这次正好轮到SU和Das合作,所以我这次也有机会去出题了,MISC的话我出了一道简单,Ge9ian出了两道,一道简单一道中等,本来好像是让Ge9ian出一个困难题的?最后好像被打成中等了,换别人出困难题了。
实际上我最初投稿的不是这道题,是一道中等题,和社工有关,涉及了当时过年期间看到的关于poi的一些有意思的东西,结果安恒不收社工题,最后只能随便出一道签到了,那个poi的题我就附在文章末尾吧。
预期解
当时是翻外网的时候翻到了一个工具叫做SSuitePicsel,号称是某种军用加密,非常难破解,用谷歌搜了一下发现没人拿这个工具出过题就拿来当签到题了。因为是当签到题,所以当时也没想让大家直接攻击这个加密算法的(没想到大部分人都攻破了,给大伙跪了),因此我直接把那个工具的描述摘抄了一段作为题目的描述了,所以直接谷歌题目描述的那段话是可以直接搜到这个工具的:
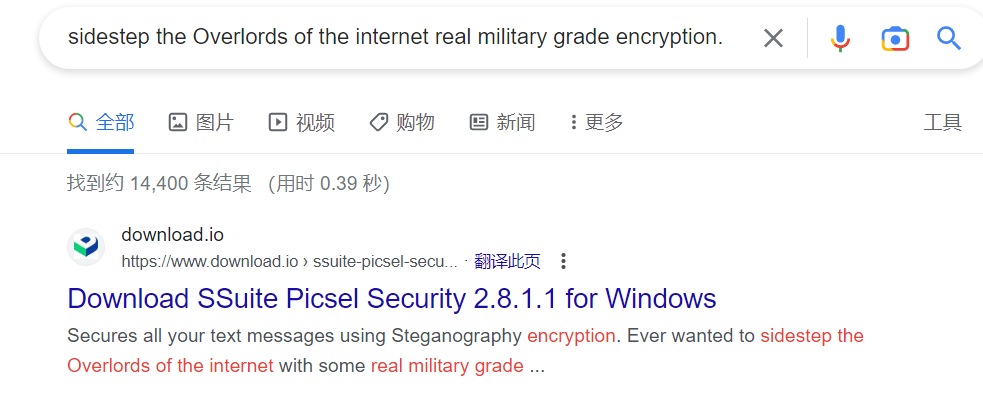
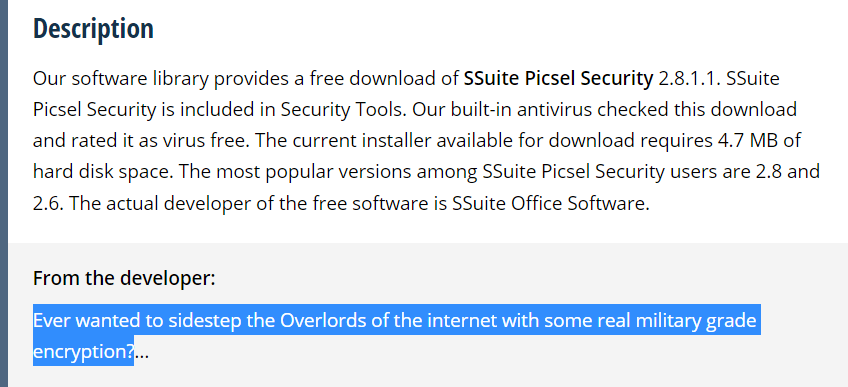
所以做法就很简单了,我给的那个附件后面很明显还跟着一张png图片:
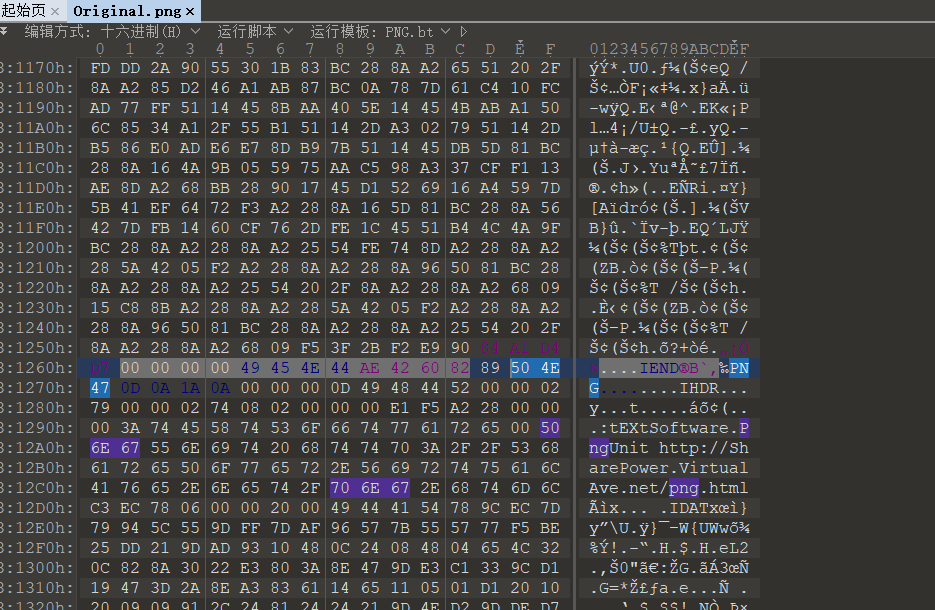
用foremost分离一下,可以得到两张图片
foremost -T Original_1.png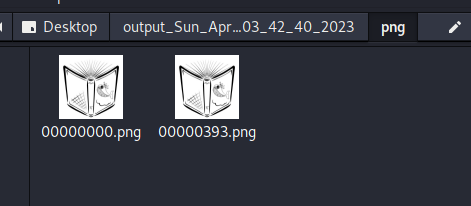
用小的那张作为原始图片,大的那张作为加密后的图片进行解密即可:
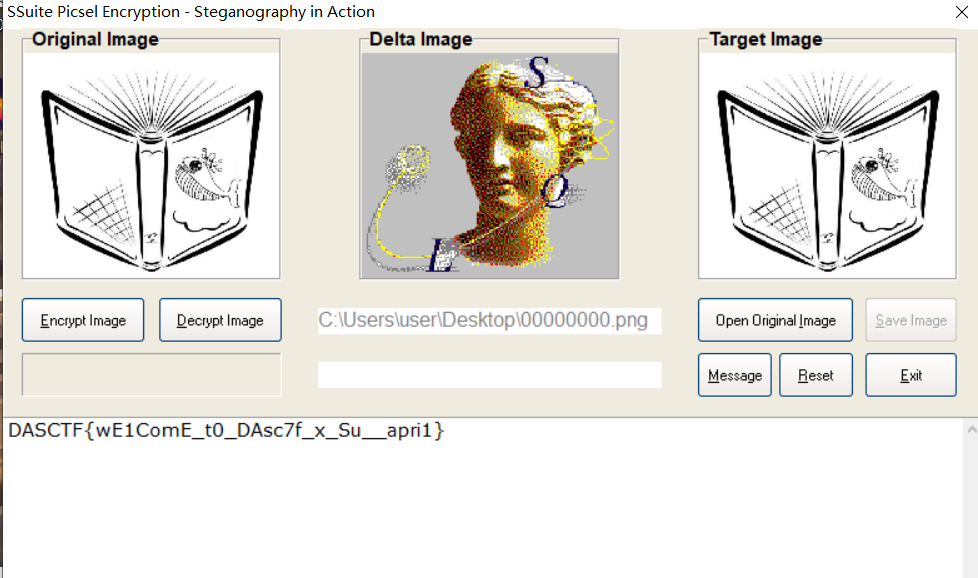
非预期解
事实上这个加密比较蠢,我们用stegsolve查看foremost分离出来的图片,其实这个工具是直接把数据异或了之后放在了红色通道最低位上
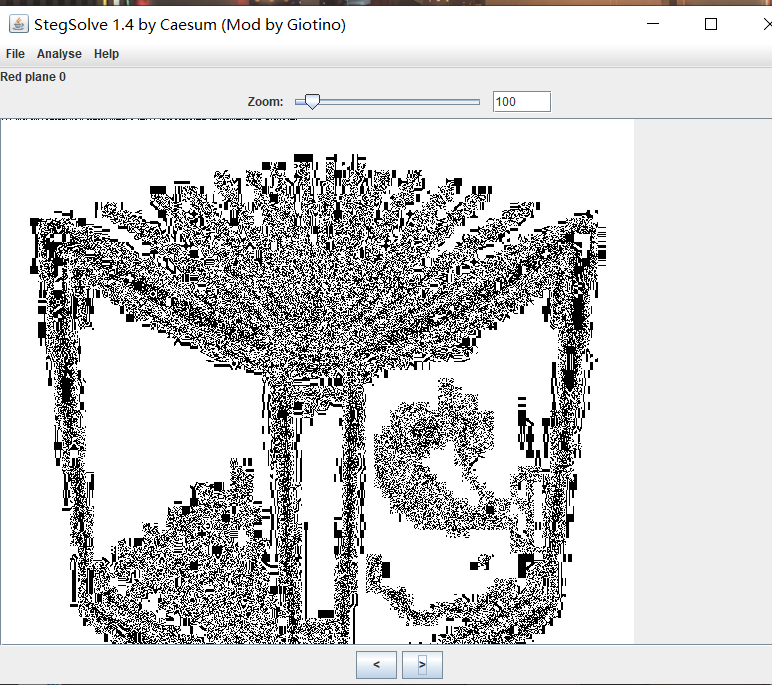
左上角就是和原图相比增加的数据,我们先把这个通道下的图片保存下来,再写个脚本把增加的数据提取出来:
from PIL import Image
import numpy as np
img = Image.open("solved.bmp")
img_array = np.array(img)
shape = img_array.shape
fh = open('output.txt', 'w')
print(img_array.shape)
for i in range(0, shape[0]):
res_1: str = ''
for j in range(0, shape[1]):
value = img_array[i, j]
# print("",value)
if (value == 255).any():
fh.write('1')
else:
fh.write('0')
我这个脚本提取了所有数据,我们这里只取前面需要的:
10111011101111101010110010111100101010111011100110000100100010001011101011001110101111001001000010010010101110101010000010001011110011111010000010111011101111101000110010011100110010001001100110100000100001111010000010101100100010101010000010100000100111101000111110001101100101101100111010000010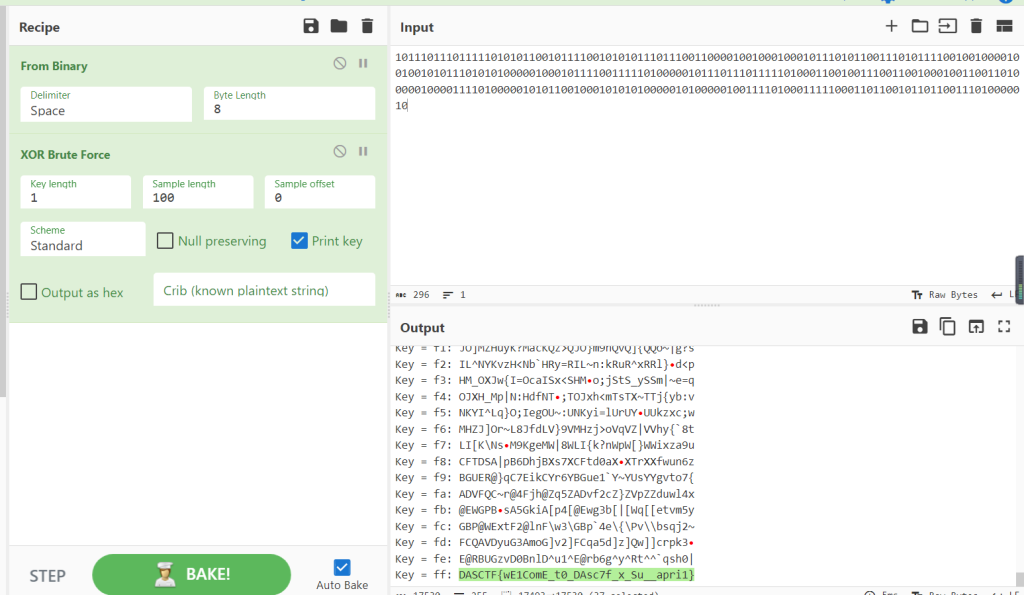
一些思考
其实利用SSuitePicsel隐写后的图片的特征让我想到了cloacked-pixel,cloacked-pixel隐写后的图片也是在红色通道最低位上增加加密后的数据:
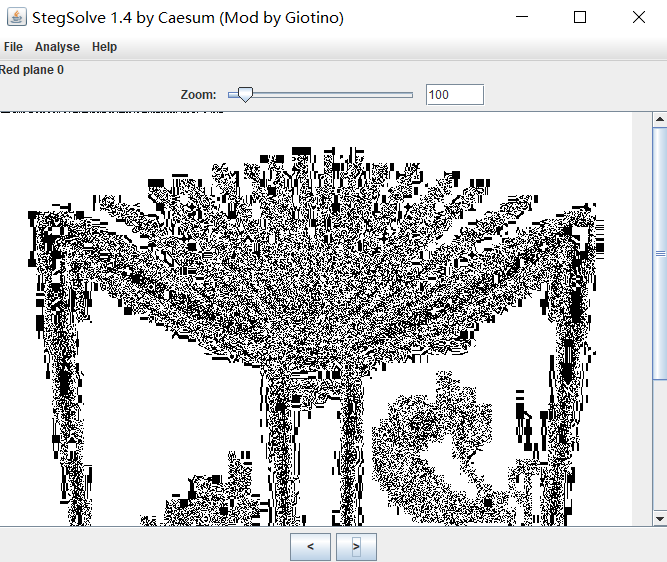
但把这个数据提取出来后进行简单的异或爆破是还原不了明文的,cloacked-pixel的源码里使用了AES作为加密算法:
import hashlib
from Crypto import Random
from Crypto.Cipher import AES
'''
Thanks to
http://stackoverflow.com/questions/12524994/encrypt-decrypt-using-pycrypto-aes-256
'''
class AESCipher:
def __init__(self, key):
self.bs = 32 # Block size
self.key = hashlib.sha256(key.encode()).digest() # 32 bit digest
def encrypt(self, raw):
raw = self._pad(raw)
iv = Random.new().read(AES.block_size)
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return iv + cipher.encrypt(raw)
def decrypt(self, enc):
iv = enc[:AES.block_size]
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return self._unpad(cipher.decrypt(enc[AES.block_size:]))
def _pad(self, s):
return s + (self.bs - len(s) % self.bs) * chr(self.bs - len(s) % self.bs)
@staticmethod
def _unpad(s):
return s[:-ord(s[len(s)-1:])]并且使用cloacked-pixel加密图片是必须要密码的,具体的加密操作为:
def embed(imgFile, payload, password):
# Process source image
img = Image.open(imgFile)
(width, height) = img.size
conv = img.convert("RGBA").getdata()
print "[*] Input image size: %dx%d pixels." % (width, height)
max_size = width*height*3.0/8/1024 # max payload size
print "[*] Usable payload size: %.2f KB." % (max_size)
f = open(payload, "rb")
data = f.read()
f.close()
print "[+] Payload size: %.3f KB " % (len(data)/1024.0)
# Encypt
cipher = AESCipher(password)
data_enc = cipher.encrypt(data)
# Process data from payload file
v = decompose(data_enc)
# Add until multiple of 3
while(len(v)%3):
v.append(0)
payload_size = len(v)/8/1024.0
print "[+] Encrypted payload size: %.3f KB " % (payload_size)
if (payload_size > max_size - 4):
print "[-] Cannot embed. File too large"
sys.exit()
# Create output image
steg_img = Image.new('RGBA',(width, height))
data_img = steg_img.getdata()
idx = 0
for h in range(height):
for w in range(width):
(r, g, b, a) = conv.getpixel((w, h))
if idx < len(v):
r = set_bit(r, 0, v[idx])
g = set_bit(g, 0, v[idx+1])
b = set_bit(b, 0, v[idx+2])
data_img.putpixel((w,h), (r, g, b, a))
idx = idx + 3
steg_img.save(imgFile + "-stego.png", "PNG")
print "[+] %s embedded successfully!" % payload这里直接使用了cipher = AESCipher(password),然后用cipher.encrypt(data)对数据进行了一次加密,因此在不知道密钥的情况下很难还原经过cloacked-pixel加密的图片隐藏的数据,也因此经常作为ctf里考察的工具,基本上ctf里遇到的有lsb的png图片都是cloacked-pixel(至少我遇到的都是)。
每个月的安恒月赛也算大比赛了,大一打的时候基本上都是在坐牢,这次有机会出题本来也是想考个大家没见过的东西,一个图片分离出两张一样图片,看起来是盲水印但其实不是;带lsb的png图片,看起来是cloacked-pixel其实也不是,只不过可能这个工具的加密算法比较蠢,被大伙都攻破了,赛后我去研究了一下SSuitePicsel的加密,虽然不知道源码是啥,试了几次最后都是用ff就异或出明文了,可能它的加密就这样吧,其实也侧面起到了它原有的作用,因为比赛里做出来的几个队都不是搜简介找工具做的,要真出个什么很复杂的加密估计我赛后早被骂成傻逼了🤡这次也算是让带伙试了试怎么攻破美国军用加密算法了😂
某道废题
题目名称:DAS4—ez_poi
题目类型:MISC
题目分数:200
题目难度:中等
题目Flag:贵州省贵阳市南明区玉厂路279号
题目标签: 个人信息搜集
题目描述: 都什么年代了,还在玩传统社工!据说离这家药店最近也有一百一十多米才有一家银行,flag提交的内容为该药店在百度地图上的详细地址,如:DASCTF{湖北省咸宁市通城县湘汉路13号}
题目附件:

最初Au5t1n找我们征题的时候我问他社工题行不他说可以,没想到辛苦等了一个月等到审批的时候却被打退了

出题的思路是过年期间刷抖音的时候看到了一个短视频:
里面讲了一个很有意思的社工技巧,用poi检索找位置。简单讲讲什么是poi:
POI是“Point of Interest”的缩写,中文可以翻译为“兴趣点”。在地理信息系统中,一个POI可以是一栋房子、一个商铺、一个邮筒、一个公交站等。
传统的地理信息采集方法需要地图测绘人员采用精密的测绘仪器去获取一个信息点的经纬度,然后再标记下来。正因为POI的采集是一个非常费时费事的工作,对一个地理信息系统来说,POI的数量在一定程度代表着整个系统的价值。
每个POI包含四方面信息,名称、类别、坐标、分类,全面的POI讯息是丰富导航地图的必备资讯,及时的POI信息点能提醒用户路况的分支及周边建筑的详尽信息,也能方便导航中查到你所需要的各个地方,选择最为便捷和通畅的道路来进行路径规划,因此,导航地图POI多少状况直接影响到导航的好用程度,世界各大的地图公司都有属于自己的poi数据库。
当然这里我们其实不需要记那么多复杂的概念,只需要清楚一个概念,就是请求地图软件的poi数据是可以拿到每个poi点的经纬度位置的。
那个视频里是一个特殊的情景:

图片里车牌什么的都看不清,最清楚的信息就是可以看见道路左边有一家好客连锁,然后好客连锁旁边有一家银行。在地图软件上搜索好客连锁,可以找到几百家,基本上人力很难解决,有个网友从早上九点干到凌晨也只是勉强确认拍摄地点可能在广东。而唯一找到答案的大神使用的方法便是使用了查询poi数据库的方法解决的,很简单,先调用poi查询所有好客连锁的经纬度,再查询所有银行的经纬度,再写个脚本通过经纬度计算二者之间的距离,距离大概二十米之内的就是目标,跑完数据之后只用查两三个满足目标的地点的百度街景即可。
这种用现代化科技解决问题的思想还是蛮有趣的,因为我之前打的ctf里的社工题基本上都是让你一个一个嗯找,而有了这种方法只要你知道哪怕两个模糊的信息,比如银行旁边有家超市,也能很轻松的找到满足条件的地点。
因此我设计了一道基本上人力不可能解决的题目,图片里清晰的信息只有一家药店,叫做一品药业,还有一个信息就是最近也有一百一十多米才有一家银行,刚好符合我们上面那个条件,两个模糊的信息即可定位。为什么说人力不可能完成,我们可以在百度地图上搜索一品药业:
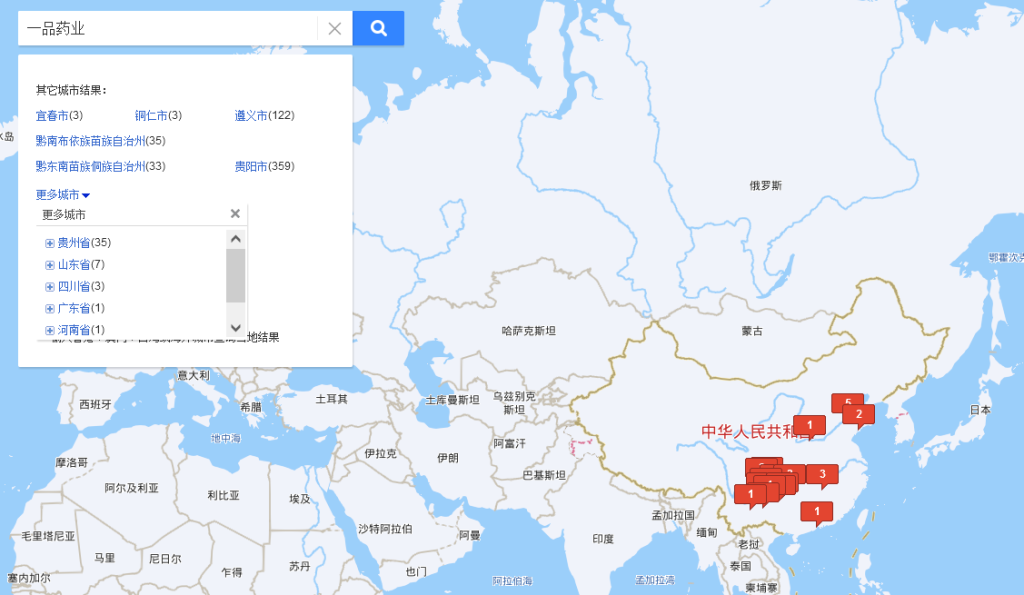
地图上有超过五百家一品药业,你再卷也不太可能在比赛的八个小时里找完(当然如果你八个小时一直找或者几个人一起找还是有可能找到的),当然,为了确保人力不可完成,我找我学弟前前后后测了几次题,前几次我自以为很难找的地方还是被他排查出来,直到这个地点基本上没啥信息才终于让他折戟而归。
所以解题的思路就很简单了,先通过查poi拿一品药业的经纬度,再拿银行的经纬度,最后写个脚本计算二者之间的距离,大概距离一百一十多米的话就是我们可能的目标。我使用的查询poi数据的工具就是视频里的EasyPoi,因为调用poi数据需要去申请百度的开发者配额获得API KEY,而且搜索配额比较少,所以我当时测试题的时候直接购买了开发者的神秘码,大概48元可以用两天,使用神秘码可以租用包月企业的poi端口进行爬取,搜索配额不限制,而且可以多人使用,所以当时想的是比赛的时候可以考虑提前买一个给师傅们使用:
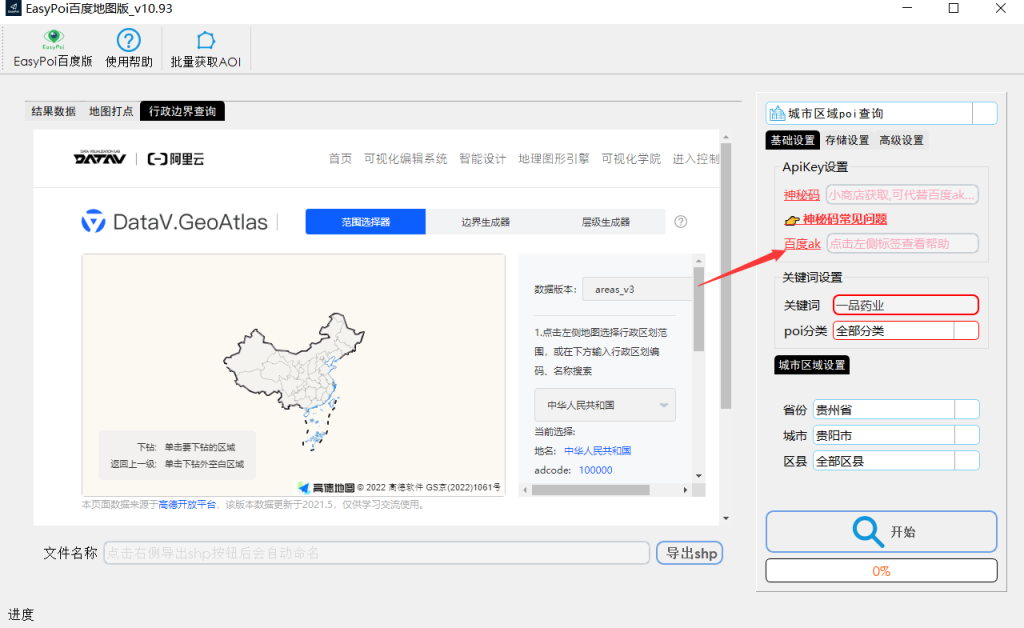
贵州的一品药业最多,我们可以从贵州开始查询,因为程序可以多开,我当时同时开两个EasyPoi,一个查询贵州的一品药业的poi数据,另一个查询贵州银行的poi数据,大概半个小时之内就能跑完:
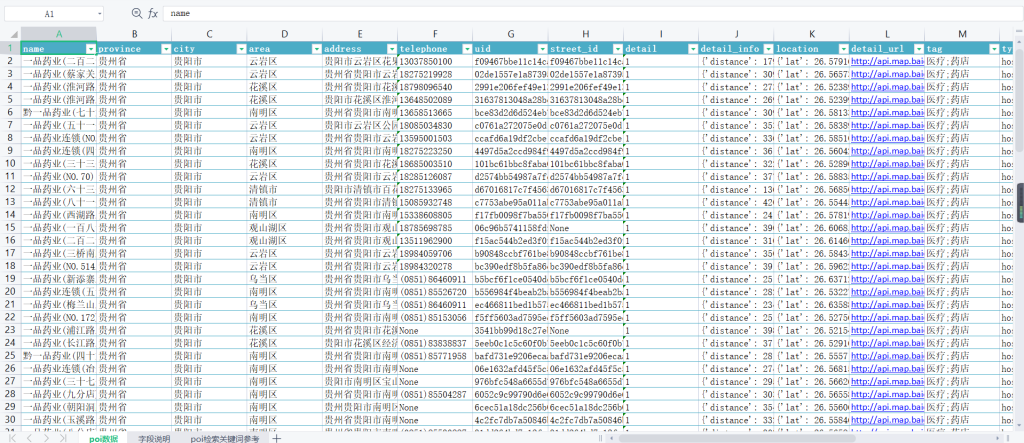
然后找胡杨帮忙写了个计算距离并排序的脚本:
import xlrd
import math
# 计算两个经纬度之间的距离
def calc_distance(lat1, lon1, lat2, lon2):
# 计算两个经纬度之间的距离
# 公式参考:https://blog.csdn.net/jia20003/article/details/85214755
EARTH_RADIUS = 6378.137 # 地球半径
rad_lat1 = math.radians(lat1)
rad_lat2 = math.radians(lat2)
delta_lat = math.radians(lat2 - lat1)
delta_lon = math.radians(lon2 - lon1)
a = math.sin(delta_lat / 2) * math.sin(delta_lat / 2) + math.cos(rad_lat1) * math.cos(rad_lat2) * math.sin(
delta_lon / 2) * math.sin(delta_lon / 2)
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
distance = EARTH_RADIUS * c
return distance
# 读取excel中的经纬度信息
def read_excel(file_name):
# 打开Excel文件
workbook = xlrd.open_workbook(file_name)
# 获取所有sheet
#sheet_name = workbook.sheet_names()
# 根据sheet索引或者名称获取sheet内容
sheet = workbook.sheet_by_name('poi数据')
# 获取行数和列数
rows = sheet.nrows
cols = sheet.ncols
# 读取经纬度信息
data = []
for i in range(rows):
row_data = sheet.row_values(i)
data.append(row_data)
return data
# 计算excel中所有经纬度之间的距离
def calc_all_distance(data,data2):
#计算excel中所有经纬度之间的距离
min_distance=999999
min_list=[]
for i in range(1,len(data2)):
for j in range(1,len(data)):
# 获取两个经纬度
lat1 = float(data2[i][17])
lon1 = float(data2[i][16])
lat2 = float(data[j][17])
lon2 = float(data[j][16])
# 计算距离
distance = calc_distance(lat1, lon1, lat2, lon2)
if distance < min_distance:
min_distance=distance
min_name1=data[j][0]
min_name2=data2[i][0]
list_data = [min_name2, min_name1, min_distance]
min_distance=999999
min_list.append(list_data)
sorted_list = sorted(min_list, key=lambda x: x[2])
for k in range(len(sorted_list)):
print('['+str(k)+']'+sorted_list[k][0]+'和'+sorted_list[k][1]+'两点之间的距离:'+str(sorted_list[k][2]*1000)+' m')
if __name__ == '__main__':
# 读取excel中的经纬度信息
data = read_excel('银行.xlsx')
data2 = read_excel('一品药业.xlsx')
# 计算excel中所有经纬度之间的距离
calc_all_distance(data,data2)十秒钟之内就能跑出来:
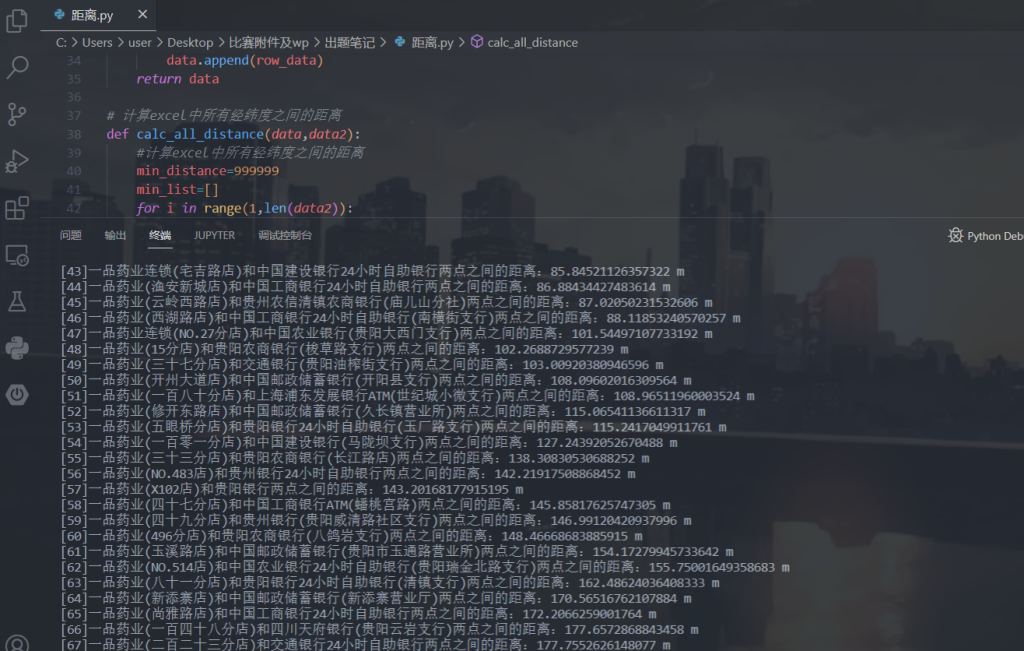
所以我们现在需要排查110米左右有家银行的一品药业即可,最后在53条也就是第二个满足条件的一品药业——一品药业(五眼桥分店)找到正确的百度街景:

所以最后的答案就是:DASCTF{贵州省贵阳市南明区玉厂路279号}
都什么年代了,还在玩传统社工!
学长是不是忘了放那个poi的题啦