE_PATH)
if documents:
text_chunks = split_documents_into_chunks(documents)
embedding_model = initialize_embedding_model()
db = create_and_load_vectorstore(text_chunks, embedding_model, FAISS_INDEX_PATH)
if db:
test_query_1 = "永雏塔菲是谁?"
search_in_vectorstore(db, test_query_1)
test_query_2 = "永雏塔菲的年龄?"
search_in_vectorstore(db, test_query_2)
Task #4: Retrieval-Augmented Generation(检索增强生成)
目标
- 理解RAG的原理
- 手搓RAG
实验内容
- 自行搜集资料,学习RAG的机制
- 基于#0的实现的大模型接口,#1的上下文学习和#3的Vectorstore,做一个根据文章内容的QA应用(注意:禁止使用Langchain,请自行实现RAG的流程)
实验流程
没太懂禁止使用Langchain什么意思,应该是只要自己实现RAG过程就行了吧,我这里是使用了Task 3的数据库,然后自己实现了向量检索和上下文添加,让llm在有上下文的基础上回答问题,代码如下:
import os
from typing import List
from langchain_community.vectorstores import FAISS
from langchain.embeddings.base import Embeddings
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 检索器加载工具
def initialize_embedding_model():
"""初始化用于将文本转换为向量的嵌入模型。"""
print("正在初始化ModelScope Embedding模型 (GTE-small)...")
class ModelScopeEmbeddings(Embeddings):
def __init__(self, model_id):
self.pipeline_se = pipeline(Tasks.sentence_embedding, model=model_id, sequence_length=512)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
inputs = {"source_sentence": texts}; return self.pipeline_se(input=inputs)['text_embedding']
def embed_query(self, text: str) -> List[float]:
inputs = {"source_sentence": [text]}; return self.pipeline_se(input=inputs)['text_embedding'][0]
embedding_model = ModelScopeEmbeddings(model_id="iic/nlp_gte_sentence-embedding_chinese-small")
print("Embedding模型初始化成功!")
return embedding_model
def load_vectorstore(load_path: str, embedding_model: Embeddings) -> FAISS:
"""从本地磁盘加载FAISS向量数据库。"""
if not os.path.exists(load_path):
print(f"错误: 索引路径 '{load_path}' 不存在。")
return None
print(f"正在从 '{load_path}' 加载FAISS索引...")
try:
vector_store = FAISS.load_local(load_path, embedding_model, allow_dangerous_deserialization=True)
print("FAISS索引加载成功!")
return vector_store
except Exception as e:
print(f"加载FAISS索引时出错: {e}")
return None
# 大语言模型生成器接口
def get_llm_response(prompt: str) -> str:
"""ni
调用指定的ChatOpenAI接口并返回生成的文本。
"""
API_KEY = "sk-xxxx"
BASE_URL = "https://api.gptgod.online/v1/"
MODEL_NAME = "gpt-3.5-turbo"
print(f"正在调用大语言模型: {MODEL_NAME} at {BASE_URL}...")
try:
# 初始化ChatOpenAI客户端
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL_NAME,
temperature=0.1,
request_timeout=60,
)
# Langchain的LLM通常接收一个消息列表
messages = [HumanMessage(content=prompt)]
# 发起调用
response = llm.invoke(messages)
print("大模型调用成功!")
# 从返回的AIMessage对象中提取文本内容
return response.content
except Exception as e:
error_message = f"调用LLM时发生错误: {e}"
print(error_message)
return error_message
# 手动实现的RAG核心流程
def answer_question_with_rag(query: str, vector_store: FAISS):
"""
手动实现的RAG流程,用于回答用户问题。
"""
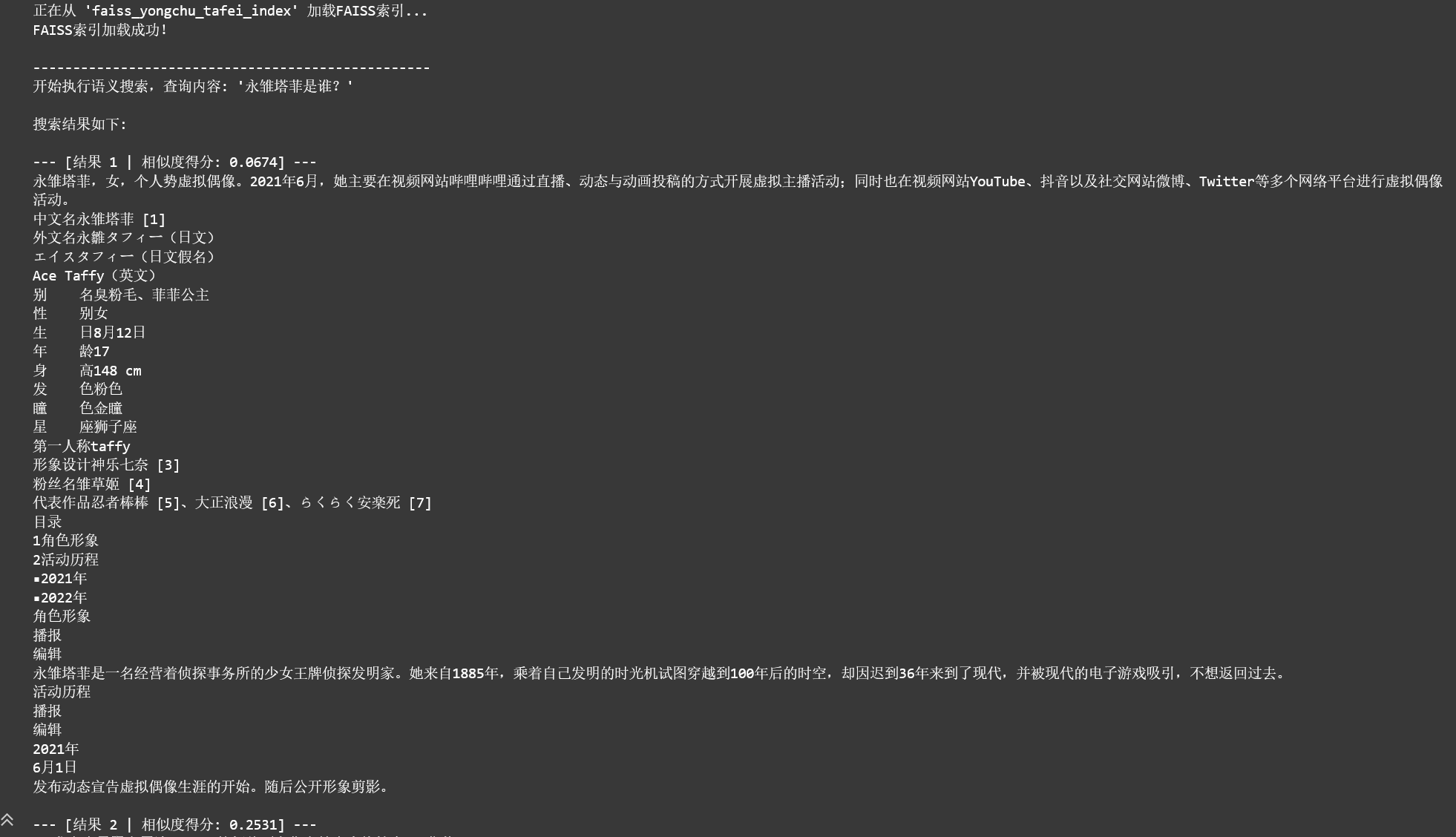
print(f"\n================== 开始RAG流程 ==================")
print(f"用户问题: {query}")
# 检索 (Retrieve)
print("\n[步骤 1/3] 检索相关文档...")
retrieved_docs = vector_store.similarity_search(query, k=3)
if not retrieved_docs:
return "抱歉,我无法在·的文档中找到相关信息来回答这个问题。"
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
print("检索到的上下文信息:")
print("--------------------------------------------------")
print(context)
print("--------------------------------------------------")
# 增强 (Augment) - 构建Prompt
print("\n[步骤 2/3] 构建增强型Prompt...")
prompt_template = f"""
请严格根据以下提供的【上下文信息】来回答【问题】。
如果【上下文信息】中没有足够的内容来回答问题,请直接说:“根据提供的资料,我无法回答这个问题。”
在你的回答中,不允许编造、假设或使用【上下文信息】之外的任何知识。
【上下文信息】:
{context}
【问题】:
{query}
【回答】:
"""
print("Prompt构建完成。")
# 生成 (Generate) - 调用大模型
print("\n[步骤 3/3] 调用大模型生成最终答案...")
final_answer = get_llm_response(prompt_template)
print("\n================== RAG流程结束 ==================")
return final_answer
if __name__ == "__main__":
# 定义知识库索引的路径
FAISS_INDEX_PATH = "faiss_yongchu_tafei_index"
embedding_model = initialize_embedding_model()
db = load_vectorstore(FAISS_INDEX_PATH, embedding_model)
if db:
test_query_1 = "塔菲的粉丝团体叫什么名字?"
answer_1 = answer_question_with_rag(test_query_1, db)
print(f"\n>>>>>> 最终答案 (问题1: {test_query_1}):\n{answer_1}\n")
test_query_2 = "永雏塔菲的直播内容主要有哪些?"
answer_2 = answer_question_with_rag(test_query_2, db)
print(f"\n>>>>>> 最终答案 (问题2: {test_query_2}):\n{answer_2}\n")
test_query_3 = "永雏塔菲最喜欢什么颜色?"
answer_3 = answer_question_with_rag(test_query_3, db)
print(f"\n>>>>>> 最終答案 (问题3: {test_query_3}):\n{answer_3}\n")
else:
print("\n无法开始问答,因为向量数据库加载失败。")
Task #5: 大语言模型工具增强
目标
- 理解大模型工具调用的原理
- 实现大模型工具调用
实验内容
- 用Python实现一个计算器函数(支持加减乘除)
- 基于Python Flaskapi和Uvicorn将上面这个计算器包装成Local RESTFUL API(比如端口8641)
- 设计相应的工具描述,便于大模型理解并调用工具
- 实现工具调用流程,能够满足用户的复杂计算请求(例如 我想知道129032910921*188231”)
- 设计一组用例,对比工具增强前后大模型的能力差异
实验流程
写一个简单的计算器放在8641端口,作为工具交给llm调用,这里我们的问题就是 129032910921 * 188231 ,对比使用工具的结果和不使用工具让llm直接回答的结果:
import requests
import threading
import time
import logging
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, ToolMessage
from flask import Flask, request, jsonify
import uvicorn
from asgiref.wsgi import WsgiToAsgi
API_HOST = "127.0.0.1"
API_PORT = 8641
CALCULATOR_API_URL = f"http://{API_HOST}:{API_PORT}/calculate"
app = Flask(__name__)
log = logging.getLogger('werkzeug')
log.setLevel(logging.ERROR)
asgi_app = WsgiToAsgi(app)
@app.route('/calculate', methods=['POST'])
def handle_calculate():
data = request.json
if not data or 'expression' not in data: return jsonify({"error": "Missing 'expression'"}), 400
expression = data['expression']
print(f"\n[API Server Log] Received calculation request for: '{expression}'")
try:
result = eval(expression, {"__builtins__": None}, {})
response_data = {"result": str(result)}
print(f"[API Server Log] Returning result: {result}")
except Exception as e:
response_data = {"result": f"Error: {str(e)}"}
print(f"[API Server Log] Calculation error: {e}")
return jsonify(response_data)
def run_api_server():
print(f"--- 启动 API 服务器于 http://{API_HOST}:{API_PORT} (后台线程) ---")
uvicorn.run(
asgi_app,
host=API_HOST,
port=API_PORT,
log_level="warning",
lifespan="off",
loop="asyncio",
interface="asgi3",
timeout_keep_alive=5
)
API_KEY = "sk-xxxx"
BASE_URL = "https://o3.fan/v1"
MODEL_NAME = "deepseek-ai/DeepSeek-V3"
try:
print(f"正在初始化客户端: {MODEL_NAME} at {BASE_URL}...")
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL_NAME,
temperature=0.1,
request_timeout=60,
)
print("客户端初始化成功。")
except Exception as e:
print(f"无法初始化 ChatOpenAI: {e}")
llm = None
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "一个可以执行加、减、乘、除等基本数学运算的计算器。",
"parameters": {
"type": "object", "properties": {"expression": {"type": "string", "description": "需要计算的数学表达式。"}},
"required": ["expression"]
}
}
}
]
llm_with_tools_auto = llm.bind_tools(tools) if llm else None
llm_with_tools_forced = llm.bind_tools(
tools,
tool_choice={"type": "function", "function": {"name": "calculator"}}
) if llm else None
def run_conversation(user_prompt: str, force_tool: bool = False):
if not llm:
print("LLM 客户端未成功初始化,无法执行对话。")
return
print("="*50)
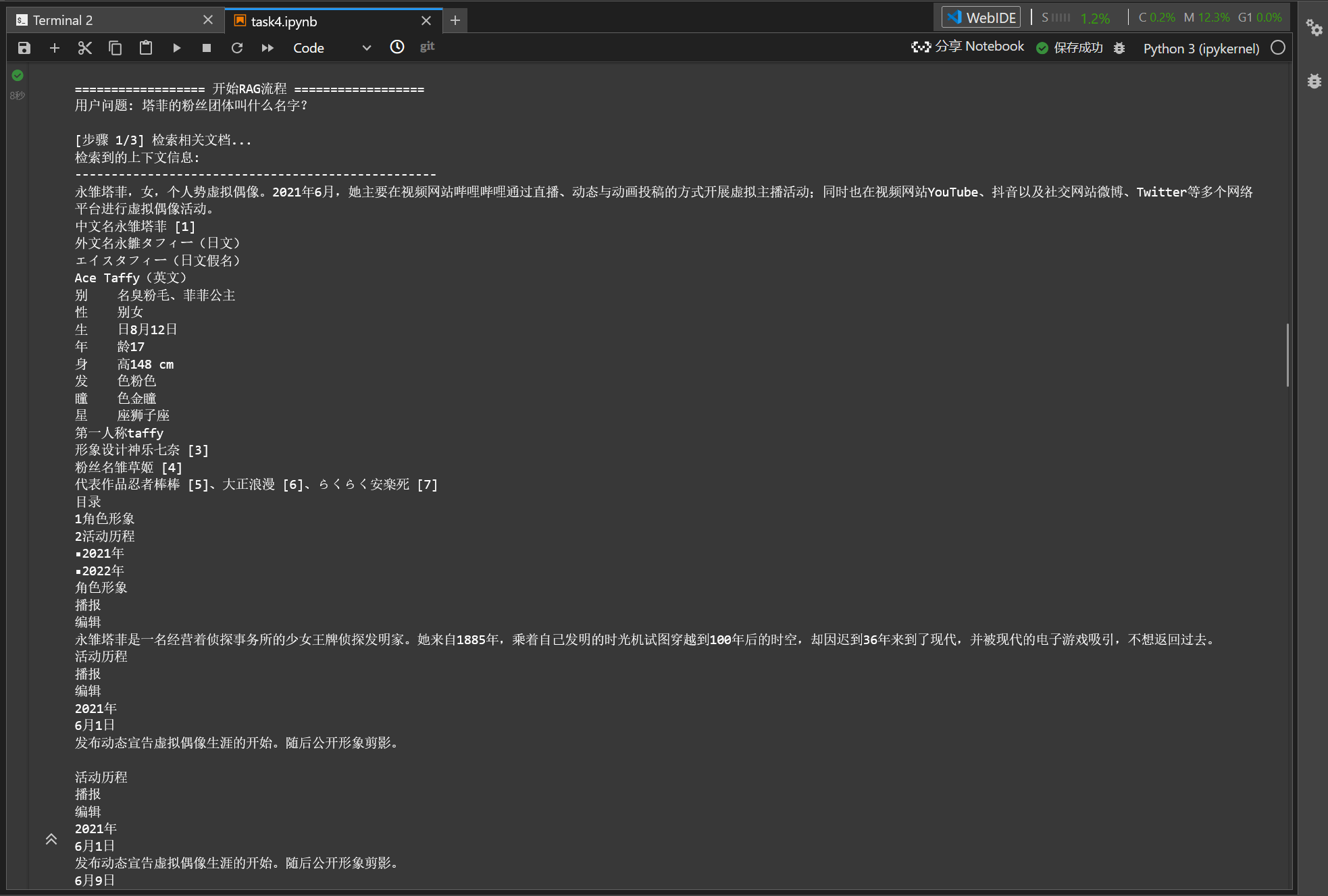
print(f"👤 用户: {user_prompt}")
if force_tool:
print("⚡️ [模式]: 强制调用 'calculator' 工具")
active_llm = llm_with_tools_forced
messages = [HumanMessage(content=user_prompt)]
try:
response_message = active_llm.invoke(messages)
except Exception as e:
print(f"\n[错误] 调用大模型时出错: {e}")
return
if response_message.tool_calls:
print("✅ LLM 决定调用工具...")
messages.append(response_message)
for tool_call in response_message.tool_calls:
function_name = tool_call["name"]
function_args = tool_call["args"]
print(f"📞 准备调用 API, 函数: {function_name}, 参数: {function_args}")
expression = function_args.get("expression")
try:
api_response = requests.post(CALCULATOR_API_URL, json={"expression": expression})
api_response.raise_for_status()
function_response = api_response.json().get('result')
except Exception as e:
function_response = f"Error: {e}"
print(f"⚙️ 工具返回结果: {function_response}")
messages.append(ToolMessage(content=function_response, tool_call_id=tool_call["id"]))
final_response = active_llm.invoke(messages)
final_answer = final_response.content
else:
print("✅ LLM 未调用工具,直接回答。")
final_answer = response_message.content
else:
print("🚫 [模式]: 不允许使用工具,仅让模型自行回答")
try:
response_message = llm.invoke([HumanMessage(content=user_prompt)])
final_answer = response_message.content
except Exception as e:
print(f"\n[错误] 调用大模型时出错: {e}")
return
print(f"\n🤖 {MODEL_NAME}: {final_answer}")
print("="*50 + "\n")
if __name__ == '__main__':
if 'server_thread' not in locals() or not server_thread.is_alive():
server_thread = threading.Thread(target=run_api_server, daemon=True)
server_thread.start()
print("--- 主程序启动,等待 API 服务器就绪 (2秒)... ---")
time.sleep(2)
print("--- API 服务器已就绪,开始执行对话任务 ---\n")
# 调用工具
run_conversation("我想知道 129032910921 * 188231 等于多少?", force_tool=True)
# 不调用工具
run_conversation("我想知道 129032910921 * 188231 等于多少?仅给出答案即可,不需要其他内容", force_tool=False)
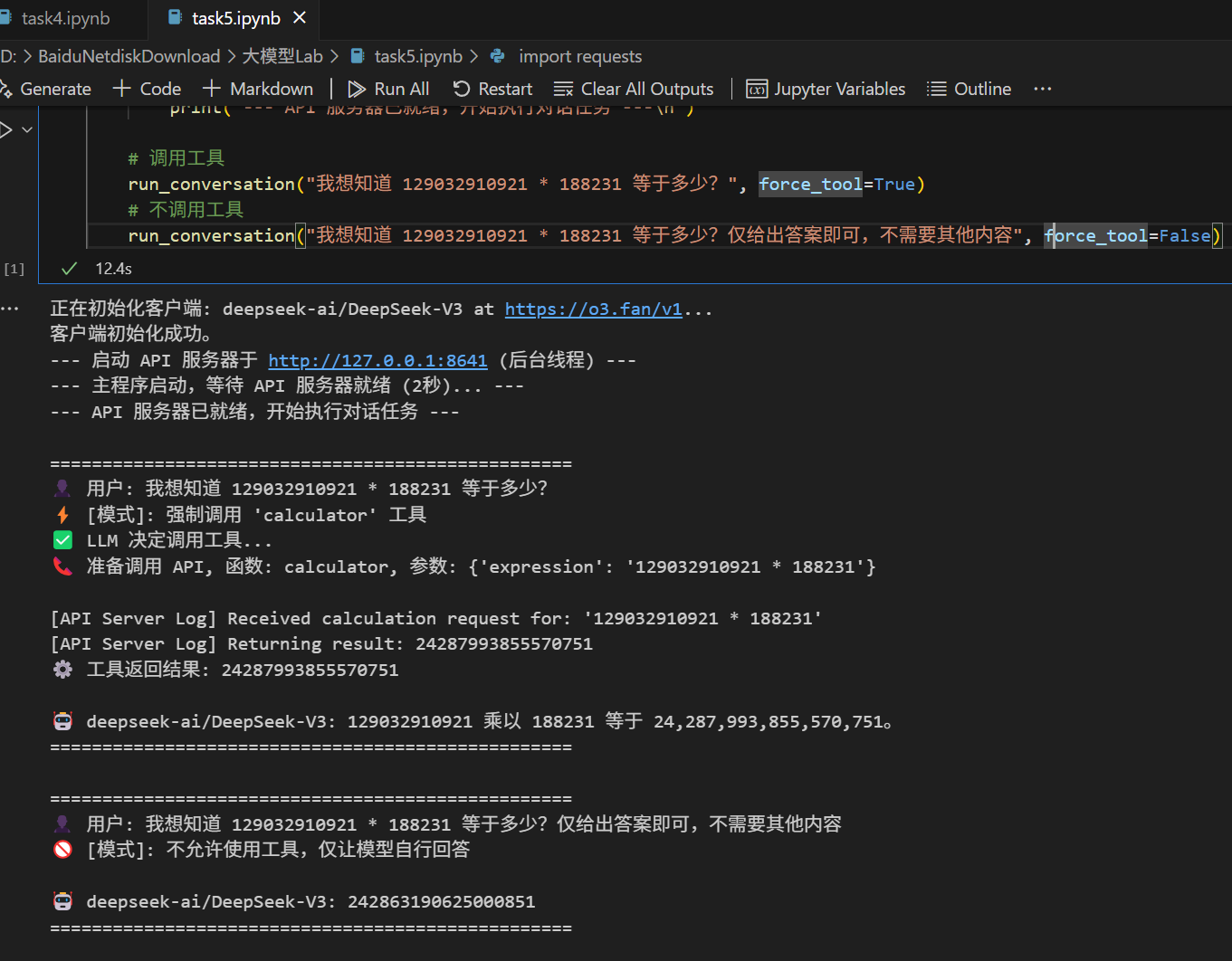
这里我们可以写个小脚本来算算值究竟是多少:
from decimal import Decimal, getcontext
# 设置小数计算精度,默认 100 位
getcontext().prec = 100
def multiply(a: str, b: str) -> str:
"""
输入两个字符串形式的数字,只支持乘法,返回字符串结果。
"""
try:
# 判断是否包含小数点
if "." in a or "." in b:
result = Decimal(a) * Decimal(b)
else:
result = int(a) * int(b)
return str(result)
except Exception as e:
return f"计算出错:{e}"
if __name__ == "__main__":
print(multiply("129032910921", "188231"))
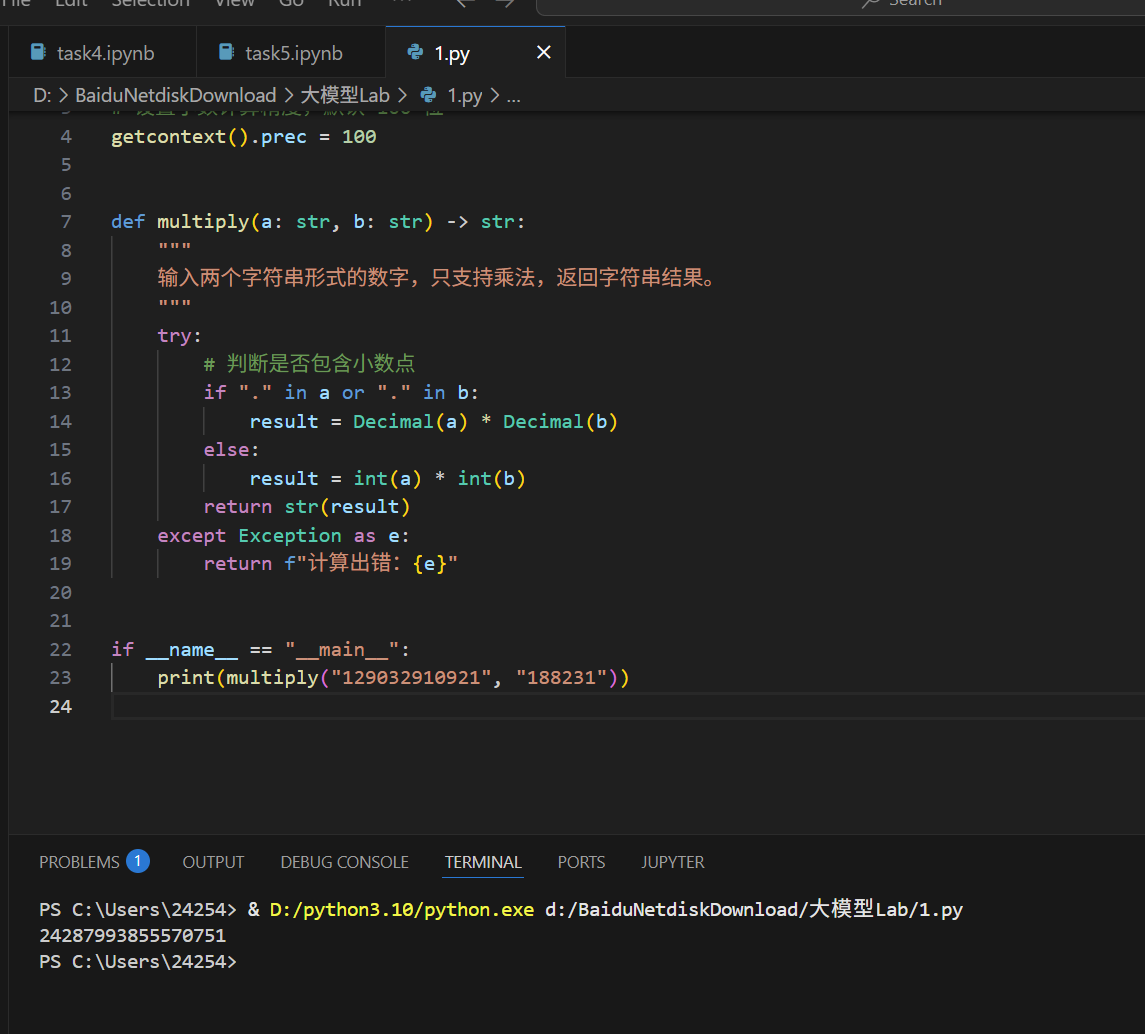
可以看出来结果应该是24287993855570751,调用工具的结果是对的,没调用工具的结果是llm乱说的。